1:网站点击流数据分析项目推荐书籍:
可以看看百度如何实现这个功能的:https://tongji.baidu.com/web/welcome/login
1 网站点击流数据分析,业务知识,推荐书籍: 2 《网站分析实战——如何以数据驱动决策,提升网站价值》王彦平,吴盛锋编著 http://download.csdn.net/download/biexiansheng/10160197
2:整体技术流程及架构:
2.1 数据处理流程
该项目是一个纯粹的数据分析项目,其整体流程基本上就是依据数据的处理流程进行,依此有以下几个大的步骤:
(1):数据采集
首先,通过页面嵌入JS代码的方式获取用户访问行为,并发送到web服务的后台记录日志(假设已经获取到数据); 然后,将各服务器上生成的点击流日志通过实时或批量的方式汇聚到HDFS文件系统中 ,当然,一个综合分析系统,数据源可能不仅包含点击流数据,还有数据库中的业务数据(如用户信息、商品信息、订单信息等)及对分析有益的外部数据。
(2):数据预处理
通过mapreduce程序对采集到的点击流数据进行预处理,比如清洗,格式整理,滤除脏数据等;形成明细表,即宽表,多个表,以空间换时间。
(3):数据入库
将预处理之后的数据导入到HIVE仓库中相应的库和表中;
(4):数据分析
项目的核心内容,即根据需求开发ETL分析语句,得出各种统计结果;
(5):数据展现
将分析所得数据进行可视化;
2.2 项目结构:
由于本项目是一个纯粹数据分析项目,其整体结构亦跟分析流程匹配,并没有特别复杂的结构,如下图:
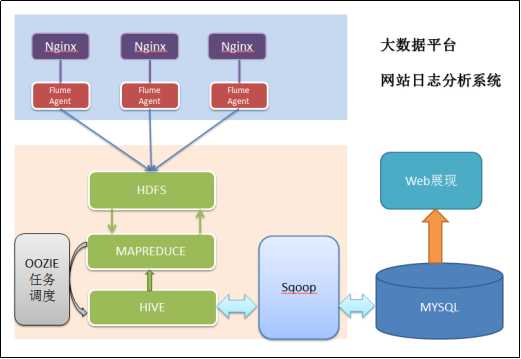
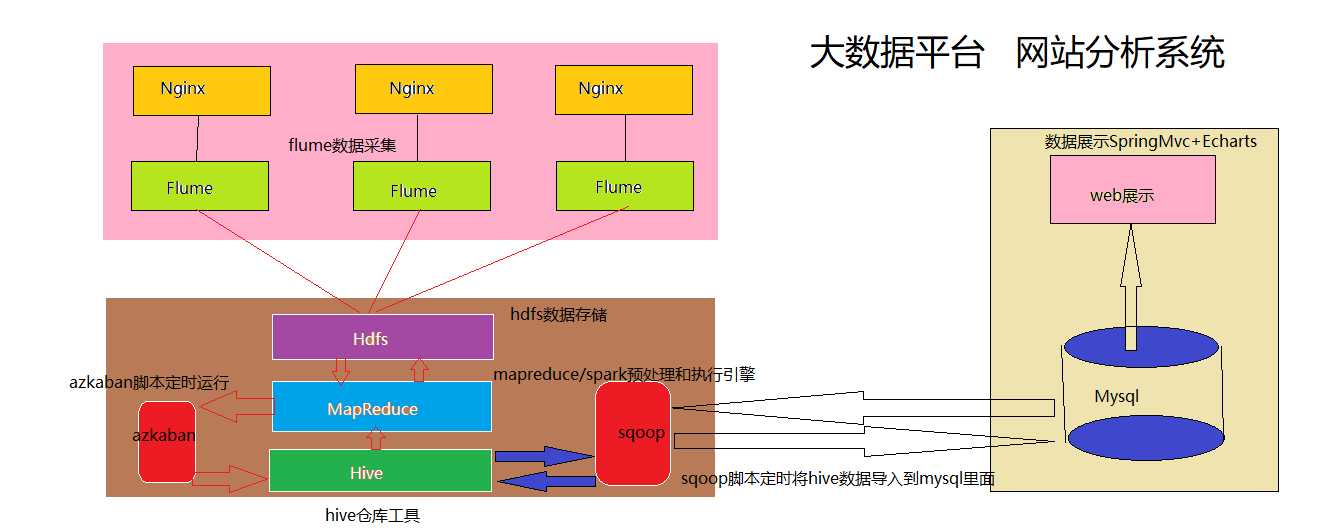
其中,需要强调的是:
系统的数据分析不是一次性的,而是按照一定的时间频率反复计算,因而整个处理链条中的各个环节需要按照一定的先后依赖关系紧密衔接,即涉及到大量任务单元的管理调度,所以,项目中需要添加一个任务调度模块
2.3 数据展现
数据展现的目的是将分析所得的数据进行可视化,以便运营决策人员能更方便地获取数据,更快更简单地理解数据;
3:模块开发——数据采集
3.1 需求
数据采集的需求广义上来说分为两大部分。
1)是在页面采集用户的访问行为,具体开发工作:
a、开发页面埋点js,采集用户访问行为
b、后台接受页面js请求记录日志,此部分工作也可以归属为“数据源”,其开发工作通常由web开发团队负责
2)是从web服务器上汇聚日志到HDFS,是数据分析系统的数据采集,此部分工作由数据分析平台建设团队负责,具体的技术实现有很多方式:
Shell脚本
优点:轻量级,开发简单
缺点:对日志采集过程中的容错处理不便控制
Java采集程序
优点:可对采集过程实现精细控制
缺点:开发工作量大
Flume日志采集框架
成熟的开源日志采集系统,且本身就是hadoop生态体系中的一员,与hadoop体系中的各种框架组件具有天生的亲和力,可扩展性强
3.2 技术选型
在点击流日志分析这种场景中,对数据采集部分的可靠性、容错能力要求通常不会非常严苛,因此使用通用的flume日志采集框架完全可以满足需求。
本项目即使用flume来实现日志采集。
3.3 Flume日志采集系统搭建
a、数据源信息
本项目分析的数据用nginx服务器所生成的流量日志,存放在各台nginx服务器上,省略。
b、数据内容样例
数据的具体内容在采集阶段其实不用太关心。
1 字段解析: 2 1、访客ip地址: 58.215.204.118 3 2、访客用户信息: - - 4 3、请求时间:[18/Sep/2013:06:51:35 +0000] 5 4、请求方式:GET 6 5、请求的url:/wp-includes/js/jquery/jquery.js?ver=1.10.2 7 6、请求所用协议:HTTP/1.1 8 7、响应码:304 9 8、返回的数据流量:0 10 9、访客的来源url:http://blog.fens.me/nodejs-socketio-chat/ 11 10、访客所用浏览器:Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0
开始实际操作,现学现卖,使用flume采集数据如下所示:
由于是直接使用现成的数据,所以省略获取原始数据的操作:
《默认hadoop,fLume,hive,azkaban,mysql等工具全部安装完成,配置完成,必须的都配置完成》 第一步:假设已经获取到数据,这里使用已经获取到的数据,如果你学习过此套课程,知道此数据文件名称为access.log.fensi,这里修改为access.log文件名称; 第二步:获取到数据以后就可以使用Flume日志采集系统采集数据。 第三步:采集规则配置详情,如下所示 fLume的文件名称如:tail-hdfs.conf 用tail命令获取数据,下沉到hdfs,将数据存放到hdfs上面. 启动命令: bin/flume-ng agent -c conf -f conf/tail-hdfs.conf -n a1 ######## # Name the components on this agent # 定义这个agent中各组件的名字,给那三个组件sources,sinks,channels取个名字,是一个逻辑代号: # a1是agent的代表。 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source 描述和配置source组件:r1 类型, 从网络端口接收数据,在本机启动, 所以localhost, type=exec采集目录源,目录里有就采 # exec用来执行要执行的命令 a1.sources.r1.type = exec # -F根据文件名称来追踪,采集文件的路径及其文件名称. a1.sources.r1.command = tail -F /home/hadoop/log/test.log a1.sources.r1.channels = c1 # Describe the sink 描述和配置sink组件:k1 # type,下沉类型,使用hdfs,将数据下沉到hdfs分布式文件系统里面。 a1.sinks.k1.type = hdfs a1.sinks.k1.channel = c1 # 下沉的路径,flume会进行格式的替换. a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/ # 文件的前缀 a1.sinks.k1.hdfs.filePrefix = events- # 10分钟修改一个新的目录. a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = minute # 3秒种滚动一次.可以方便查看效果,文件滚动周期默认30秒 a1.sinks.k1.hdfs.rollInterval = 3 # 文件滚动的大小限制,500字节滚动一次. a1.sinks.k1.hdfs.rollSize = 500 # 多少个事件,写入多少个event数据后滚动文件即事件个数. a1.sinks.k1.hdfs.rollCount = 20 # 多少个事件写一次 a1.sinks.k1.hdfs.batchSize = 5 # 是否从本地获取时间useLocalTimeStamp a1.sinks.k1.hdfs.useLocalTimeStamp = true # 生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本 a1.sinks.k1.hdfs.fileType = DataStream # Use a channel which buffers events in memory # 描述和配置channel组件,此处使用是内存缓存的方式 # type类型是内存memory。 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel # 描述和配置source channel sink之间的连接关系 # 将sources和sinks绑定到channel上面。 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
具体操作如下所示:
1 [root@master soft]# cd flume/conf/ 2 [root@master conf]# ls 3 flume-conf.properties.template flume-env.ps1.template flume-env.sh flume-env.sh.template log4j.properties 4 [root@master conf]# vim tail-hdfs.conf
内容如下所示:
1 # Name the components on this agent 2 a1.sources = r1 3 a1.sinks = k1 4 a1.channels = c1 5 6 # Describe/configure the source 7 a1.sources.r1.type = exec 8 a1.sources.r1.command = tail -F /home/hadoop/data_hadoop/access.log 9 a1.sources.r1.channels = c1 10 11 # Describe the sink 12 a1.sinks.k1.type = hdfs 13 a1.sinks.k1.channel = c1 14 a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/ 15 a1.sinks.k1.hdfs.filePrefix = events- 16 a1.sinks.k1.hdfs.round = true 17 a1.sinks.k1.hdfs.roundValue = 10 18 a1.sinks.k1.hdfs.roundUnit = minute 19 a1.sinks.k1.hdfs.rollInterval = 3 20 a1.sinks.k1.hdfs.rollSize = 500 21 a1.sinks.k1.hdfs.rollCount = 20 22 a1.sinks.k1.hdfs.batchSize = 5 23 a1.sinks.k1.hdfs.useLocalTimeStamp = true 24 a1.sinks.k1.hdfs.fileType = DataStream 25 26 27 28 # Use a channel which buffers events in memory 29 a1.channels.c1.type = memory 30 a1.channels.c1.capacity = 1000 31 a1.channels.c1.transactionCapacity = 100 32 33 # Bind the source and sink to the channel 34 a1.sources.r1.channels = c1 35 a1.sinks.k1.channel = c1
然后启动你的hdfs,yarn可以不启动,这里都启动起来了:
[root@master hadoop]# start-dfs.sh
[root@master hadoop]# start-yarn.sh
启动起来以后,可以查看一下hdfs是否正常工作,如下所示:
[root@master hadoop]# hdfs dfsadmin -report
