正态分布变换(NDT)算法是一个配准算法,它应用于三维点的统计模型,使用标准最优化技术来确定两个点云间的最优的匹配,因为其在配准过程中不利用对应点的特征计算和匹配,所以时间比其他方法快。下面的公式推导和MATLAB程序编写都参考论文:The Normal Distributions Transform: A New Approach to Laser Scan Matching
先回顾一下算法推导和实现过程中涉及到的几个知识点:
-
协方差矩阵
在概率论和统计中,协方差是对两个随机变量联合分布线性相关程度的一种度量。对多维随机变量$\textbf X=[X_1, X_2, X_3, ..., X_n]^T$ ,我们往往需要计算各维度两两之间的协方差,这样各协方差组成了一个$n\times n$的矩阵,称为协方差矩阵。协方差矩阵是个对称矩阵,而且是半正定的(证明可以参考这里)。对角线上的元素是各维度上随机变量的方差。我们定义协方差矩阵为$\Sigma$,矩阵内的元素$\Sigma_{ij}$为$$\Sigma_{ij}=\operatorname{cov}(X_i,X_j)=\operatorname{E}\big[(X_i-\operatorname{E}[X_i])(X_j-\operatorname{E}[X_j])\big]$$
这样这个矩阵为$$\begin{align*}
\Sigma&=\operatorname{E}\big[(\textbf X-\operatorname{E}[\textbf X]\big)(\textbf X-\operatorname{E}[\textbf X])^T]\\
&=\begin{bmatrix}
\operatorname{cov}(X_1, X_1) &
\operatorname{cov}(X_1, X_2) &
\cdots &
\operatorname{cov}(X_1, X_n) \\
\operatorname{cov}(X_2, X_1) &
\operatorname{cov}(X_2, X_2) &
\cdots &
\operatorname{cov}(X_2, X_n) \\
\vdots &
\vdots &
\ddots &
\vdots \\
\operatorname{cov}(X_n, X_1) &
\operatorname{cov}(X_n, X_2) &
\cdots &
\operatorname{cov}(X_n, X_n)
\end{bmatrix}
\end{align*}$$
样本的协方差是样本集的一个统计量,可作为联合分布总体参数的一个估计,在实际中计算的通常是样本的协方差。样本的协方差矩阵与上面的协方差矩阵相同,只是矩阵内各元素以样本的协方差替换。样本集合为$\{\textbf x_{\cdot j}=[x_{1j},x_{2j},...,x_{nj}]^T|1\leqslant j\leqslant m\}$,$m$为样本数量,所有样本可以表示成一个$n \times m$的矩阵。我们以$\hat \Sigma$表示样本的协方差矩阵,与$\Sigma$区分。
$$\begin{align*}
\hat \Sigma&=\begin{bmatrix}
q_{11} & q_{12} & \cdots & q_{1n} \\
q_{21} & q_{21} & \cdots & q_{2n} \\
\vdots & \vdots & \ddots & \vdots \\
q_{n1} & q_{n2} & \cdots & q_{nn}
\end{bmatrix}\\
&=\frac {1}{m-1}
\begin{bmatrix}
{\sum_{j=1}^m{(x_{1j}-\bar x_1)(x_{1j}-\bar x_1)}} &
{\sum_{j=1}^m{(x_{1j}-\bar x_1)(x_{2j}-\bar x_2)}} &
\cdots &
{\sum_{j=1}^m{(x_{1j}-\bar x_1)(x_{nj}-\bar x_n)}} \\
{\sum_{j=1}^m{(x_{2j}-\bar x_2)(x_{1j}-\bar x_1)}} &
{\sum_{j=1}^m{(x_{2j}-\bar x_2)(x_{2j}-\bar x_2)}} &
\cdots &
{\sum_{j=1}^m{(x_{2j}-\bar x_2)(x_{nj}-\bar x_n)}} \\
\vdots &
\vdots &
\ddots &
\vdots \\
{\sum_{j=1}^m{(x_{nj}-\bar x_n)(x_{1j}-\bar x_1)}} &
{\sum_{j=1}^m{(x_{nj}-\bar x_n)(x_{2j}-\bar x_2)}} &
\cdots &
{\sum_{j=1}^m{(x_{nj}-\bar x_n)(x_{nj}-\bar x_n)}}
\end{bmatrix}\\
&=\frac {1}{m-1} \sum_{j=1}^m (\textbf x_{\cdot j} - \bar {\textbf x}) (\textbf x_{\cdot j} - \bar {\textbf x})^T
\end{align*}$$
公式中$m$为样本数量,$\bar{\textbf x}$为样本均值,是一个列向量。$\textbf x_{\cdot j}$为第$j$个样本,也是一个列向量。
