1.使用K近邻算法改进约会网站的配对效果
1.1准备数据
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 from numpy import * 4 5 def file2matrix(filename): 6 ‘‘‘ 7 将文本格式转化为Numpy 8 :param filename: 需要处理的文本文件 9 :return: 转化格式后的文本和标签 10 ‘‘‘ 11 fr = open(filename) 12 numberOfLines = len(fr.readlines()) 13 returnMat = zeros((numberOfLines, 3)) # 数据的前三列用于分类 14 classLabelVector = [] 15 fr = open(filename) 16 index = 0 17 for line in fr.readlines(): 18 line = line.strip() # line.strip()截取掉所有的回车符 19 listFromLine = line.split(‘\t‘) # 将整行数据分割成一个元素列表 20 returnMat[index, :] = listFromLine[0:3] 21 classLabelVector.append(int(listFromLine[-1])) 22 index += 1 23 return returnMat, classLabelVector 24 25 if __name__==‘__main__‘: 26 datingDataMat,datingLabels=file2matrix(‘datingTestSet2.txt‘) 27 print datingDataMat 28 print datingLabels
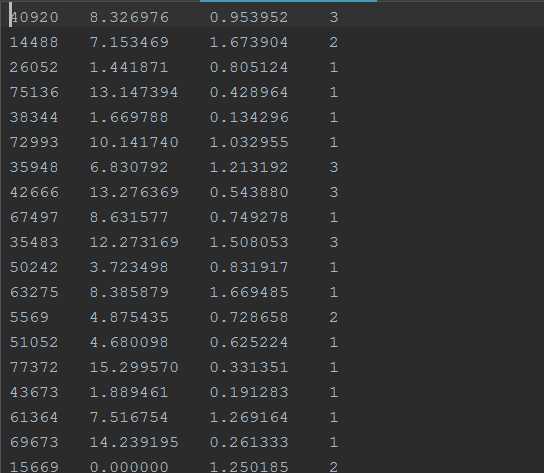
处理后的数据效果为:
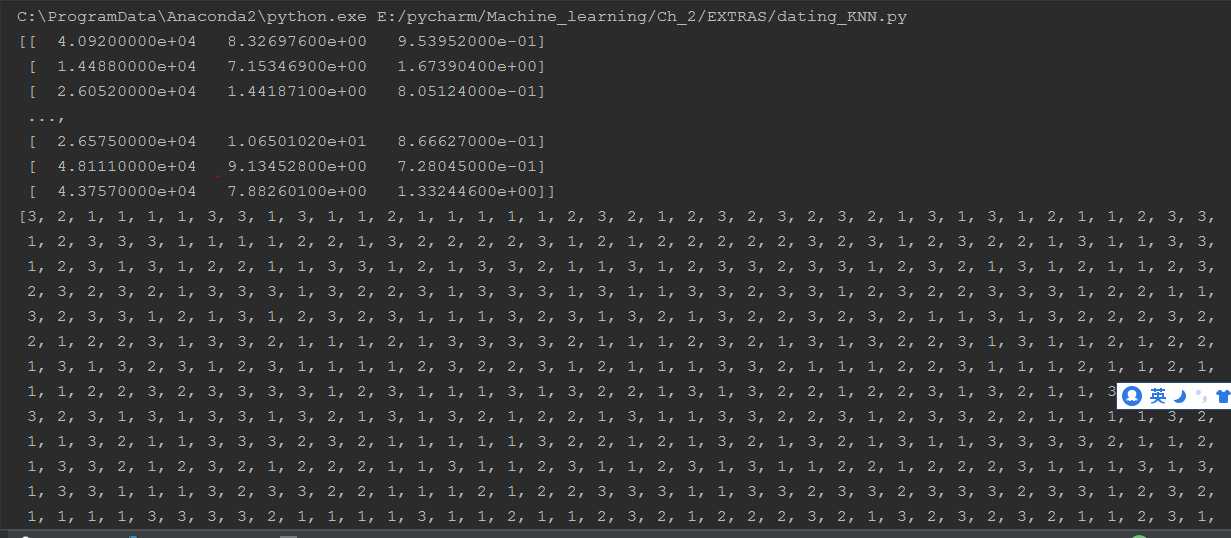
原始数据:
1.2测试算法,作为完整程序验证分类器
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 from numpy import * 4 import operator 5 6 7 def file2matrix(filename): 8 ‘‘‘ 9 将文本格式转化为Numpy 10 :param filename: 需要处理的文本文件 11 :return: 转化格式后的文本和标签 12 ‘‘‘ 13 fr = open(filename) 14 numberOfLines = len(fr.readlines()) 15 returnMat = zeros((numberOfLines, 3)) # 数据的前三列用于分类 16 classLabelVector = [] 17 fr = open(filename) 18 index = 0 19 for line in fr.readlines(): 20 line = line.strip() # line.strip()截取掉所有的回车符 21 listFromLine = line.split(‘\t‘) # 将整行数据分割成一个元素列表 22 returnMat[index, :] = listFromLine[0:3] 23 classLabelVector.append(int(listFromLine[-1])) 24 index += 1 25 return returnMat, classLabelVector 26 27 28 def autoNorm(dataSet): 29 ‘‘‘ 30 归一化特征值 31 :param dataSet: 32 :return: 33 ‘‘‘ 34 minVals = dataSet.min(0) # 存放每列中的最小值,一行三列的形式 35 maxVals = dataSet.max(0) # 存放每列中的最大值,一行三列的形式 36 ranges = maxVals - minVals 37 normDataSet = zeros(shape(dataSet)) # 1000行3列 38 m = dataSet.shape[0] # m=1000 39 normDataSet = dataSet - tile(minVals, (m,1)) # tile将minVals复制成为1000行3列的形式 40 normDataSet = normDataSet/tile(ranges, (m,1)) # 归一化后的所有数据 41 return normDataSet, ranges, minVals 42 43 44 def classify0(inX, dataSet, labels, k): 45 ‘‘‘ 46 K 近邻算法 47 :param inX: 