1 Configured Capacity: 56104357888 (52.25 GB) 2 Present Capacity: 39446368256 (36.74 GB) 3 DFS Remaining: 39438364672 (36.73 GB) 4 DFS Used: 8003584 (7.63 MB) 5 DFS Used%: 0.02% 6 Under replicated blocks: 0 7 Blocks with corrupt replicas: 0 8 Missing blocks: 0 9 10 ------------------------------------------------- 11 Live datanodes (3): 12 13 Name: 192.168.199.130:50010 (master) 14 Hostname: master 15 Decommission Status : Normal 16 Configured Capacity: 18611974144 (17.33 GB) 17 DFS Used: 3084288 (2.94 MB) 18 Non DFS Used: 7680802816 (7.15 GB) 19 DFS Remaining: 10928087040 (10.18 GB) 20 DFS Used%: 0.02% 21 DFS Remaining%: 58.72% 22 Configured Cache Capacity: 0 (0 B) 23 Cache Used: 0 (0 B) 24 Cache Remaining: 0 (0 B) 25 Cache Used%: 100.00% 26 Cache Remaining%: 0.00% 27 Xceivers: 1 28 Last contact: Sat Dec 16 13:31:03 CST 2017 29 30 31 Name: 192.168.199.132:50010 (slaver2) 32 Hostname: slaver2 33 Decommission Status : Normal 34 Configured Capacity: 18746191872 (17.46 GB) 35 DFS Used: 1830912 (1.75 MB) 36 Non DFS Used: 4413718528 (4.11 GB) 37 DFS Remaining: 14330642432 (13.35 GB) 38 DFS Used%: 0.01% 39 DFS Remaining%: 76.45% 40 Configured Cache Capacity: 0 (0 B) 41 Cache Used: 0 (0 B) 42 Cache Remaining: 0 (0 B) 43 Cache Used%: 100.00% 44 Cache Remaining%: 0.00% 45 Xceivers: 1 46 Last contact: Sat Dec 16 13:31:03 CST 2017 47 48 49 Name: 192.168.199.131:50010 (slaver1) 50 Hostname: slaver1 51 Decommission Status : Normal 52 Configured Capacity: 18746191872 (17.46 GB) 53 DFS Used: 3088384 (2.95 MB) 54 Non DFS Used: 4563468288 (4.25 GB) 55 DFS Remaining: 14179635200 (13.21 GB) 56 DFS Used%: 0.02% 57 DFS Remaining%: 75.64% 58 Configured Cache Capacity: 0 (0 B) 59 Cache Used: 0 (0 B) 60 Cache Remaining: 0 (0 B) 61 Cache Used%: 100.00% 62 Cache Remaining%: 0.00% 63 Xceivers: 1 64 Last contact: Sat Dec 16 13:31:03 CST 2017 65 66 67 [root@master hadoop]#
如果hdfs正常启动,然后呢,用tail命令获取数据,下沉到hdfs,将数据存放到hdfs上面:
启动命令,启动采集,启动flume的agent,以及操作如下所示(注意:启动命令中的 -n 参数要给配置文件中配置的agent名称):
bin/flume-ng agent -c conf -f conf/tail-hdfs.conf -n a1
1 [root@master conf]# cd /home/hadoop/soft/flume/ 2 [root@master flume]# ls 3 bin CHANGELOG conf DEVNOTES docs lib LICENSE NOTICE README RELEASE-NOTES tools 4 [root@master flume]# bin/flume-ng agent -c conf -f conf/tail-hdfs.conf -n a1
出现如下说明已经清洗完毕:
1 [root@master flume]# bin/flume-ng agent -c conf -f conf/tail-hdfs.conf -n a1 2 Info: Sourcing environment configuration script /home/hadoop/soft/flume/conf/flume-env.sh 3 Info: Including Hadoop libraries found via (/home/hadoop/soft/hadoop-2.6.4/bin/hadoop) for HDFS access 4 Info: Excluding /home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/slf4j-api-1.7.5.jar from classpath 5 Info: Excluding /home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar from classpath 6 Info: Including Hive libraries found via (/home/hadoop/soft/apache-hive-1.2.1-bin) for Hive access 7 + exec /home/hadoop/soft/jdk1.7.0_65/bin/java -Xmx20m -cp ‘/home/hadoop/soft/flume/conf:/home/hadoop/soft/flume/lib/*:/home/hadoop/soft/hadoop-2.6.4/etc/hadoop:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/activation-1.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/asm-3.2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/avro-1.7.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/commons-cli-1.2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/commons-codec-1.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/commons-collections-3.2.2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/commons-compress-1.4.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/commons-configuration-1.6.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/commons-digester-1.8.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/commons-el-1.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/commons-httpclient-3.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/commons-io-2.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/commons-lang-2.6.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/commons-logging-1.1.3.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/commons-math3-3.1.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/commons-net-3.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/curator-client-2.6.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/curator-framework-2.6.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/curator-recipes-2.6.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/gson-2.2.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/guava-11.0.2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/hadoop-annotations-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/hadoop-auth-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/hamcrest-core-1.3.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/htrace-core-3.0.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/httpclient-4.2.5.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/httpcore-4.2.5.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jasper-compiler-5.5.23.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jasper-runtime-5.5.23.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jersey-core-1.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jersey-json-1.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jersey-server-1.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jets3t-0.9.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jettison-1.