-
多元正态分布
若随机向量的概率密度函数为$$\begin{align*}
f_{\textbf x}(x_1,...,x_k)&=\frac{exp(-\frac{1}{2}(\mathbf x- \mu)^T \Sigma^{-1}(\textbf x-\mu))}{\sqrt{(2\pi)^k|\Sigma|}}\\
&=\frac{exp(-\frac{1}{2}(\mathbf x- \mu)^T \Sigma^{-1}(\textbf x-\mu))}{\sqrt{|2\pi\Sigma|}}
\end{align*}$$
则称$\textbf x$服从$k$元正态分布,记作$\textbf x \sim N_k(\mu, \Sigma)$,其中$\textbf x$是一个$k$维列向量,参数$\mu$和$\Sigma$分别为$\textbf x$的均值和协方差矩阵,$|\Sigma|=det\Sigma$是协方差矩阵的行列式(Determinant)。
二维正态分布概率密度函数为钟形曲面,等高线是椭圆线族,并且二维正态分布的两个边缘分布都是一维正态分布的形式:$$f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}} \quad ,-\infty<x<\infty$$
下面是服从$\mu=\begin{bmatrix}0\\ 0\end{bmatrix}$,$\Sigma=\begin{bmatrix}1 & 3/5\\ 3/5 & 2\end{bmatrix}$二维正态分布的概率密度及两个边缘分布的概率密度图:
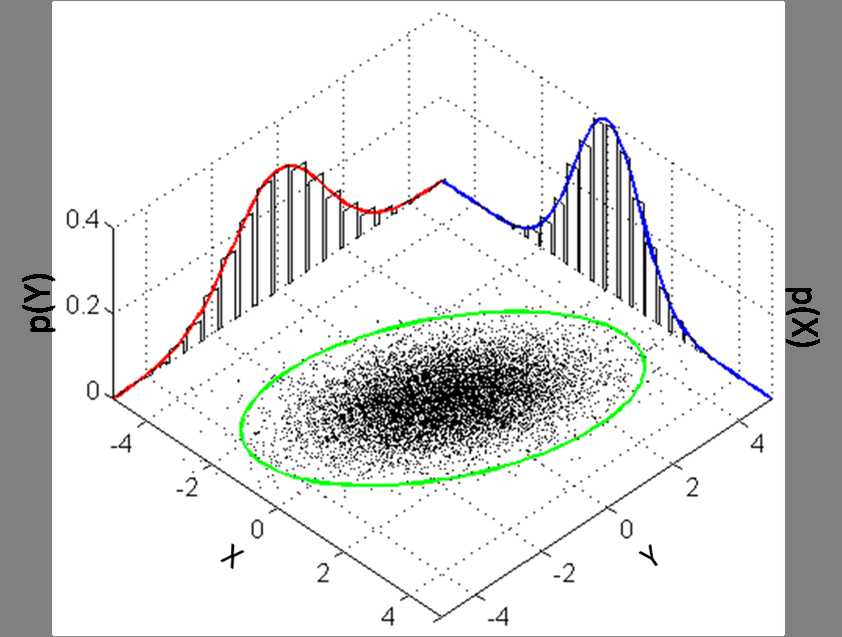
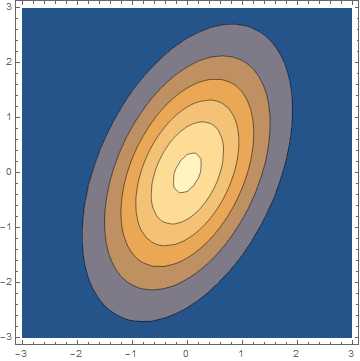
用Mathematica可以画出二维正态分布概率密度函数的等高线:
ContourPlot[PDF[MultinormalDistribution[{0, 0}, {{1, 3/5}, {3/5, 2}}], {x, y}], {x, -3, 3}, {y, -3, 3}]
可以看出等高线是一族椭圆线:
也可以使用Python的FilterPy(Kalman filters and other optimal and non-optimal estimation filters in Python)库来计算多元正态分布概率密度,首先用pip安装filterpy
pip install filterpy
下面的代码计算x=[1.2, 2.5]处的概率密度


from filterpy.stats import multivariate_gaussian x = [1.2, 2.5] mu = [0, 0] cov = [[1,0.6],[0.6,2]] pdf = multivariate_gaussian(x, mu, cov) # output is 0.02302
协方差矩阵描述了随机点的概率密度的分布情况,颜色越深的地方表示概率密度值越大
import matplotlib.pyplot as plt import numpy as np import scipy.stats def plot_cov_ellipse_colormap(cov=[[1,1],[1,1]]): side = np.linspace(-3, 3, 200) X,Y = np.meshgrid(side,side) pos = np.empty(X.shape + (2,)) pos[:, :, 0] = X; pos[:, :, 1] = Y plt.axes(xticks=[], yticks=[], frameon=True) rv = scipy.stats.multivariate_normal((0,0), cov) plt.gca().grid(b=False) plt.gca().imshow(rv.pdf(pos), cmap=plt.cm.Greys, origin=‘lower‘) plt.show() plot_cov_ellipse_colormap(cov=[[1, 0.6], [0.6, 2]])

-
向量求导
$x$为列向量,$A$是一个矩阵,则有:$$\frac{dAx}{dx}=A, \quad \frac{d(x^TAx)}{dx}=x^T(A^T+A)$$
-
多元函数的泰勒展开式
多元目标函数可能是很复杂的函数,为了便于研究函数极值问题,必须用简单函数作局部逼近,通常采用泰勒展开式作为函数在某点附近的表达式。
由高等数学知识可知,对于一元函数$f(x)$在$k$点,即$x=x^{(k)}$的泰勒展开式为:$$f(x)=f(x^{(k)})+{f}‘(x^{(k)})(x-x^{(k)})+\frac{1}{2!}{f}‘‘(x^{(k)})(x-x^{(k)})^2+...+\frac{1}{n!}f^{(n)}(x^{(k)})(x-x^{(k)})^n+R_n$$
式中的余项$R_n$为$$R_n=\frac{1}{(n+1)!}f^{(n+1)}(\xi)(x-x^{(k)})^{(n+1)}$$
$\xi$在$x$、$x^{(k)}$之间。在$x^{(k)}$点充分小的邻域内,余项$R_n$的极限为零,因此可以用多项式来逼近函数$f(x)$。
二元函数的泰勒展开式可由一元函数泰勒展开推广得到。
