Preface
序列问题也是一个interesting的issue.找了一会LSTM的材料,发现并没有一个系统的文字,早期Sepp Hochreiter的paper和弟子Felix Gers的thesis看起来并没有那么轻松。最开始入手的是15年的一个review,当时看起来也不太顺畅,但看了前两个(一部分)再回头来看这篇的formulation部分,会清晰些。
本来打算自己写个程序理一下,发现这里有个参考,程序很短,Python写的总共没有200line,但要从里面理出结构来有些费劲。想起MXNet里面好像有些例子(example/bi-lstm-sort),找出来查看。里面用symbol构建了LSTM基本单元,然后用bucket特性进行优化。感觉还不错,顺带可以看看bucket怎么用的。
Code Plus Comment
这段程序里面用symbol构建了记忆单元,然后用之构建了一个完整的symbol,之前以为是用了内建的的一个符号,但发现MXNet-V1.0版本上LSTM单元内建符号都还处于dev阶段,所以比较感兴趣的是怎么做到时序关联的。
######## from example/bi-lstm-sort/lstm.py #############
def lstm(num_hidden, indata, prev_state, param, seqidx, layeridx, dropout=0.): # 构建一个单元
"""LSTM Cell symbol"""
if dropout > 0.:
indata = mx.sym.Dropout(data=indata, p=dropout)
i2h = mx.sym.FullyConnected(data=indata,
weight=param.i2h_weight,
bias=param.i2h_bias,
num_hidden=num_hidden * 4,
name="t%d_l%d_i2h" % (seqidx, layeridx))
h2h = mx.sym.FullyConnected(data=prev_state.h,
weight=param.h2h_weight,
bias=param.h2h_bias,
num_hidden=num_hidden * 4,
name="t%d_l%d_h2h" % (seqidx, layeridx))
gates = i2h + h2h
slice_gates = mx.sym.SliceChannel(gates, num_outputs=4,
name="t%d_l%d_slice" % (seqidx, layeridx))
in_gate = mx.sym.Activation(slice_gates[0], act_type="sigmoid")
in_transform = mx.sym.Activation(slice_gates[1], act_type="tanh")
forget_gate = mx.sym.Activation(slice_gates[2], act_type="sigmoid")
out_gate = mx.sym.Activation(slice_gates[3], act_type="sigmoid")
next_c = (forget_gate * prev_state.c) + (in_gate * in_transform)
next_h = out_gate * mx.sym.Activation(next_c, act_type="tanh")
return LSTMState(c=next_c, h=next_h)
def bi_lstm_unroll(seq_len, input_size,
num_hidden, num_embed, num_label, dropout=0.):
embed_weight = mx.sym.Variable("embed_weight")
cls_weight = mx.sym.Variable("cls_weight")
cls_bias = mx.sym.Variable("cls_bias")
last_states = []
last_states.append(LSTMState(c = mx.sym.Variable("l0_init_c"), h = mx.sym.Variable("l0_init_h")))
last_states.append(LSTMState(c = mx.sym.Variable("l1_init_c"), h = mx.sym.Variable("l1_init_h")))
forward_param = LSTMParam(i2h_weight=mx.sym.Variable("l0_i2h_weight"),
i2h_bias=mx.sym.Variable("c"),
h2h_weight=mx.sym.Variable("l0_h2h_weight"),
h2h_bias=mx.sym.Variable("l0_h2h_bias"))
backward_param = LSTMParam(i2h_weight=mx.sym.Variable("l1_i2h_weight"),
i2h_bias=mx.sym.Variable("l1_i2h_bias"),
h2h_weight=mx.sym.Variable("l1_h2h_weight"),
h2h_bias=mx.sym.Variable("l1_h2h_bias"))
# embeding layer
data = mx.sym.Variable(‘data‘)