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jetty-6.1.26.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jetty-util-6.1.26.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jsch-0.1.42.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jsp-api-2.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/jsr305-1.3.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/junit-4.11.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/log4j-1.2.17.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/mockito-all-1.8.5.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/netty-3.6.2.Final.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/paranamer-2.3.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/servlet-api-2.5.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/stax-api-1.0-2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/xmlenc-0.52.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/xz-1.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib/zookeeper-3.4.6.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/hadoop-common-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/hadoop-common-2.6.4-tests.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/hadoop-nfs-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/jdiff:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/lib:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/sources:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/common/templates:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/asm-3.2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/commons-el-1.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/commons-io-2.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/guava-11.0.2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/htrace-core-3.0.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/jasper-runtime-5.5.23.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/jsp-api-2.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/jsr305-1.3.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/hadoop-hdfs-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/hadoop-hdfs-2.6.4-tests.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/hadoop-hdfs-nfs-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/jdiff:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/lib:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/sources:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/templates:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/hdfs/webapps:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/activation-1.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/aopalliance-1.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/asm-3.2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/commons-cli-1.2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/commons-codec-1.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/commons-httpclient-3.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/commons-io-2.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/commons-lang-2.6.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/guava-11.0.2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/guice-3.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/javax.inject-1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jersey-client-1.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jersey-core-1.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jersey-json-1.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jersey-server-1.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jettison-1.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jetty-6.1.26.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jline-2.12.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/jsr305-1.3.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/log4j-1.2.17.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/servlet-api-2.5.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/xz-1.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/hadoop-yarn-api-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/hadoop-yarn-client-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/hadoop-yarn-common-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/hadoop-yarn-registry-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/hadoop-yarn-server-common-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/hadoop-yarn-server-tests-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/lib:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/sources:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/yarn/test:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/asm-3.2.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/guice-3.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/hadoop-annotations-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/javax.inject-1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/junit-4.11.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib/xz-1.0.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.6.4-tests.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/lib-examples:/home/hadoop/soft/hadoop-2.6.4/share/hadoop/mapreduce/sources:/home/hadoop/soft/hadoop-2.6.4/contrib/capacity-scheduler/*.jar:/home/hadoop/soft/apache-hive-1.2.1-bin/lib/*‘ -Djava.library.path=:/home/hadoop/soft/hadoop-2.6.4/lib/native org.apache.flume.node.Application -f conf/tail-hdfs.conf -n a1