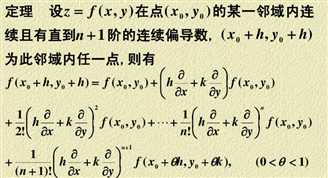
函数$f(X)=f(x_1,x_2)$在点$X^{(k)}=(x_{1}^{(k)},x_{2}^{(k)})$附近的泰勒展开,若只取到二次项可写为\begin{align*}
f(X)\approx &f(X^{(k)})+\frac{\partial f}{\partial x_1}\bigg|_{X=X^{(k)}} (x_1-x_{1}^{(k)})+\frac{\partial f}{\partial x_2}\bigg|_{X=X^{(k)}} (x_2-x_{2}^{(k)})\\ &+\frac{1}{2!} \left[\frac{\partial^2 f}{\partial x_1^2}\bigg|_{X=X^{(k)}}(x_1-x_{1}^{(k)})^2+ 2 \frac{\partial^2 f}{\partial x_1 \partial x_2 }\bigg|_{X=X^{(k)}}(x_1-x_{1}^{(k)})(x_2-x_{2}^{(k)})+\frac{\partial^2 f}{\partial x_2^2}\bigg|_{X=X^{(k)}}(x_2-x_{2}^{(k)})^2 \right]
\end{align*}
上式可写成矩阵形式,即$$f(X)\approx f(X^{(k)})+\left(\frac{\partial f}{\partial x_1},\frac{\partial f}{\partial x_2} \right )\begin{pmatrix}
x_1-x_1^{(k)}\\ x_2-x_2^{(k)})\end{pmatrix}+\frac{1}{2}(x_1-x_1^{(k)},x_2-x_2^{(k)})\begin{pmatrix}
\frac{\partial^2f }{\partial x_1^2} & \frac{\partial^2f }{\partial x_1 \partial x_2}\\ \frac{\partial^2f }{\partial x_1 \partial x_2} & \frac{\partial^2f }{\partial x_2^2}\end{pmatrix}\begin{pmatrix}
x_1-x_1^{(k)}\\ x_2-x_2^{(k)})\end{pmatrix}$$
式中$\left(\frac{\partial f}{\partial x_1},\frac{\partial f}{\partial x_2} \right )={\nabla f}$,$\begin{pmatrix}x_1-x_1^{(k)}\\ x_2-x_2^{(k)})\end{pmatrix}=X-X^{(k)}$,$\nabla^2 f=\begin{pmatrix}\frac{\partial^2f }{\partial x_1^2} & \frac{\partial^2f }{\partial x_1 \partial x_2}\\ \frac{\partial^2f }{\partial x_1 \partial x_2} & \frac{\partial^2f }{\partial x_2^2}\end{pmatrix}$
$\nabla^2f$是函数$f(X)$在$X^{(k)}$点的二阶偏导数矩阵,称为海塞(Hessian)矩阵,可以用$H(X)$表示,Hessian矩阵是对称矩阵。引用上述符号后,二元函数泰勒展开式可简写为$$f(X)\approx f(X^{(k)}) +\nabla f(X^{(k)})(X-X^{(k)})+\frac{1}{2}(X-X^{(k)})^T H(X^{(k)})(X-X^{(k)})$$
-
无约束优化中的牛顿法
牛顿法是梯度法的进一步发展,梯度法在确定搜索方向时只考虑目标函数在选择迭代点的局部性质,即利用一阶偏导数的信息,而牛顿法进一步利用了目标函数的二阶偏导数,考虑了梯度的变化趋势,因而可更全面地确定合适的搜索方向,以便更快地搜索到极小点。
以一维问题来说明牛顿法的过程。设已知一维目标函数$f(x)$的初始点$A(x^{(k)},f(x^{{k}}))$,过$A$点做一与原目标函数$f(x)$相切的二次曲线$\varphi(x)$,求抛物线的极小点的坐标$x^{(k+1)}$,将$x^{(k+1)}$代入原目标函数$f(x)$,求得$f(x^{(k+1)})$得到$B$点。过$B$点再做一条与$f(x)$相切的二次曲线,得到下一个最小点$x^{(k+2)}$,解得$C$点。重复做下去直到找到原目标函数的极小点的坐标$x^*$为止,如下图所示。
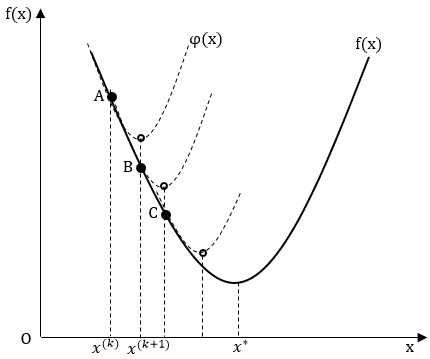
在逼近的过程中所用的二次函数是以原目标函数在迭代点附近的泰勒展开式的二次项。一维目标函数$f(x)$在$x^{(k)}$点逼近所用的二次函数为:$$\varphi(x)=f(x^{(k)}) +{f}‘(x^{(k)})(x-x^{(k)})+\frac{1}{2}{f}‘‘(x^{(k)})(x-x^{(k)})^2$$
该二次函数的极小点可由极值存在的必要条件${\varphi}‘(x^{(k)})=0$求得,也即求得$x^{(k+1)}$
把上述过程推广到$n$维问题,即是$$\varphi(X)=f(X^{(k)}) +\nabla f(X^{(k)})(X-X^{(k)})+\frac{1}{2}(X-X^{(k)})^T H(X^{(k)})(X-X^{(k)})$$
