在做机器学习时需要有数据进行训练,幸好sklearn提供了很多已经标注好的数据集供我们进行训练。
本节就来看看sklearn提供了哪些可供训练的数据集。
这些数据位于datasets中,网址为:http://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets
房价数据
加载波士顿房价数据,可以用于线性回归用:
sklearn.datasets.load_boston:http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html#sklearn.datasets.load_boston
加载方式为:
from sklearn.datasets import load_boston
boston = load_boston()
print(boston.data.shape)这个数据集的shape为:
(506, 13)也就是506行,13列,这里13列就是影响房价的13个属性,具体是哪些属性可以通过如下代码打印出来:
print(boston.feature_names)输出为:
[‘CRIM‘ ‘ZN‘ ‘INDUS‘ ‘CHAS‘ ‘NOX‘ ‘RM‘ ‘AGE‘ ‘DIS‘ ‘RAD‘ ‘TAX‘ ‘PTRATIO‘
‘B‘ ‘LSTAT‘]具体代表啥意思,要么自己猜,要么上网查吧,我不一一去解释了,我猜几个:RM:room数,也就是户型中的几房,AGE:age(房龄),不知道猜对不对,大家自己去实践了。
你说我咋知道这个数据集中有feature_names属性,我也不知道,我只是把上面的boston整个打印出来看到其中有这个属性的。
预测房价案例
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 加载房价数据
boston = load_boston()
data_X = boston.data
data_y = boston.target
# 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data_X, data_y, test_size=0.3)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 打印出预测的前5条房价数据
print("预测的前5条房价数据:")
print(model.predict(X_test)[:5])
# 打印出测试集中实际房价前5条数据
print("测试集中实际房价前5条数据:")
print(y_test[:5])输出:
预测的前5条房价数据:
[ 17.44807408 27.78251433 18.8344117 17.85437188 34.47632703]
测试集中实际房价前5条数据:
[ 14.3 22.3 22.6 20.6 34.9]以这个结果集中第一条数据为例,我们预测出某房子的价格是17.4万,而实际价格是14.3万。
不过说实话,上面的房价数据只能用于测试算法,我们真要预测房价的话,原始数据的获得没有那么全和规整,因此,在机器学习中,收集数据并清洗也是一个很重要的工作,脏活累活也必须得干,光有算法没啥用。
花的数据前面一个博文已经讲过了,这里就不再重复了。
手写数字识别数据
还有手写数字识别的,这个也很常用:http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html#sklearn.datasets.load_digits
创建样本数据
也可以生成一些虚拟的数据,这些是位于官网的API文档中Samples generator一节:
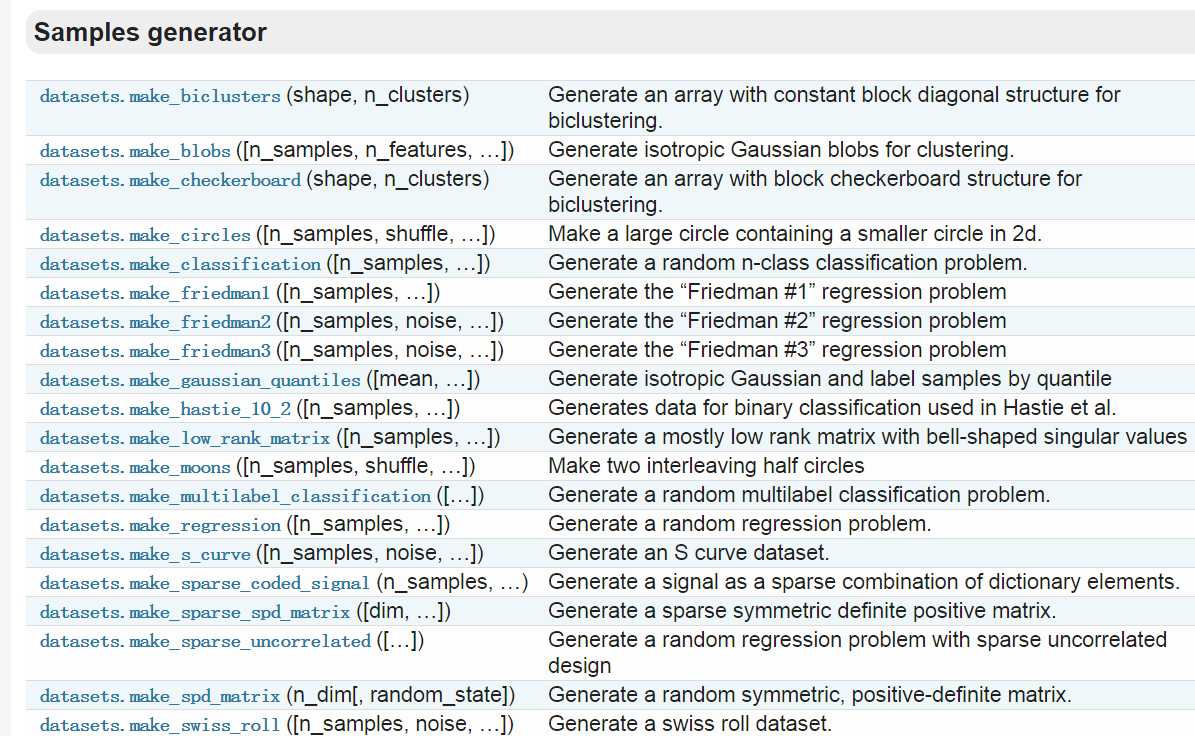
案例源代码为:
from sklearn.datasets import make_regression
import matplotlib.pyplot as plt
# 创建100个样本,1个属性值的数据,输出一个目标值,同时也设置了噪音
X, y = make_regression(n_samples=100, n_features=1, n_targets=1, noise=10)
print(X.shape)
print(y.shape)
# 对X,y画散点图,看看长啥模样的
plt.scatter(X, y)
plt.show()输出的数据为:
(100, 1)
(100,)也就是X值中有100行1列,y值是100行的值。
输出的图形为:
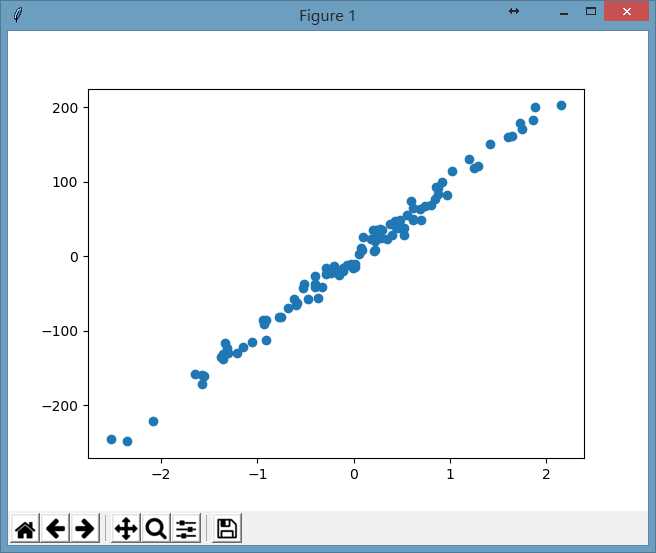
看起来接近一条直线。