label = mx.sym.Variable(‘softmax_label‘)
embed = mx.sym.Embedding(data=data, input_dim=input_size,
weight=embed_weight, output_dim=num_embed, name=‘embed‘)
wordvec = mx.sym.SliceChannel(data=embed, num_outputs=seq_len, squeeze_axis=1)
forward_hidden = []
for seqidx in range(seq_len):
hidden = wordvec[seqidx]
next_state = lstm(num_hidden, indata=hidden,
prev_state=last_states[0],
param=forward_param,
seqidx=seqidx, layeridx=0, dropout=dropout)
hidden = next_state.h
last_states[0] = next_state
forward_hidden.append(hidden)
backward_hidden = [] # 从文件夹名字看得出来,这是个双向的符号,所以会有 backward部分(just a guess :) )
for seqidx in range(seq_len):
k = seq_len - seqidx - 1
hidden = wordvec[k]
next_state = lstm(num_hidden, indata=hidden,
prev_state=last_states[1],
param=backward_param,
seqidx=k, layeridx=1,dropout=dropout)
hidden = next_state.h
last_states[1] = next_state
backward_hidden.insert(0, hidden)
hidden_all = []
for i in range(seq_len):
hidden_all.append(mx.sym.Concat(*[forward_hidden[i], backward_hidden[i]], dim=1))
hidden_concat = mx.sym.Concat(*hidden_all, dim=0)
pred = mx.sym.FullyConnected(data=hidden_concat, num_hidden=num_label,
weight=cls_weight, bias=cls_bias, name=‘pred‘)
label = mx.sym.transpose(data=label)
label = mx.sym.Reshape(data=label, target_shape=(0,))
sm = mx.sym.SoftmaxOutput(data=pred, label=label, name=‘softmax‘)
return smEmbedding Op
之前翻API的时候,就看到过这个符号,当时虽然明白了可以实现什么功能(虽然也明白错了:以为只能实现引索/编码),但想不到这种功能拿来可以做什么-_-||。现在遇上了,顺带就查查看。API没有附上相应的文献说明这个实现参照的什么,只好到处搜。知乎上的回答应该可以帮助到。整理一下,就是说,用非one-hot编码的方式,对词表进行编码(消除各维数之间的独立性,各维数取值是连续的)。
note
- 这带来的另一个问题是如何进行优化?这个后面把paper看了再看情况吧(只是猜测这一层应该要实现update)。
- 另一个问题是,如果不使用one-hot编码,在模型输出阶段,如何进行解码?从程序上来看,在输出阶段,softmax输出的会被认为是one-hot编码,从而避免这个问题。
Time Dependency
这个例子里面只使用了一层的记忆单元(但根据paper上的情况来看,即使只有一个单元,体型也是很大的)。完整符号的构建是在bi_lstm_unroll里面进行的,其时序依赖关系的建立方案如下。先将输入的单个完整序列(向量序列)用SliceChannel分离成为单个的向量,然后按照分离出的向量个数构建一个完整的符号,由于此时已经知道向量的个数,可以不断地堆积记忆单元,直到每个向量都分配到了对应的处理单元。每个单元使用的参数被指定为同一组(l0_i2h_weight, l0_i2h_bias, etc.)。这样就实现了效果上的循环计算。
note
- 此处产生的另一个问题是,如何处理变长度的输入序列问题。这应该与bucket机制有关,后面找时间看看去。但可以猜测下bucket要解决的问题,从大神的blog看,bucket机制要对每个设定好的长度绑定生成一个模型,并且由于这些长度都是离散的,可能还要进行补齐的操作,如果进行了补齐那么还要处理由此产生的训练更新问题。
LSTM Implementation
来看看怎么构建一个记忆单元的吧,过一段时间内建版本发布了,说不定这个例子也像rcnn一样看不到手撕的细节了(好吧,至少不那么容易)。
lstmfunction里面实现的是A Critical Review of Recurrent Neural Networks for Sequence Learning Page-20上的式子,并不是Felix Gers thesis Page-17上Figure 3.1描述的形式,关于这一点,前者在那页上有段注记:These equations give the full algorithm for a modern LSTM ...。我还是把式子打一遍吧...