当$\nabla \varphi(X)=0$时,可求得二次函数$\varphi(X)$的极值点,对上式矩阵方程求导,可得到$$\nabla \varphi(X)=\nabla f(X^{(k)})+ H(X^{(k)})(X-X^{(k)})=0$$
若$H(X^{(k)})$为可逆矩阵,从而得到这次逼近的二次函数的最小点$X^{(k+1)}$ $$X = X^{(k)}- H(X^{(k)})^{-1}\nabla f(X^{(k)})$$
在每次逼近的极小点可由上式计算出。由于$\varphi(X)$是$f(X)$的一个近似表达式,所求得的极小点$X^*$并不是目标函数真正的极小点。只有当目标函数$f(X)$本身是二次函数时,所求的极小点$X^*$才是目标函数的真正极小点,这种情况一次迭代就可以求出目标函数的极值点。
在一般情况下,$f(X)$不一定是二次函数,为了求得$f(X)$的极小值,可以把由上式求得的$X$作为下一个迭代点,通过反复循环迭代,不断逼近到$f(X)$的极小点。于是得到牛顿法的迭代格式为:$$X^{(k+1)} = X^{(k)}- H(X^{(k)})^{-1}\nabla f(X^{(k)})$$
或者写成$$X^{(k+1)} = X^{(k)}+\alpha_k S^{(k)}$$
式中,$S^{(k)}=- H(X^{(k)})^{-1}\nabla f(X^{(k)})$称为牛顿搜索方向;$\alpha_k=1$.
牛顿法主要缺点是每次迭代过程都要计算函数二阶导数矩阵(Hessian矩阵),并且要对该矩阵求逆。这样工作量相当大,特别是矩阵求逆计算,当设计变量维数较高时工作量更大。因此,牛顿法很少被直接采用,但是对于那些容易计算一阶导数和海塞矩阵及其逆的二次函数采用牛顿法还是很方便的。
-
数值计算中的病态问题与条件数
求解过程涉及到计算协方差矩阵$\Sigma$的逆,理论上没什么问题,但是实际中可能出现$\Sigma$接近奇异的情况。对于一个数值问题本身如果输入数据有微小扰动(即误差),引起输出数据(即问题解)相对误差很大,这就是病态问题。在计算机上解线性方程组或计算矩阵的逆时要分析问题是否病态,例如解线性方程组,如果输入数据有微小误差引起解的巨大误差,就认为是病态方程组。
条件数定义:$cond(A)=\left \| A \right \|_p \left \| A^{-1} \right \|_p$,$\left \| \cdot \right \|_p $表示矩阵$A$的某种范数,若矩阵$A$的条件数较大,则称$A$为病态矩阵。
矩阵$A=(a_{ij})_{m \times n}$有3种常见的范数:
1-范数: $ \left \| A \right \|_1= \mathop {\min }\limits_{1\leq j \leq n}\sum_{i=1}^{m}\left |a_{ij} \right |$ (列和范数,A每一列元素绝对值之和的最大值)
∞-范数:$\left \| A \right \|_\infty= \mathop {\min }\limits_{1\leq i \leq m}\sum_{j=1}^{n}\left |a_{ij} \right |$ (行和范数,A每一行元素绝对值之和的最大值)
2-范数:$\left \| A \right \|_2= \sqrt{\lambda_{max}}$ ,$\lambda_{max}$是矩阵$A^TA$的最大特征值,也称为谱范数
根据上面的定义,矩阵的谱条件数为$$cond(A)_2=\left \| A \right \|_2 \left \| A^{-1} \right \|_2=\sqrt{\frac{\lambda_{max}(A^TA)}{\lambda_{min}(A^TA)}}$$
当$A$为对称矩阵时$$cond(A)_2=\frac{|\lambda_1|}{|\lambda_n|}$$
其中$\lambda_1$,$\lambda_n$为$A$的绝对值最大和最小的特征值。
若条件数$cond(A)$较小(接近1),就称$A$关于求逆矩阵或解线性方程组为良态的;若条件数$cond(A)$较大,就称$A$关于求逆矩阵或解线性方程组为病态的。当矩阵$A$十分病态时,就说明$A$已十分接近一个奇异矩阵。要判别一个矩阵是否病态需要计算条件数$cond(A)=\left \| A \right \| \left \| A^{-1} \right \|$,而计算$A^{-1}$是比较费劲的,那么在实际中如何发现病态情况呢?通常来说,如果系数矩阵的行列式值相对很小,或系数矩阵某些行近似线性相关,这时$A$可能病态。或者矩阵$A$元素间数量级相差很大,并且无一定规则,$A$可能病态。
例如矩阵$A=\begin{pmatrix}1 & 2\\ 2.001 & 4\end{pmatrix}$,可以看出矩阵的第一行和第二行非常接近线性相关(矩阵接近奇异)。用MATALB中的inv函数求逆,结果为[[-2000, 1000], [1000.5, -500]],如果将$A$中的元素2.001改为2.002,此时求逆的结果为[[-1000, 500], [500.5, -250]],可以看出微小的扰动引起结果巨大的变化。
通过SVD分解来计算矩阵$A$的奇异值
[u, s, v] = svd(A)