然后呢,可以查看一下,使用命令或者浏览器查看,如下所示:
如果/home/hadoop/data_hadoop/access.log文件不断生成日志,那么下面的清洗的也不断生成。
1 [root@master hadoop]# hadoop fs -ls /flume/events/17-12-16
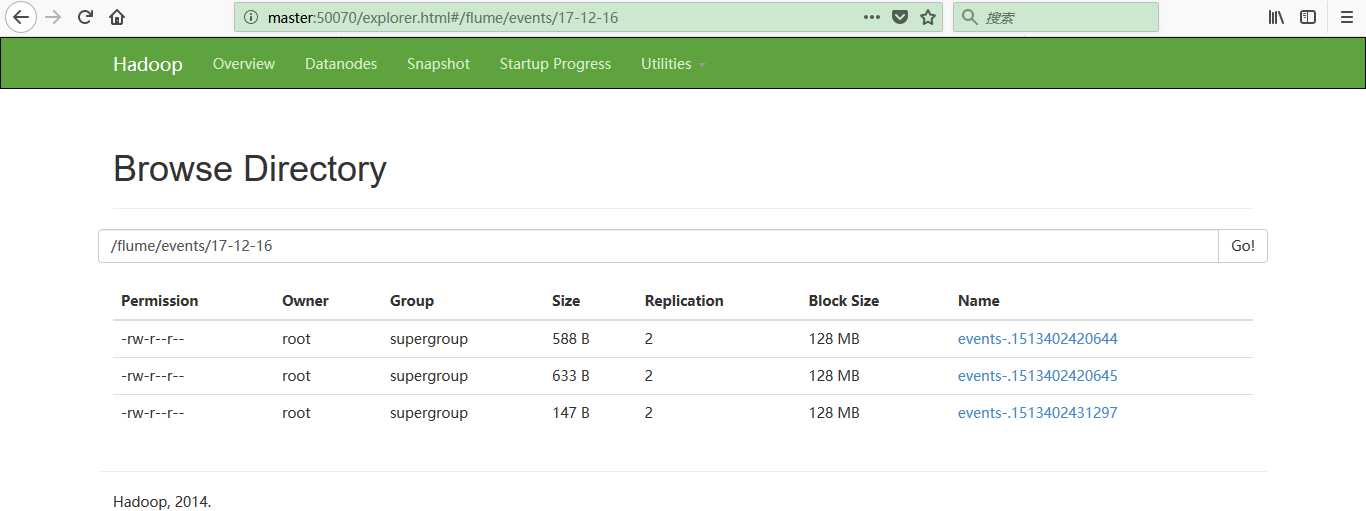
4:模块开发——数据预处理:
4.1 主要目的: 过滤“不合规”数据 格式转换和规整 根据后续的统计需求,过滤分离出各种不同主题(不同栏目path)的基础数据 4.2 实现方式: 开发一个mapreduce程序WeblogPreProcess(不贴代码了,详细见github代码);
开发程序,在window操作系统的eclipse工具,导入的jar包包含hadoop的jar包(之前说过,这里不多做啰嗦了)和hive的jar包(apache-hive-1.2.1-bin\lib的jar包):
学习的过程中,也许要查看hadoop的源码,之前弄出来,今天按ctrl键查看hadoop的时候没办法看了,也忘记咋弄的了,这里记录一下,我赶紧最方便快捷,操作如:右键项目--》Build Path--》Configure Build Path--》Source--》Link Source然后选择hadoop-2.6.4-src即可。
如果无法查看类的话,如下操作:选中此jar包,然后属性properties,然后java source attachment,然后external location,然后external floder即可。
程序开发完毕可以运行一下,对数据进行预处理操作(即清洗日志数据):
[root@master data_hadoop]# hadoop jar webLogPreProcess.java.jar com.bie.dataStream.hive.mapReduce.pre.WeblogPreProcess /flume/events/17-12-16 /flume/filterOutput
执行的结果如下所示:
1 [root@master data_hadoop]# hadoop jar webLogPreProcess.java.jar com.bie.dataStream.hive.mapReduce.pre.WeblogPreProcess /flume/events/17-12-16 /flume/filterOutput 2 17/12/16 17:57:25 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.199.130:8032 3 17/12/16 17:57:57 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 4 17/12/16 17:58:03 INFO input.FileInputFormat: Total input paths to process : 3 5 17/12/16 17:58:08 INFO mapreduce.JobSubmitter: number of splits:3 6 17/12/16 17:58:09 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1513402019656_0001 7 17/12/16 17:58:19 INFO impl.YarnClientImpl: Submitted application application_1513402019656_0001 8 17/12/16 17:58:20 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1513402019656_0001/ 9 17/12/16 17:58:20 INFO mapreduce.Job: Running job: job_1513402019656_0001 10 17/12/16 17:59:05 INFO mapreduce.Job: Job job_1513402019656_0001 running in uber mode : false 11 17/12/16 17:59:05 INFO mapreduce.Job: map 0% reduce 0% 12 17/12/16 18:00:25 INFO mapreduce.Job: map 100% reduce 0% 13 17/12/16 18:00:27 INFO mapreduce.Job: Job job_1513402019656_0001 completed successfully 14 17/12/16 18:00:27 INFO mapreduce.Job: Counters: 30 15 File System Counters 16 FILE: Number of bytes read=0 17 FILE: Number of bytes written=318342 18 FILE: Number of read operations=0 19 FILE: Number of large read operations=0 20 FILE: Number of write operations=0 21 HDFS: Number of bytes read=1749 22 HDFS: Number of bytes written=1138 23 HDFS: Number of read operations=15 24 HDFS: Number of large read operations=0 25 HDFS: Number of write operations=6 26 Job Counters 27 Launched map tasks=3 28 Data-local map tasks=3 29 Total time spent by all maps in occupied slots (ms)=212389 30 Total time spent by all reduces in occupied slots (ms)=0 31 Total time spent by all map tasks (ms)=212389 32 Total vcore-milliseconds taken by all map tasks=212389 33 Total megabyte-milliseconds taken by all map tasks=217486336 34 Map-Reduce Framework 35 Map input records=10 36 Map output records=10 37 Input split bytes=381 38 Spilled Records=0 39 Failed Shuffles=0 40 Merged Map outputs=0 41 GC time elapsed (ms)=3892 42 CPU time spent (ms)=3820 43 Physical memory (bytes) snapshot=160026624 44 Virtual memory (bytes) snapshot=1093730304 45 Total committed heap usage (bytes)=33996800 46 File Input Format Counters 47 Bytes Read=1368 48 File Output Format Counters 49 Bytes Written=1138 50 [root@master data_hadoop]#
可以使用命令进行查看操作:
1 [root@master data_hadoop]# hadoop fs -cat /flume/filterOutput/part-m-00000 2 3 [root@master data_hadoop]# hadoop fs -cat /flume/filterOutput/part-m-00001 4 5 [root@master data_hadoop]# hadoop fs -cat /flume/filterOutput/part-m-00002
做到这里,发现自己好像做懵了,由于数据采集过程,我并没做,所以flume采集数据,就没有这个过程了,这里使用flume对access.log数据进行采集,发现采集没多少条,这才发现自己思考错误了,access.log文件里面的数据就是采集好的。数据采集,数据预处理,数据入库,数据分析,数据展现;那么数据采集就算使用现成的数据文件access.log了。所以,从数据预处理开始就可以了。
那么,数据预处理操作,将写好的程序可以在window的eclipse跑一下,结果如下所示(由于上面的flume算是练习了,没有删,在这篇博客里面属于阉割的。所以看到的小伙伴选择性看即可):
1 2017-12-16 21:51:18,078 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(1129)) - session.id is deprecated. Instead, use dfs.metrics.session-id 2 2017-12-16 21:51:18,083 INFO [main] jvm.JvmMetrics (JvmMetrics.java:init(76)) - Initializing JVM Metrics with processName=JobTracker, sessionId= 3 2017-12-16 21:51:18,469 WARN [main] mapreduce.JobResourceUploader (JobResourceUploader.java:uploadFiles(64)) - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 4 2017-12-16 21:51:18,481 WARN [main] mapreduce.JobResourceUploader (JobResourceUploader.java:uploadFiles(171)) - No job jar file set. User classes may not be found. See Job or Job#setJar(String). 