用于分类的输入向量 48 :param dataSet: 输入的训练样本集 49 :param labels: 标签向量 50 :param k: 选择最近邻的数目 51 :return: 52 ‘‘‘ 53 dataSetSize = dataSet.shape[0] 54 diffMat = tile(inX, (dataSetSize,1)) - dataSet # 测试数据转化成训练数据的格式后相减 55 sqDiffMat = diffMat**2 56 sqDistances = sqDiffMat.sum(axis=1) 57 distances = sqDistances**0.5 58 sortedDistIndicies = distances.argsort() #argsort()根据元素的值从小到大对元素进行排序,返回下标 59 classCount={} 60 for i in range(k): # 将字典分解为元组列表 61 voteIlabel = labels[sortedDistIndicies[i]] # 获取前K个最小距离元素的下标作为主要分类 62 classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 63 sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True) 64 # operator.itemgetter() 获取对象的第几个域的特征 65 return sortedClassCount[0][0] 66 67 68 def datingClassTest(): 69 ‘‘‘ 70 分类器对于约会网站的测试代码 71 :return: 72 ‘‘‘ 73 hoRatio = 0.1 #hold out 10% 74 datingDataMat,datingLabels = file2matrix(‘datingTestSet2.txt‘) 75 normMat, ranges, minVals = autoNorm(datingDataMat) # norMat归一化后的特征向量,range值域,minvals每列的最小值 76 m = normMat.shape[0] # 数据的行数 77 numTestVecs = int(m*hoRatio) # 作为测试数据的个数 78 errorCount = 0.0 79 for i in range(numTestVecs): 80 classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3) 81 print ("分类器返回的标签为: %d, 实际的标签为: %d" % (classifierResult, datingLabels[i])) 82 if (classifierResult != datingLabels[i]): errorCount += 1.0 83 print ("整体的错误率为: %f" % (errorCount/float(numTestVecs))) 84 print (errorCount) 85 86 87 88 if __name__==‘__main__‘: 89 datingClassTest();
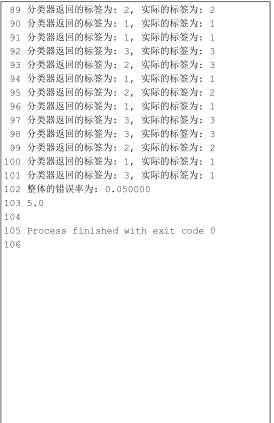
运行结果

1.3 利用K-近邻算法实现手写体识别
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 from numpy import * 4 import operator 5 from os import listdir # 列出给定目录的文件名 6 7 def img2vector(filename): 8 ‘‘‘ 9 把一个32X32的图像矩阵转化为一个1X1024的向量 10 :param filename: 11 :return: 12 ‘‘‘ 13 returnVect = zeros((1,1024)) 14 fr = open(filename) 15 for i in range(32): 16 lineStr = fr.readline() 17 for j in range(32): 18 returnVect[0,32*i+j] = int(lineStr[j]) 19 return returnVect 20 21 22 def autoNorm(dataSet): 23 ‘‘‘ 24 归一化特征值 25 :param dataSet: 26 :return: 27 ‘‘‘ 28 minVals = dataSet.min(0) # 存放每列中的最小值,一行三列的形式 29 maxVals = dataSet.max(0) # 存放每列中的最大值,一行三列的形式 30 ranges = maxVals - minVals 31 normDataSet = zeros(shape(dataSet)) # 1000行3列 32 m = dataSet.shape[0] # m=1000 33 normDataSet = dataSet - tile(minVals, (m,1)) # tile将minVals复制成为1000行3列的形式 34 normDataSet = normDataSet/tile(ranges, (m,1)) # 归一化后的所有数据 35 return normDataSet, ranges, minVals 36 37 38 def classify0(inX, dataSet, labels, k): 39 ‘‘‘ 40 K 近邻算法 41 :param inX: 用于分类的输入向量 42 :param dataSet: 输入的训练样本集 43 :param labels: 标签向量 44 :param k: 选择最近邻的数目 45 :return: 46 ‘‘‘ 47 dataSetSize = dataSet.shape[0] 48 diffMat = tile(inX, (dataSetSize,1)) - dataSet # 测试数据转化成训练数据的格式后相减 49 sqDiffMat = diffMat**2 50 sqDistances = sqDiffMat.sum(axis=1) 51 distances = sqDistances**0.5 52 sortedDistIndicies = distances.argsort() #argsort()根据元素的值从小到大对元素进行排序,返回下标 53 classCount={} 54 for i in range(k): # 将字典分解为元组列表 55 voteIlabel = labels[sortedDistIndicies[i]] # 获取前K个最小距离元素的下标作为主要分类 56 classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 57 sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True) 58 # operator.itemgetter() 获取对象的第几个域的特征 59 return sortedClassCount[0][0] 60 61 62 def handwritingClassTest(): 63 hwLabels = [] 64 trainingFileList = listdir(‘trainingDigits‘) 65 m = len(trainingFileList) 66 trainingMat = zeros((m,1024)) 67 for i in range(m): 68 fileNameStr = trainingFileList[i] 69 fileStr = fileNameStr.split(‘.‘)[0] #take off .txt 70 classNumStr = int(fileStr.split(‘_‘)[0]) 71 hwLabels.append(classNumStr) 72 trainingMat[i,:] = img2vector(‘trainingDigits/%s‘ % fileNameStr) 73 testFileList = listdir(‘testDigits‘) 74 errorCount = 0.0 75 mTest = len(testFileList) 76 for i in range(mTest): 77 fileNameStr = testFileList[i] 78 fileStr = fileNameStr.split(‘.‘)[0] 79 classNumStr = int(fileStr.split(‘_‘)[0]) 80 vectorUnderTest = img2vector(‘testDigits/%s‘ % fileNameStr) 81 classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3) 82 print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr) 83 if (classifierResult != classNumStr): errorCount += 1.0 84 print "\nthe total number of errors is: %d" % errorCount 85 print "\nthe total error rate is: %f" % (errorCount/float(mTest)) 86 87 88 if __name__==‘__main__‘: 89 handwritingClassTest()