结果为:
s =
5.0004 0
0 0.0004
则矩阵$A$的谱条件数为$cond(A)_2=\frac{5.0004}{0.0004}=12502\gg 1$,可以看出矩阵$A$非常病态。
基于数值计算的考虑,计算协方差矩阵的逆$\Sigma^{-1}$之前,可以先用奇异值分解来检查矩阵是否接近奇异。如果最大奇异值比最小的大1000倍以上(条件数大于1000),则将条件数限制在1000,用此时对应的协方差矩阵求逆。
% Prevent covariance matrix from going singular (and not be invertible)
[U, S, V] = svd(xyCov);
if S(2,2) < 0.001 * S(1,1)
S(2,2) = 0.001 * S(1,1);
xyCov = U * S * V‘;
end
NDT算法
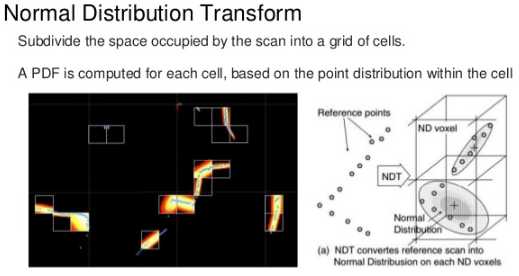
NDT算法的基本思想是先根据参考数据(reference scan)来构建多维变量的正态分布,如果变换参数能使得两幅激光数据匹配的很好,那么变换点在参考系中的概率密度将会很大。因此,可以考虑用优化的方法求出使得概率密度之和最大的变换参数,此时两幅激光点云数据将匹配的最好。
算法的基本步骤如下:
1. 将参考点云(reference scan)所占的空间划分成指定大小(CellSize)的网格或体素(Voxel);并计算每个网格的多维正态分布参数:
-
- 均值 $\textbf q=\frac{1}{n}\sum_i \textbf{x}_i$
- 协方差矩阵 $\Sigma=\frac{1}{n}\sum_i(\textbf{x}_i-\textbf q)(\textbf{x}_i-\textbf q)^T$
2. 初始化变换参数$\textbf p=(t_x,t_y,\phi)^T$(赋予零值或者使用里程计数据赋值)
3. 对于要配准的点云(second scan),通过变换$T$将其转换到参考点云的网格中$\textbf x_i‘=T(\textbf x_i, \textbf p)$ $$T:\begin{pmatrix}x‘\\ y‘\end{pmatrix}=\begin{pmatrix}cos\phi & -sin\phi\\ sin\phi & cos\phi\end{pmatrix}\begin{pmatrix}x\\ y\end{pmatrix}+\begin{pmatrix}t_x\\t_y\end{pmatrix}$$
4. 根据正态分布参数计算每个转换点的概率密度$$p(\textbf x)\sim exp(-\frac{(\textbf x-\textbf q)^T\Sigma^{-1}(\textbf x- \textbf q)}{2})$$
5. NDT配准得分(score)通过对每个网格计算出的概率密度相加得到$$score(\textbf p)= \sum_i exp(-\frac{(\textbf {x}_i‘-\textbf q_i)^T\Sigma_i^{-1}(\textbf {x}_i‘-\textbf q_i)}{2})$$
6. 根据牛顿优化算法对目标函数$-score$进行优化,即寻找变换参数$\textbf p$使得$score$的值最大。优化的关键步骤是要计算目标函数的梯度和Hessian矩阵:
目标函数$-score$由每个格子的值$s$累加得到,令$\textbf q=\textbf x_i‘-\textbf q_i$,则 $$s=-exp(\frac{-\textbf q^T \Sigma^{-1} \textbf q}{2})$$
根据链式求导法则以及向量、矩阵求导的公式,$s$梯度方向为$$\frac{\partial s}{\partial p_i}= \frac{\partial s}{\partial q}\frac{\partial q}{\partial p_i} = \textbf q^T \Sigma^{-1} \frac{\partial q}{\partial p_i}exp(\frac{-\textbf q^T \Sigma^{-1} \textbf q}{2})$$
其中$\textbf q$对变换参数$p_i$的偏导数$\frac{\partial q}{\partial p_i}$即为变换$T$的雅克比矩阵:$$\frac{\partial q}{\partial p_i}=\textbf J_T=\begin{pmatrix}
1 & 0 & -xsin\phi-ycos\phi\\
0 & 1 & xcos\phi-ysin\phi
\end{pmatrix}$$
根据上面梯度的计算结果,继续求$s$关于变量$p_i$、$p_j$的二阶偏导:
$$\begin{align*} H_{ij}&=\frac{\partial^2 s}{\partial p_i \partial p_j}= \partial(\frac{\partial s}{\partial p_i})/\partial p_j=\partial(\textbf q^T \Sigma^{-1} \frac{\partial \textbf q}{\partial p_i}exp(\frac{-\textbf q^T \Sigma^{-1} \textbf q}{2}))/\partial p_j\\