5 2017-12-16 21:51:18,616 INFO [main] input.FileInputFormat (FileInputFormat.java:listStatus(281)) - Total input paths to process : 1 6 2017-12-16 21:51:18,719 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:submitJobInternal(199)) - number of splits:1 7 2017-12-16 21:51:18,931 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:printTokens(288)) - Submitting tokens for job: job_local616550674_0001 8 2017-12-16 21:51:19,258 INFO [main] mapreduce.Job (Job.java:submit(1301)) - The url to track the job: http://localhost:8080/ 9 2017-12-16 21:51:19,259 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1346)) - Running job: job_local616550674_0001 10 2017-12-16 21:51:19,261 INFO [Thread-5] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(471)) - OutputCommitter set in config null 11 2017-12-16 21:51:19,273 INFO [Thread-5] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(489)) - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 12 2017-12-16 21:51:19,355 INFO [Thread-5] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(448)) - Waiting for map tasks 13 2017-12-16 21:51:19,355 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:run(224)) - Starting task: attempt_local616550674_0001_m_000000_0 14 2017-12-16 21:51:19,412 INFO [LocalJobRunner Map Task Executor #0] util.ProcfsBasedProcessTree (ProcfsBasedProcessTree.java:isAvailable(181)) - ProcfsBasedProcessTree currently is supported only on Linux. 15 2017-12-16 21:51:19,479 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:initialize(587)) - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@75805410 16 2017-12-16 21:51:19,487 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:runNewMapper(753)) - Processing split: file:/C:/Users/bhlgo/Desktop/input/access.log.fensi:0+3025757 17 2017-12-16 21:51:20,273 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1367)) - Job job_local616550674_0001 running in uber mode : false 18 2017-12-16 21:51:20,275 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1374)) - map 0% reduce 0% 19 2017-12-16 21:51:21,240 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 20 2017-12-16 21:51:21,242 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:done(1001)) - Task:attempt_local616550674_0001_m_000000_0 is done. And is in the process of committing 21 2017-12-16 21:51:21,315 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 22 2017-12-16 21:51:21,315 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:commit(1162)) - Task attempt_local616550674_0001_m_000000_0 is allowed to commit now 23 2017-12-16 21:51:21,377 INFO [LocalJobRunner Map Task Executor #0] output.FileOutputCommitter (FileOutputCommitter.java:commitTask(439)) - Saved output of task ‘attempt_local616550674_0001_m_000000_0‘ to file:/C:/Users/bhlgo/Desktop/output/_temporary/0/task_local616550674_0001_m_000000 24 2017-12-16 21:51:21,395 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - map 25 2017-12-16 21:51:21,395 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:sendDone(1121)) - Task ‘attempt_local616550674_0001_m_000000_0‘ done. 26 2017-12-16 21:51:21,395 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:run(249)) - Finishing task: attempt_local616550674_0001_m_000000_0 27 2017-12-16 21:51:21,405 INFO [Thread-5] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(456)) - map task executor complete. 28 2017-12-16 21:51:22,303 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1374)) - map 100% reduce 0% 29 2017-12-16 21:51:22,304 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1385)) - Job job_local616550674_0001 completed successfully 30 2017-12-16 21:51:22,321 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1392)) - Counters: 18 31 File System Counters 32 FILE: Number of bytes read=3025930 33 FILE: Number of bytes written=2898908 34 FILE: Number of read operations=0 35 FILE: Number of large read operations=0 36 FILE: Number of write operations=0 37 Map-Reduce Framework 38 Map input records=14619 39 Map output records=14619 40 Input split bytes=116 41 Spilled Records=0 42 Failed Shuffles=0 43 Merged Map outputs=0 44 GC time elapsed (ms)=40 45 CPU time spent (ms)=0 46 Physical memory (bytes) snapshot=0 47 Virtual memory (bytes) snapshot=0 48 Total committed heap usage (bytes)=162529280 49 File Input Format Counters 50 Bytes Read=3025757 51 File Output Format Counters 52 Bytes Written=2647097
生成的文件,切记输出文件,例如output文件是自动生成的:
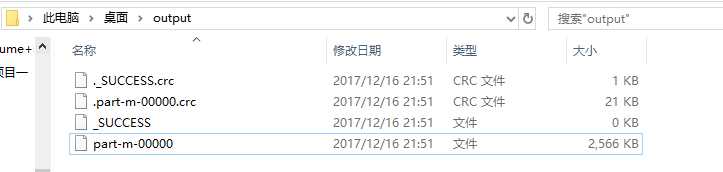
4.3 点击流模型数据梳理(预处理程序和模型梳理程序处理的生成三份数据,这里都需要使用,hive建表映射。预处理阶段的mapReduce程序的调度脚本.):
由于大量的指标统计从点击流模型中更容易得出,所以在预处理阶段,可以使用mr程序来生成点击流模型的数据;
4.3.1 点击流模型pageviews表,Pageviews表模型数据生成:
4.3.2 点击流模型visit信息表
注:“一次访问”=“N次连续请求”;
直接从原始数据中用hql语法得出每个人的“次”访问信息比较困难,可先用mapreduce程序分析原始数据得出“次”信息数据,然后再用hql进行更多维度统计;
用MR程序从pageviews数据中,梳理出每一次visit的起止时间、页面信息;
方法一,如下所示: 开发到此处,有出现一点小问题,你将写好的程序可以手动执行,即如下所示: hadoop jar webLogPreProcess.jar com.bie.dataStream.hive.mapReduce.pre.WeblogPreProcess /data/weblog/preprocess/input /data/weblog/preprocess/output hadoop jar webLogPreProcess.jar com.bie.dataStream.hive.mapReduce.pre.WeblogPreValid /data/weblog/preprocess/input /data/weblog/preprocess/valid_output hadoop jar webLogPreProcess.jar com.bie.dataStream.hive.mapReduce.ClickStream /data/weblog/preprocess/output /data/weblog/preprocess/click_pv_out hadoop jar webLogPreProcess.jar com.bie.dataStream.hive.mapReduce.pre.ClickStreamVisit /data/weblog/preprocess/click_pv_out /data/weblog/preprocess/click_visit_out 方法二:使用azkaban进行任务调度:
接下来启动我的azkaban任务调度工具:
1 [root@master flume]# cd /home/hadoop/azkabantools/server/ 2 [root@master server]# nohup bin/azkaban-web-start.sh 1>/tmp/azstd.out 2>/tmp/azerr.out& 3 [root@master server]# jps 4 [root@master server]# cd ../executor/ 5 [root@master executor]# bin/azkaban-executor-start.sh
