原文链接:https://www.cnblogs.com/zhaowei303/articles/4204805.html
SQL数据库中数据处理时,有时候需要建立临时表,将查询后的结果集放到临时表中,然后在针对这个数据进行操作。
创建“临时表”(逻辑上的临时表,可能不一定是数据库的)的方法有一下几种:
1.with tempTableName as方法(05之后出现):
with temptable as 其实并没有建立临时表,只是子查询部分(subquery factoring),定义一个SQL片断,该SQL片断会被整个SQL语句所用到。有的时候,是为了让SQL语句的可读性更高些,也有可能是在UNION ALL的不同部分,作为提供数据的部分。特别对于UNION ALL比较有用。因为UNION ALL的每个部分可能相同,但是如果每个部分都去执行一遍的话,则成本太高,所以可以使用WITH AS短语,则只要执行一遍即可。
示例:

with Snd
as
(
select * from category
where cgtype=2
and parentid=@FstCgid
),
thrd
as
(
select c.* from category c
inner join Snd s
on c.parentid=s.cgid
and c.cgtype=3
),
forth
as
(
select c.* from category c
inner join thrd t
on c.parentid=t.cgid
and c.cgtype=4
)
注意:上述代码,要是在with Snd前面加一句 “decalare @FstCgid int =1234”,必须以“;”结尾,否则会报错;
备注:如果WITH AS短语所定义的表名被调用两次以上,则优化器会自动将WITH AS短语所获取的数据放入一个TEMP表里,如果只是被调用一次,则不会。而提示materialize则是强制将WITH AS短语里的数据放入一个全局临时表里。
2.临时表方法
临时表与永久表相似,只是它的创建是在Tempdb中,它只有在一个数据库连接结束后或者由SQL命令DROP掉,才会消失,否则就会一直存在(临时表一般被创建后,如果在执行的时候,没有通过DROP Table的操作,第二次就不能再被创建)。临时表在创建的时候都会产生SQL Server的系统日志,虽它们在Tempdb中体现,是分配在内存中的,它们也支持物理的磁盘,但用户在指定的磁盘里看不到文件。
临时表分为本地和全局两种,本地临时表的名称都是以“#”为前缀,只有在本地当前的用户连接中才是可见的,当用户从实例断开连接时被删除。全局临时表的名称都是以“##”为前缀,创建后对任何用户都是可见的,当所有引用该表的用户断开连接时被删除。
示例:
if object_id(‘tempdb..#tempCategory‘) is not null drop table #tempCategory
create table #tempCategory(
num int,
CGName varchar(50),
CGID int,
PartnerID int,
UpdTime datetime,
Operator varchar(50)
)
备注:临时表的一些特性:
1)添加、修改、删除列。例如,列的名称、长度、数据类型、精度、小数位数以及为空性均可进行修改,只是有一些限制而已。
2)可添加或删除主键和外键约束。
3)可添加或删除 UNIQUE 和 CHECK 约束及 DEFAULT 定义(对象)。
4)可使用 IDENTITY 或 ROWGUIDCOL 属性添加或删除标识符列。虽然 ROWGUIDCOL 属性也可添加至现有列或从现有列删除,但是任何时候在表中只能有一列可具有该属性。
5)表及表中所选定的列已注册为全文索引。
3.表变量方法
表变量创建的语法类似于临时表,区别就在于创建的时候,必须要为之命名。表变量是变量的一种,表变量也分为本地及全局的两种,本地表变量的名称都是以“@”为前缀,只有在本地当前的用户连接中才可以访问。全局的表变量的名称都是以“@@”为前缀,一般都是系统的全局变量,像我们常用到的,如@@Error代表错误的号,@@RowCount代表影响的行数。
示例:
DECLARE @News Table ( News_id int NOT NULL, NewsTitle varchar(100), NewsContent varchar(2000), NewsDateTime datetime )
上述三种方法的区别:
临时表和表变量的区别:
1)表变量是存储在内存中的,当用户在访问表变量的时候,SQL Server是不产生日志的,而在临时表中是产生日志的;
2)在表变量中,是不允许有非聚集索引的;
3)表变量是不允许有DEFAULT默认值,也不允许有约束;
4)临时表上的统计信息是健全而可靠的,但是表变量上的统计信息是不可靠的;
5)临时表中是有锁的机制,而表变量中就没有锁的机制。
临时表和表变量的选择:
1)使用表变量主要需要考虑的就是应用程序对内存的压力,如果代码的运行实例很多,就要特别注意内存变量对内存的消耗。我们对于较小的数据或者是通过计算出来的推荐使用表变量。如果数据的结果比较大,在代码中用于临时计算,在选取的时候没有什么分组的聚合,就可以考虑使用表变量。
2)一般对于大的数据结果,或者因为统计出来的数据为了便于更好的优化,我们就推荐使用临时表,同时还可以创建索引,由于临时表是存放在Tempdb中,一般默认分配的空间很少,需要对tempdb进行调优,增大其存储的空间。
CTE和WITH AS短语结合使用提高SQL查询性能:
cet要比表变量效率高得多!
表变量实际上使用了临时表,从而增加了额外的I/O开销,因此,表变量的方式并不太适合数据量大且频繁查询的情况。
注:存储过程中局部临时表是事务级的如下图:
图片1
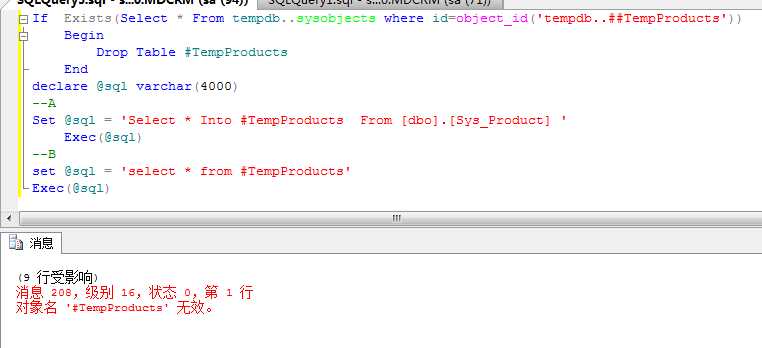
图片2:
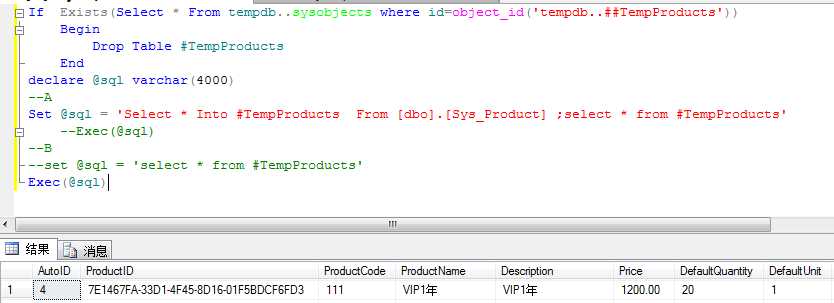
图1的写法 A和B属于两个不同的事务,所以会报错。而图2的写法是一个事务里面则成功执行。
2. 其他写法就是不用拼接SQL语句,直接写就行
select * into #TempProducts from [dbo].[Sys_Product];
select * from #TempProducts;
3. 一个#号的临时表是事务级别的,就是说一个临时表只存在于一个事务里面。