&=\partial(\textbf q^T \Sigma^{-1} \frac{\partial \textbf q}{\partial p_i})/\partial p_j)exp(\frac{-\textbf q^T \Sigma^{-1} \textbf q}{2})+ (\textbf q^T \Sigma^{-1} \frac{\partial \textbf q}{\partial p_i})(\partial exp(\frac{-\textbf q^T \Sigma^{-1} \textbf q}{2})/ \partial p_j)\\
&=-exp(\frac{-\textbf q^T \Sigma^{-1} \textbf q}{2})\left[(\textbf q^T\Sigma^{-1}\frac{\partial \textbf q}{\partial p_i})(\textbf q^T\Sigma^{-1}\frac{\partial \textbf q}{\partial p_j})-(\frac{\partial \textbf q^T}{\partial p_j}\Sigma^{-1}\frac{\partial \textbf q}{\partial p_i})-(\textbf q^T \Sigma^{-1}\frac{\partial^2 \textbf q}{\partial p_i\partial p_j})\right]\end{align*}$$
根据变换方程,向量$\textbf q$对变换参数$p$的二阶导数的向量为:
$$\frac{\partial^2 \textbf q}{\partial p_i\partial p_j}=\left\{\begin{matrix}
\begin{pmatrix}
-xcos\phi+ysin\phi\\
-xsin\phi-ycos\phi
\end{pmatrix} & i=j=3\\
\begin{pmatrix}
0 \\ 0\end{pmatrix}& otherwise
\end{matrix}\right.$$
7. 跳转到第3步继续执行,直到达到收敛条件为止
NDT算法的MATLAB实现
preNDT函数将激光数据点划分到指定大小的网格中:
function [xgridcoords, ygridcoords] = preNDT(laserScan, cellSize)
%preNDT Calculate cell coordinates based on laser scan
% [XGRIDCOORDS, YGRIDCOORDS] = preNDT(LASERSCAN, CELLSIZE) calculated the x
% (XGRIDCOORDS) and y (YGRIDCOORDS) coordinates of the cell center points that are
% used to discretize the given laser scan.
%
% Inputs:
% LASERSCAN - N-by-2 array of 2D Cartesian points
% CELLSIZE - Defines the side length of each cell used to build NDT.
% Each cell is square
%
% Outputs:
% XGRIDCOORDS - 4-by-K, the discretized x coordinates using cells with size
% equal to CELLSIZE.
% YGRIDCOORDS: 4-by-K, the discretized y coordinates using cells with size
% equal to CELLSIZE.
xmin = min(laserScan(:,1));
ymin = min(laserScan(:,2));
xmax = max(laserScan(:,1));
ymax = max(laserScan(:,2));
halfCellSize = cellSize/2;
lowerBoundX = floor(xmin/cellSize)*cellSize-cellSize;
upperBoundX = ceil(xmax/cellSize)*cellSize+cellSize;
lowerBoundY = floor(ymin/cellSize)*cellSize-cellSize;
upperBoundY = ceil(ymax/cellSize)*cellSize+cellSize;
% To minimize the effects of discretization,use four overlapping
% grids. That is, one grid with side length cellSize of a single cell is placed
% first, then a second one, shifted by cellSize/2 horizontally, a third
% one, shifted by cellSize/2 vertically and a fourth one, shifted by
% cellSize/2 horizontally and vertically.