然后在浏览器登陆azkaban客户端:https://master:8443,账号和密码都是自己设置好的,我的是admin,admin。
1 预先启动你的集群,如下所示 2 [root@master hadoop]# start-dfs.sh 3 [root@master hadoop]# start-yarn.sh 4 将事先使用的输入目录创建好,如下所示,输出目录不用创建,否则报错: 5 [root@master hadoop]# hadoop fs -mkdir -p /data/weblog/preprocess/input 6 然后将采集好的数据上传到这个input目录里面即可: 7 [root@master data_hadoop]# hadoop fs -put access.log /data/weblog/preprocess/input
我这里使用azkaban遇到一点小问题,先使用手动对数据进行处理了。真是问题不断......
1 [root@master data_hadoop]# hadoop jar webLogPreProcess.jar com.bie.dataStream.hive.mapReduce.pre.WeblogPreProcess /data/weblog/preprocess/input /data/weblog/preprocess/output 2 Exception in thread "main" java.io.IOException: No FileSystem for scheme: C 3 at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:2584) 4 at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2591) 5 at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:91) 6 at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2630) 7 at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2612) 8 at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:370) 9 at org.apache.hadoop.fs.Path.getFileSystem(Path.java:296) 10 at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.setInputPaths(FileInputFormat.java:498) 11 at com.bie.dataStream.hive.mapReduce.pre.WeblogPreProcess.main(WeblogPreProcess.java:94) 12 at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) 13 at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57) 14 at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) 15 at java.lang.reflect.Method.invoke(Method.java:606) 16 at org.apache.hadoop.util.RunJar.run(RunJar.java:221) 17 at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
手动执行过程中遇到如上问题,是因为我的主方法里面路径写成了下面的那种在window运行的了,解决方法,修改以后,重新打包即可;
这篇博客,从下面开始,才具有意义,以上全是摸索式进行的。这里还是最原始手动执行的。以先做出来为主吧。
1 FileInputFormat.setInputPaths(job, new Path(args[0])); 2 FileOutputFormat.setOutputPath(job, new Path(args[1])); 3 4 //FileInputFormat.setInputPaths(job, new Path("c:/weblog/pageviews")); 5 //FileOutputFormat.setOutputPath(job, new Path("c:/weblog/visitout")); 6
运行结果如下所示:
1 [root@master data_hadoop]# hadoop jar webLogPreProcess.jar com.bie.dataStream.hive.mapReduce.pre.WeblogPreProcess /data/weblog/preprocess/input /data/weblog/preprocess/output 2 17/12/17 14:37:29 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.199.130:8032 3 17/12/17 14:37:44 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 4 17/12/17 14:37:54 INFO input.FileInputFormat: Total input paths to process : 1 5 17/12/17 14:38:07 INFO mapreduce.JobSubmitter: number of splits:1 6 17/12/17 14:38:10 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1513489846377_0001 7 17/12/17 14:38:19 INFO impl.YarnClientImpl: Submitted application application_1513489846377_0001 8 17/12/17 14:38:19 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1513489846377_0001/ 9 17/12/17 14:38:19 INFO mapreduce.Job: Running job: job_1513489846377_0001 10 17/12/17 14:39:51 INFO mapreduce.Job: Job job_1513489846377_0001 running in uber mode : false 11 17/12/17 14:39:51 INFO mapreduce.Job: map 0% reduce 0% 12 17/12/17 14:40:16 INFO mapreduce.Job: map 100% reduce 0% 13 17/12/17 14:40:29 INFO mapreduce.Job: Job job_1513489846377_0001 completed successfully 14 17/12/17 14:40:30 INFO mapreduce.Job: Counters: 30 15 File System Counters 16 FILE: Number of bytes read=0 17 FILE: Number of bytes written=106127 18 FILE: Number of read operations=0 19 FILE: Number of large read operations=0 20 FILE: Number of write operations=0 21 HDFS: Number of bytes read=3025880 22 HDFS: Number of bytes written=2626565 23 HDFS: Number of read operations=5 24 HDFS: Number of large read operations=0 25 HDFS: Number of write operations=2 26 Job Counters 27 Launched map tasks=1 28 Data-local map tasks=1 29 Total time spent by all maps in occupied slots (ms)=15389 30 Total time spent by all reduces in occupied slots (ms)=0 31 Total time spent by all map tasks (ms)=15389 32 Total vcore-milliseconds taken by all map tasks=15389 33 Total megabyte-milliseconds taken by all map tasks=15758336 34 Map-Reduce Framework 35 Map input records=14619 36 Map output records=14619 37 Input split bytes=123 38 Spilled Records=0 39 Failed Shuffles=0 40 Merged Map outputs=0 41 GC time elapsed (ms)=201 42 CPU time spent (ms)=990 43 Physical memory (bytes) snapshot=60375040 44 Virtual memory (bytes) snapshot=364576768 45 Total committed heap usage (bytes)=17260544 46 File Input Format Counters 47 Bytes Read=3025757 48 File Output Format Counters 49 Bytes Written=2626565 50 [root@master data_hadoop]#
浏览器查看如下所示:
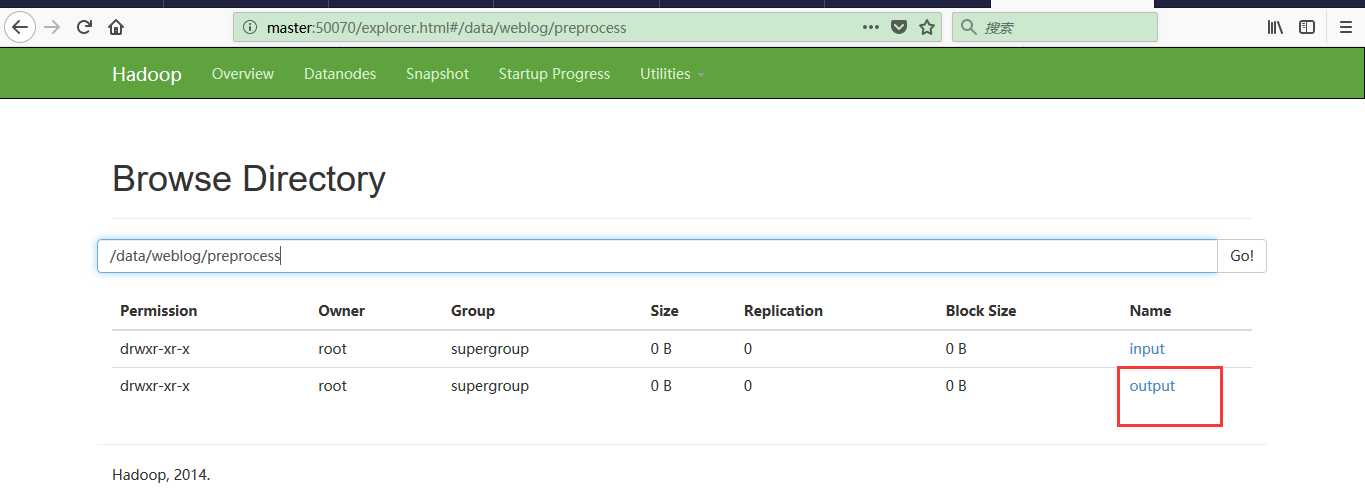
点击流模型数据梳理
由于大量的指标统计从点击流模型中更容易得出,所以在预处理阶段,可以使用mr程序来生成点击流模型的数据