\[
\begin{eqnarray}
g^{(t)} &=& \phi (W^{gx}x^{(t)} + W^{gh}h^{(t-1)} + b_g)\nonumber\i^{(t)} &=& \phi (W^{ix}x^{(t)} + W^{ih}h^{(t-1)} + b_i)\nonumber\f^{(t)} &=& \phi (W^{fx}x^{(t)} + W^{fh}h^{(t-1)} + b_f)\nonumber\o^{(t)} &=& \phi (W^{ox}x^{(t)} + W^{oh}h^{(t-1)} + b_o)\nonumber\s^{(t)} &=& g^{(t)}\odot i^{(t)} + s^{(t-1)}\odot f^{(t)}\nonumber\h^{(t)} &=& \phi (s^{(t)}) \odot o^{(t)}\nonumber
\end{eqnarray}
\]
可以观察到,每个非线性映射的输入变量都是相同的(\(x^{(t)},~h^{(t-1)}\)),对应到lstm function里面,i2h和h2h被直接加起来,然后再分为相应的gate参数。
Graph
说了这么些,再来看看最后生成的图是怎样的(图有些大,右键单独查看为好):
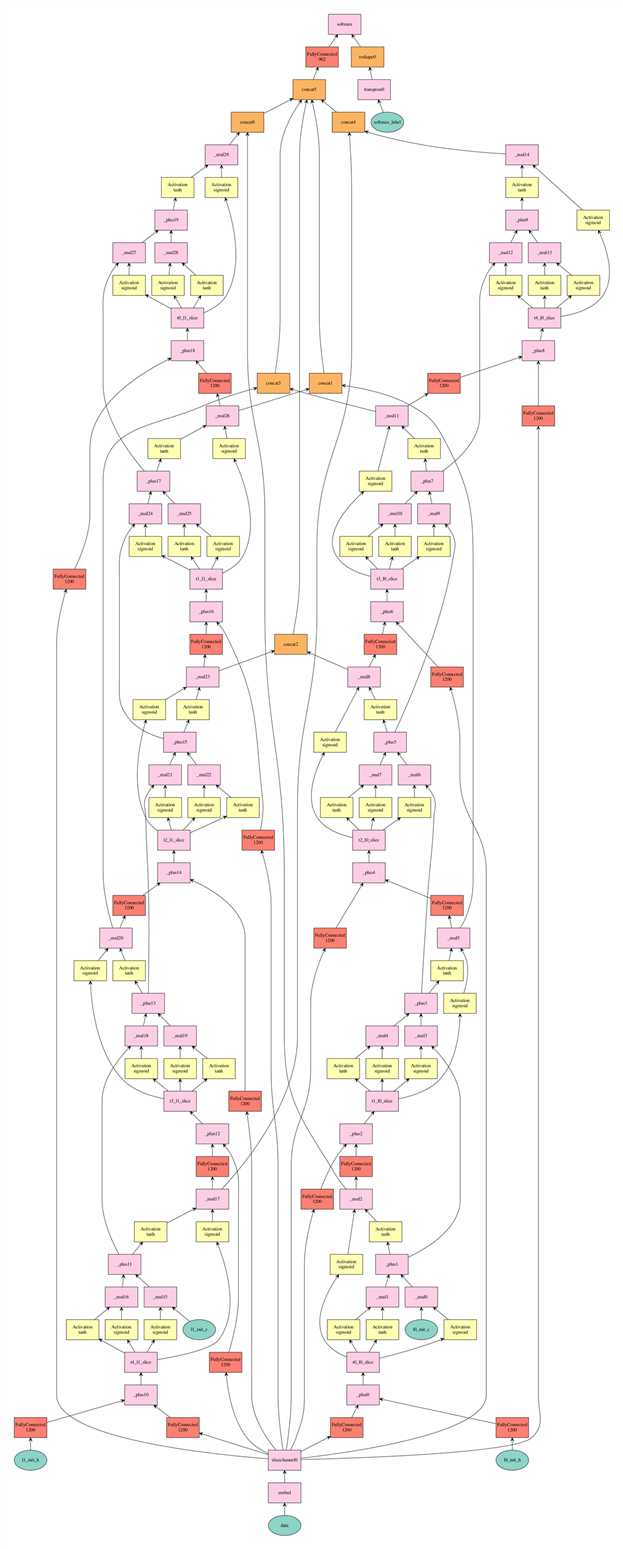
Figure 1. Graph of the LSTM for 5-length input
可以观察到,底层部分除了
data节点以外,还存在有青色节点,按照这个命名方式是不能被初始化的,在sort_io.py里面为这些节点提供了参数。
Note
最后在附上一个注记吧,程序虽然是以sort命名的,但从内容上看,这样的训练是将每个数字作为一个单词输入进去的,也就是说,测试的时候输入的数字序列也必须是训练时出现过的(没严格验证过,猜测啦)