xgridcoords = [ lowerBoundX:cellSize:upperBoundX;... % Grid of cells in position 1
lowerBoundX+halfCellSize:cellSize:upperBoundX+halfCellSize;... % Grid of cells in position 2 (X Right, Y Same)
lowerBoundX:cellSize:upperBoundX; ... % Grid of cells in position 3 (X Same, Y Up)
lowerBoundX+halfCellSize:cellSize:upperBoundX+halfCellSize]; % Grid of cells in position 4 (X Right, Y Up)
ygridcoords = [ lowerBoundY:cellSize:upperBoundY;... % Grid of cells in position 1
lowerBoundY:cellSize:upperBoundY;... % Grid of cells in position 2 (X Right, Y Same)
lowerBoundY+halfCellSize:cellSize:upperBoundY+halfCellSize;... % Grid of cells in position 3 (X Same, Y Up)
lowerBoundY+halfCellSize:cellSize:upperBoundY+halfCellSize]; % Grid of cells in position 4 (X Right, Y Up)
end
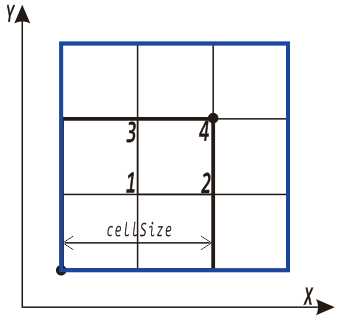
为了减小离散化的影响,用4个尺寸都为cellSize的相互重叠的小格子组成一个大格子(下面示意图中蓝色边框的格子)来计算目标函数值等信息。将左下角的第1个小格子向右平移cellSize/2个单位得到第2个小格子;将第1个小格子向上平移cellSize/2个单位得到第3个小格子;将第1个小格子向右、向上平移cellSize/2个单位得到第4个小格子:
buildNDT函数根据划分好的网格,来计算每一个小格子中的二维正态分布参数(均值、协方差矩阵以及协方差矩阵的逆):
function [xgridcoords, ygridcoords, meanq, covar, covarInv] = buildNDT(laserScan, cellSize)
%buildNDT Build Normal Distributions Transform from laser scan
% [XGRIDCOORDS, YGRIDCOORDS, MEANQ, COVAR, COVARINV] = buildNDT(LASERSCAN, CELLSIZE)
% discretizes the laser scan points into cells and approximates each cell
% with a Normal distribution.
%
% Inputs:
% LASERSCAN - N-by-2 array of 2D Cartesian points
% CELLSIZE - Defines the side length of each cell used to build NDT.
% Each cell is a square area used to discretize the space.
%
% Outputs:
% XGRIDCOORDS - 4-by-K, the discretized x coordinates of the grid of cells,
% with each cell having a side length equal to CELLSIZE.
% Note that K increases when CELLSIZE decreases.
% The second row shifts the first row by CELLSIZE/2 to
% the right. The third row shifts the first row by CELLSIZE/2 to the
% top. The fourth row shifts the first row by CELLSIZE/2 to the right and
% top. The same row semantics apply to YGRIDCOORDS, MEANQ, COVAR, and COVARINV.
% YGRIDCOORDS: 4-by-K, the discretized y coordinates of the grid of cells,
% with each cell having a side length equal to CELLSIZE.
% MEANQ: 4-by-K-by-K-by-2, the mean of the points in cells described by
% XGRIDCOORDS and YGRIDCOORDS.
% COVAR: 4-by-K-by-K-by-2-by-2, the covariance of the points in cells
% COVARINV: 4-by-K-by-K-by-2-by-2, the inverse of the covariance of
% the points in cells.
%
% [XGRIDCOORDS, YGRIDCOORDS, MEANQ, COVAR, COVARINV] describe the NDT statistics.
% Copyright 2016 The MathWorks, Inc.
% When the scan contains ONLY NaN values (no valid range readings),
% the input laserScan is empty. Explicitly
% initialize empty variables to support code generation.
if isempty(laserScan)
xgridcoords = zeros(4,0);
ygridcoords = zeros(4,0);
meanq = zeros(4,0,0,2);
covar = zeros(4,0,0,2,2);
covarInv = zeros(4,0,0,2,2);
return;
end
% Discretize the laser scan into cells
[xgridcoords, ygridcoords] = preNDT(laserScan, cellSize);
xNumCells = size(xgridcoords,2);
yNumCells = size(ygridcoords,2);
% Preallocate outputs
meanq = zeros(4,xNumCells,yNumCells,2);
covar = zeros(4,xNumCells,yNumCells,2,2);
covarInv = zeros(4,xNumCells,yNumCells,2,2);
% For each cell, compute the normal distribution that can approximately
% describe the distribution of the points within the cell.
for cellShiftMode = 1:4
% Find the points in the cell
% First find all points in the xgridcoords and ygridcoords separately and then combine the result.
% indx的值表示laserScan的x坐标分别在xgridcoords划分的哪个范围中(例如1就表示落在第1个区间;若不在范围中,则返回0)
[~, indx] = histc(laserScan(:,1), xgridcoords(cellShiftMode, :));
[~, indy] = histc(laserScan(:,2), ygridcoords(cellShiftMode, :));
for i = 1:xNumCells
xflags = (indx == i); % xflags is a logical vector
for j = 1:yNumCells
yflags = (indy == j);
xyflags = logical(xflags .* yflags);
xymemberInCell = laserScan(xyflags,:); % laser points in the cell
% If there are more than 3 points in the cell, compute the
% statistics. Otherwise, all statistics remain zero.
% See reference [1], section III.
if size(xymemberInCell, 1) > 3
% Compute mean and covariance
xymean = mean(xymemberInCell);
xyCov = cov(xymemberInCell, 1);
% Prevent covariance matrix from going singular (and not be
% invertible). See reference [1], section III.