1 [root@master data_hadoop]# hadoop jar webLogPreProcess.jar com.bie.dataStream.hive.mapReduce.ClickStream /data/weblog/preprocess/output /data/weblog/preprocess/click_pv_out 2 17/12/17 14:47:33 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.199.130:8032 3 17/12/17 14:47:43 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 4 17/12/17 14:48:16 INFO input.FileInputFormat: Total input paths to process : 1 5 17/12/17 14:48:18 INFO mapreduce.JobSubmitter: number of splits:1 6 17/12/17 14:48:21 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1513489846377_0002 7 17/12/17 14:48:22 INFO impl.YarnClientImpl: Submitted application application_1513489846377_0002 8 17/12/17 14:48:22 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1513489846377_0002/ 9 17/12/17 14:48:22 INFO mapreduce.Job: Running job: job_1513489846377_0002 10 17/12/17 14:48:44 INFO mapreduce.Job: Job job_1513489846377_0002 running in uber mode : false 11 17/12/17 14:48:45 INFO mapreduce.Job: map 0% reduce 0% 12 17/12/17 14:48:58 INFO mapreduce.Job: map 100% reduce 0% 13 17/12/17 14:49:39 INFO mapreduce.Job: map 100% reduce 100% 14 17/12/17 14:49:42 INFO mapreduce.Job: Job job_1513489846377_0002 completed successfully 15 17/12/17 14:49:43 INFO mapreduce.Job: Counters: 49 16 File System Counters 17 FILE: Number of bytes read=17187 18 FILE: Number of bytes written=247953 19 FILE: Number of read operations=0 20 FILE: Number of large read operations=0 21 FILE: Number of write operations=0 22 HDFS: Number of bytes read=2626691 23 HDFS: Number of bytes written=18372 24 HDFS: Number of read operations=6 25 HDFS: Number of large read operations=0 26 HDFS: Number of write operations=2 27 Job Counters 28 Launched map tasks=1 29 Launched reduce tasks=1 30 Data-local map tasks=1 31 Total time spent by all maps in occupied slots (ms)=10414 32 Total time spent by all reduces in occupied slots (ms)=38407 33 Total time spent by all map tasks (ms)=10414 34 Total time spent by all reduce tasks (ms)=38407 35 Total vcore-milliseconds taken by all map tasks=10414 36 Total vcore-milliseconds taken by all reduce tasks=38407 37 Total megabyte-milliseconds taken by all map tasks=10663936 38 Total megabyte-milliseconds taken by all reduce tasks=39328768 39 Map-Reduce Framework 40 Map input records=14619 41 Map output records=76 42 Map output bytes=16950 43 Map output materialized bytes=17187 44 Input split bytes=126 45 Combine input records=0 46 Combine output records=0 47 Reduce input groups=53 48 Reduce shuffle bytes=17187 49 Reduce input records=76 50 Reduce output records=76 51 Spilled Records=152 52 Shuffled Maps =1 53 Failed Shuffles=0 54 Merged Map outputs=1 55 GC time elapsed (ms)=327 56 CPU time spent (ms)=1600 57 Physical memory (bytes) snapshot=205991936 58 Virtual memory (bytes) snapshot=730013696 59 Total committed heap usage (bytes)=127045632 60 Shuffle Errors 61 BAD_ID=0 62 CONNECTION=0 63 IO_ERROR=0 64 WRONG_LENGTH=0 65 WRONG_MAP=0 66 WRONG_REDUCE=0 67 File Input Format Counters 68 Bytes Read=2626565 69 File Output Format Counters 70 Bytes Written=18372 71 [root@master data_hadoop]#
执行结果如下所示:
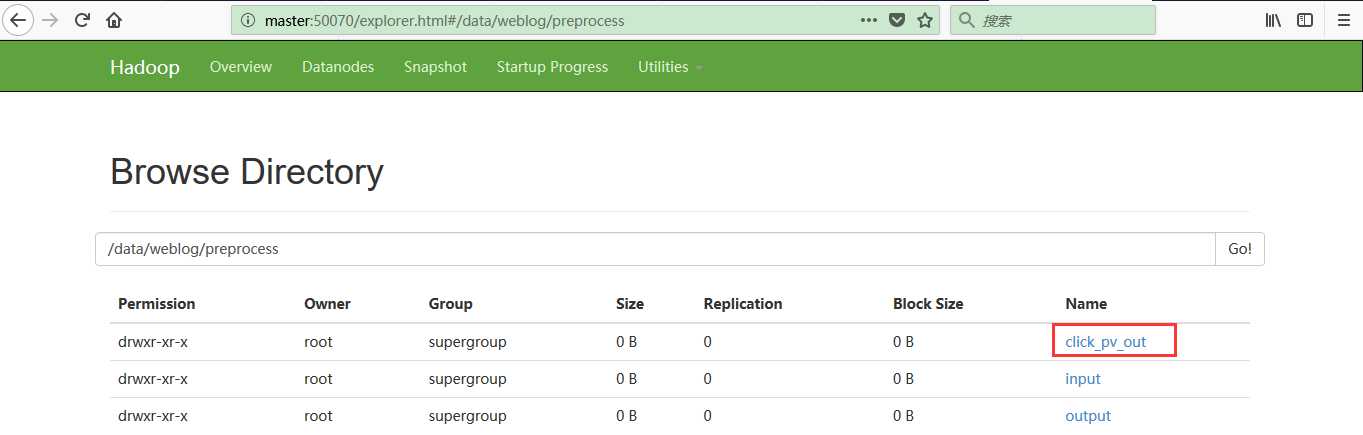
点击流模型visit信息表:
注:“一次访问”=“N次连续请求”
直接从原始数据中用hql语法得出每个人的“次”访问信息比较困难,可先用mapreduce程序分析原始数据得出“次”信息数据,然后再用hql进行更多维度统计
用MR程序从pageviews数据中,梳理出每一次visit的起止时间、页面信息:
1 [root@master data_hadoop]# hadoop jar webLogPreProcess.jar com.bie.dataStream.hive.mapReduce.pre.ClickStreamVisit /data/weblog/preprocess/click_pv_out /data/weblog/preprocess/click_visit_out 2 17/12/17 15:06:30 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.199.130:8032 3 17/12/17 15:06:32 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 4 17/12/17 15:06:33 INFO input.FileInputFormat: Total input paths to process : 1 5 17/12/17 15:06:33 INFO mapreduce.JobSubmitter: number of splits:1 6 17/12/17 15:06:34 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1513489846377_0003 7 17/12/17 15:06:35 INFO impl.YarnClientImpl: Submitted application application_1513489846377_0003 8 17/12/17 15:06:35 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1513489846377_0003/ 9 17/12/17 15:06:35 INFO mapreduce.Job: Running job: job_1513489846377_0003 10 17/12/17 15:06:47 INFO mapreduce.Job: Job job_1513489846377_0003 running in uber mode : false 11 17/12/17 15:06:47 INFO mapreduce.Job: map 0% reduce 0% 12 17/12/17 15:07:44 INFO mapreduce.Job: map 100% reduce 0% 13 17/12/17 15:08:15 INFO mapreduce.Job: map 100% reduce 100% 14 17/12/17 15:08:18 INFO mapreduce.Job: Job job_1513489846377_0003 completed successfully 15 17/12/17 15:08:18 INFO mapreduce.Job: Counters: 49 16 File System Counters 17 FILE: Number of bytes read=6 18 FILE: Number of bytes written=213705 19 FILE: Number of read operations=0 20 FILE: Number of large read operations=0 21 FILE: Number of write operations=0 22 HDFS: Number of bytes read=18504 23 HDFS: Number of bytes written=0 24 HDFS: Number of read operations=6 25 HDFS: Number of large read operations=0 26 HDFS: Number of write operations=2 27 Job Counters 28 Launched map tasks=1 29 Launched reduce tasks=1 30 Data-local map tasks=1 31 Total time spent by all maps in occupied slots (ms)=55701 32 Total time spent by all reduces in occupied slots (ms)=22157 33 Total time spent by all map tasks (ms)=55701 34 Total time spent by all reduce tasks (ms)=22157 35 Total vcore-milliseconds taken by all map tasks=55701 36 Total vcore-milliseconds taken by all reduce tasks=22157 37 Total megabyte-milliseconds taken by all map tasks=57037824 38 Total megabyte-milliseconds taken by all reduce tasks=22688768 39 Map-Reduce Framework 40 Map input records=76 41 Map output records=0 42 Map output bytes=0 43 Map output materialized bytes=6 44 Input split bytes=132 45 Combine input records=0 46 Combine output records=0 47 Reduce input groups=0 48 Reduce shuffle bytes=6 49 Reduce input records=0 50 Reduce output records=0 51 Spilled Records=0 52 Shuffled Maps =1 53 Failed Shuffles=0 54 Merged Map outputs=1 55 GC time elapsed (ms)=325 56 CPU time spent (ms)=1310 57 Physical memory (bytes) snapshot=203296768 58 Virtual memory (bytes) snapshot=730161152 59 Total committed heap usage (bytes)=126246912 60 Shuffle Errors 61 BAD_ID=0 62 CONNECTION=0 63 IO_ERROR=0 64 WRONG_LENGTH=0 65 WRONG_MAP=0 66 WRONG_REDUCE=0 67 File Input Format Counters 68 Bytes Read=18372 69 File Output Format Counters 70 Bytes Written=0 71 [root@master data_hadoop]#