[U,S,V] = svd(xyCov);
if S(2,2) < 0.001 * S(1,1)
S(2,2) = 0.001 * S(1,1);
xyCov = U*S*V‘;
end
[~, posDef] = chol(xyCov);
if posDef ~= 0
% If the covariance matrix is not positive definite,
% disregard the contributions of this cell.
continue;
end
% Store statistics
meanq(cellShiftMode,i,j,:) = xymean;
covar(cellShiftMode,i,j,:,:) = xyCov;
covarInv(cellShiftMode,i,j,:,:) = inv(xyCov);
end
end
end
end
end
objectiveNDT函数根据变换参数计算目标函数值及其梯度和Hessian矩阵,objectiveNDT的输出参数将作为目标函数信息传入优化函数中:
function [score, gradient, hessian] = objectiveNDT(laserScan, laserTrans, xgridcoords, ygridcoords, meanq, covar, covarInv)
%objectiveNDT Calculate objective function for NDT-based scan matching
% [SCORE, GRADIENT, HESSIAN] = objectiveNDT(LASERSCAN, LASERTRANS, XGRIDCOORDS,
% YGRIDCOORDS, MEANQ, COVAR, COVARINV) calculates the NDT objective function by
% matching the LASERSCAN transformed by LASERTRANS to the NDT described
% by XGRIDCOORDS, YGRIDCOORDS, MEANQ, COVAR, and COVARINV.
% The NDT score is returned in SCORE, along with the optionally
% calculated score GRADIENT, and score HESSIAN.
% Copyright 2016 The MathWorks, Inc.
% Create rotation matrix
theta = laserTrans(3);
sintheta = sin(theta);
costheta = cos(theta);
rotm = [costheta -sintheta;
sintheta costheta];
% Create 2D homogeneous transform
trvec = [laserTrans(1); laserTrans(2)];
tform = [rotm, trvec
0 0 1];
% Create homogeneous points for laser scan
hom = [laserScan, ones(size(laserScan,1),1)];
% Apply homogeneous transform
trPts = hom * tform‘; % Eqn (2)
% Convert back to Cartesian points
laserTransformed = trPts(:,1:2);
hessian = zeros(3,3);
gradient = zeros(3,1);
score = 0;
% Compute the score, gradient and Hessian according to the NDT paper
for i = 1:size(laserTransformed,1) % 对每一个转换点进行处理
xprime = laserTransformed(i,1);
yprime = laserTransformed(i,2);
x = laserScan(i,1);
y = laserScan(i,2);
% Eqn (11)
jacobianT = [1 0 -x*sintheta - y*costheta;
0 1 x*costheta - y*sintheta];
% Eqn (13)
qp3p3 = [-x*costheta + y*sintheta;
-x*sintheta - y*costheta];
for cellShiftMode = 1:4
[~,m] = histc(xprime, xgridcoords(cellShiftMode, :)); % 转换点落在(m,n)格子中
[~,n] = histc(yprime, ygridcoords(cellShiftMode, :));
if m == 0 || n == 0
continue
end
meanmn = reshape(meanq(cellShiftMode,m,n,:),2,1);
covarmn = reshape(covar(cellShiftMode,m,n,:,:),2,2);
covarmninv = reshape(covarInv(cellShiftMode,m,n,:,:),2,2);
if ~any([any(meanmn), any(covarmn)])
% Ignore cells that contained less than 3 points
continue
end
% Eqn (3)
q = [xprime;yprime] - meanmn;
% As per the paper, this term should represent the probability of
% the match of the point with the specific cell
gaussianValue = exp(-q‘*covarmninv*q/2);
score = score - gaussianValue;
for j = 1:3
% Eqn (10)
gradient(j) = gradient(j) + q‘*covarmninv*jacobianT(:,j)*gaussianValue;
% Eqn (12)
qpj = jacobianT(:,j);
for k = j:3 % Hessian矩阵为对称矩阵,只需要计算对角线上的部分
qpk = jacobianT(:,k);
if j == 3 && k == 3
hessian(j,k) = hessian(j,k) + gaussianValue*(-(q‘*covarmninv*qpj)*(q‘*covarmninv*qpk) +(q‘*covarmninv*qp3p3) + (qpk‘*covarmninv*qpj));
else
hessian(j,k) = hessian(j,k) + gaussianValue*(-(q‘*covarmninv*qpj)*(q‘*covarmninv*qpk) + (qpk‘*covarmninv*qpj));
end
end
end
end
end
% 补全Hessian矩阵
for j = 1:3
for k = 1:j-1
hessian(j,k) = hessian(k,j);
end
end
score = double(score);
gradient = double(gradient);
hessian = double(hessian);
end
最后,可以利用MATLAB中的优化函数来计算最优变换参数。具体使用方法可以参考:fminunc(Find minimum of unconstrained multivariable function) 以及 Including Gradients and Hessians.
以上过程就是MATLAB Robotics System Toolbox工具箱中的函数matchScans的主要内容。matchScans函数用于匹配两帧激光雷达数据,输出两帧之间的姿态变换。
参考:
多元正态分布(Multivariate normal distribution)
The Normal Distributions Transform: A New Approach to Laser Scan Matching