运行结果如下所示:
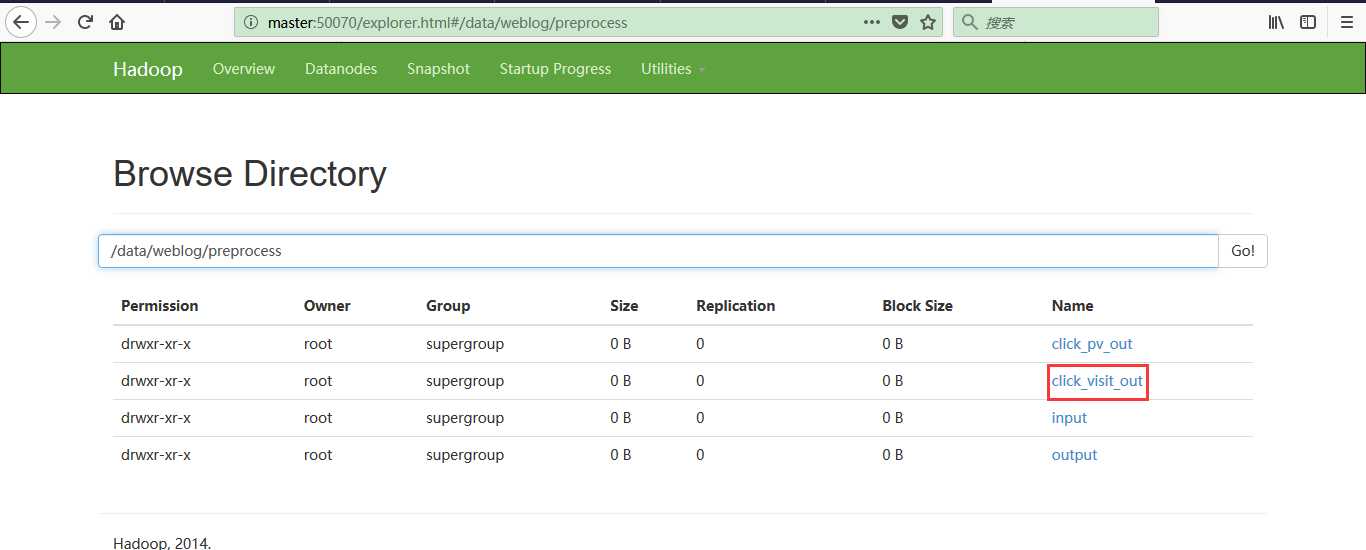
5:模块开发——数据仓库设计(注:采用星型模型,数据仓库概念知识以及星型模型和雪花模型的区别请自行脑补。):
星型模型是采用事实表和维度表的模型的。下面创建事实表,维度表这里省略,不做处理。
|
原始数据表:t_origin_weblog |
||
|
valid |
string |
是否有效 |
|
remote_addr |
string |
访客ip |
|
remote_user |
string |
访客用户信息 |
|
time_local |
string |
请求时间 |
|
request |
string |
请求url |
|
status |
string |
响应码 |
|
body_bytes_sent |
string |
响应字节数 |
|
http_referer |
string |
来源url |
|
http_user_agent |
string |
访客终端信息 |
|
ETL中间表:t_etl_referurl |
||
|
valid |
string |
是否有效 |
|
remote_addr |
string |
访客ip |
|
remote_user |
string |
访客用户信息 |
|
time_local |
string |
请求时间 |
|
request |
string |
请求url |
|
request_host |
string |
请求的域名 |
|
status |
string |
响应码 |
|
body_bytes_sent |
string |
响应字节数 |
|
http_referer |
string |
来源url |
|
http_user_agent |
string |
访客终端信息 |
|
valid |
string |
是否有效 |
|
remote_addr |
string |
访客ip |
|
remote_user |
string |
访客用户信息 |
|
time_local |
string |
请求时间 |
|
request |
string |
请求url |
|
status |
string |
响应码 |
|
body_bytes_sent |
string |
响应字节数 |
|
http_referer |
string |
外链url |
|
http_user_agent |
string |
访客终端信息 |
|
host |
string |
外链url的域名 |
|
path |
string |
外链url的路径 |
|
query |
string |
外链url的参数 |
|
query_id |
string |
外链url的参数值 |
|
访问日志明细宽表:t_ods_access_detail |
||
|
valid |
string |
是否有效 |
|
remote_addr |
string |
访客ip |
|
remote_user |
string |
访客用户信息 |
|
time_local |
string |
请求时间 |
|
request |
string |
请求url整串 |
|
request_level1 |
string |
请求的一级栏目 |
|
request_level2 |
string |
请求的二级栏目 |
|
request_level3 |
string |
请求的三级栏目 |
|
status |
string |
响应码 |
|
body_bytes_sent |
string |
响应字节数 |
|
http_referer |
string |
来源url |
|
http_user_agent |
string |
访客终端信息 |
|
valid |
string |
是否有效 |
|
remote_addr |
string |
访客ip |
|
remote_user |
string |
访客用户信息 |
|
time_local |
string |
请求时间 |
|
request |
string |
请求url |
|
status |
string |
响应码 |
|
body_bytes_sent |
string |
响应字节数 |
|
http_referer |
string |
外链url |
|
http_user_agent |
string |
访客终端信息整串 |
|
http_user_agent_browser |
string |
访客终端浏览器 |
|
http_user_agent_sys |
string |
访客终端操作系统 |
|
http_user_agent_dev |
string |
访客终端设备 |
|
host |
string |
外链url的域名 |
|
path |
string |
外链url的路径 |
|
query |
string |
外链url的参数 |
|
query_id |
string |
外链url的参数值 |
|
daystr |
string |
日期整串 |
|
tmstr |
string |
时间整串 |
|
month |
string |
月份 |
|
day |
string |
日 |
|
hour |
string |
时 |
|
minute |
string |
分 |
|
## |
## |
## |
|
mm |
string |
分区字段--月 |
|
dd |
string |
分区字段--日 |
6 :模块开发——ETL
该项目的数据分析过程在hadoop集群上实现,主要应用hive数据仓库工具,因此,采集并经过预处理后的数据,需要加载到hive数据仓库中,以进行后续的挖掘分析。
6.1:创建原始数据表:
--在hive仓库中建贴源数据表 ods_weblog_origin 下面开始创建hive的数据库和数据表,操作如下所示: [root@master soft]# cd apache-hive-1.2.1-bin/ [root@master apache-hive-1.2.1-bin]# ls [root@master apache-hive-1.2.1-bin]# cd bin/ [root@master apache-hive-1.2.1-bin]# ls [root@master bin]# ./hive hive> show databases; hive> create database webLog; hive> show databases; #按照日期来分区 hive> create table ods_weblog_origin(valid string,remote_addr string,remote_user string,time_local string,request string,status string,body_bytes_sent string,http_referer string,http_user_agent string) > partitioned by (datestr string) > row format delimited > fields terminated by ‘\001‘; hive> show tables; hive> desc ods_weblog_origin; #点击流模型pageviews表 ods_click_pageviews hive> create table ods_click_pageviews( > Session string, > remote_addr string, > remote_user string, > time_local string, > request string, > visit_step string, > page_staylong string, > http_referer string, > http_user_agent string, > body_bytes_sent string, > status string) > partitioned by (datestr string) > row format delimited > fields terminated by ‘\001‘; hive> show tables; #点击流visit模型表 click_stream_visit hive> create table click_stream_visit( > session string, > remote_addr string, > inTime string, > outTime string, > inPage string, > outPage string, > referal string, > pageVisits int) > partitioned by (datestr string); hive> show tables;
6.2:导入数据,操作如下所示:
1 1:导入清洗结果数据到贴源数据表ods_weblog_origin 2 3 hive> load data inpath ‘/data/weblog/preprocess/output/part-m-00000‘ overwrite into table ods_weblog_origin partition(datestr=‘2017-12-17‘); 4 5 hive> show partitions ods_weblog_origin; 6 hive> select count(*) from ods_weblog_origin; 7 hive> select * from ods_weblog_origin; 8 9 2:导入点击流模型pageviews数据到ods_click_pageviews表 10 hive> load data inpath ‘/data/weblog/preprocess/click_pv_out/part-r-00000‘ overwrite into table ods_click_pageviews partition(datestr=‘2017-12-17‘); 11 12 hive> select count(1) from ods_click_pageviews; 13 14 3:导入点击流模型visit数据到click_stream_visit表 15 hive> load data inpath ‘/data/weblog/preprocess/click_visit_out/part-r-00000‘ overwrite into table click_stream_visit partition(datestr=‘2017-12-17‘); 16 17 hive> select count(1) from click_stream_visit;
待续......