日常写SQL中可能会有一些小细节忽略了导致整个sql的性能下降了好几倍甚至几十倍,几百倍。以下这个示例就是mysql语句中的一个单引号(‘‘)引发的性能耗损,我相信很多朋友都遇到过,甚至还在这样写。
先看下我的表结构:
CREATE TABLE `d_sku` ( `id` varchar(36) NOT NULL, `commodity_id` varchar(36) DEFAULT NULL, `counts` int(11) DEFAULT NULL, `price` double(15,2) DEFAULT NULL, `status` int(11) DEFAULT NULL, `location` varchar(100) DEFAULT NULL, `create_time` datetime DEFAULT NULL, `create_id` varchar(36) DEFAULT NULL, `modify_time` datetime DEFAULT NULL, `provalue_str` varchar(500) DEFAULT NULL, `category_id` varchar(36) DEFAULT NULL, `customer_id` varchar(36) DEFAULT NULL, `cert_no` varchar(100) DEFAULT NULL, `profit` double DEFAULT NULL, `check_cargo` int(11) DEFAULT ‘0‘, `check_time` datetime DEFAULT NULL, `keep_last_checked` int(11) DEFAULT NULL, `approval_status` int(11) DEFAULT ‘0‘, `code` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`), KEY `index_price` (`price`) USING BTREE, KEY `index_category_status` (`category_id`,`status`) USING BTREE, KEY `index_modifytime` (`modify_time`) USING BTREE, KEY `index_customerId_categoryId` (`customer_id`,`category_id`) USING BTREE, KEY `index_certNo_customerId` (`cert_no`,`customer_id`) USING BTREE, KEY `index_provaluestr` (`provalue_str`(320)) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC
一个电商平台的SKU数据库表结构模式,该表中数据条数376138。以此下两种查询方式看下执行效率。查询语句都是从该表中查询一条数据分类为d2a17030-149d-11e5-a9de-000c29d7a3a0并且编号为5186354366的数据。
1.实例测试
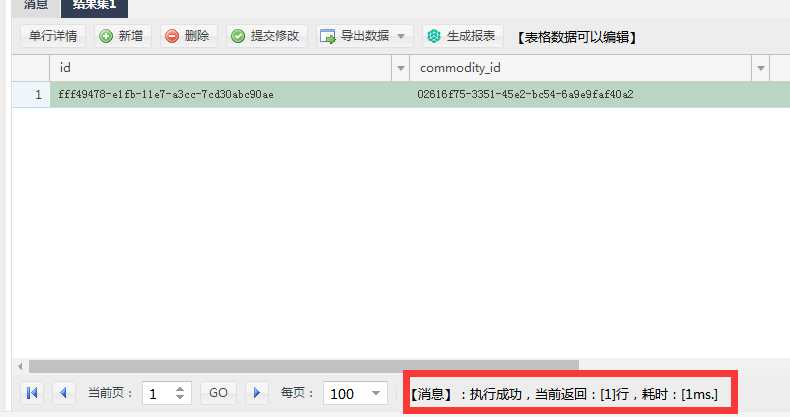
1.对查询内容添加单引号
SELECT * FROM d_sku d where category_id=‘d2a17030-149d-11e5-a9de-000c29d7a3a0‘ and d.cert_no=‘5186354366‘;
【消息】:执行成功,当前返回:[1]行,耗时:[1ms.]。查询速度非常快。
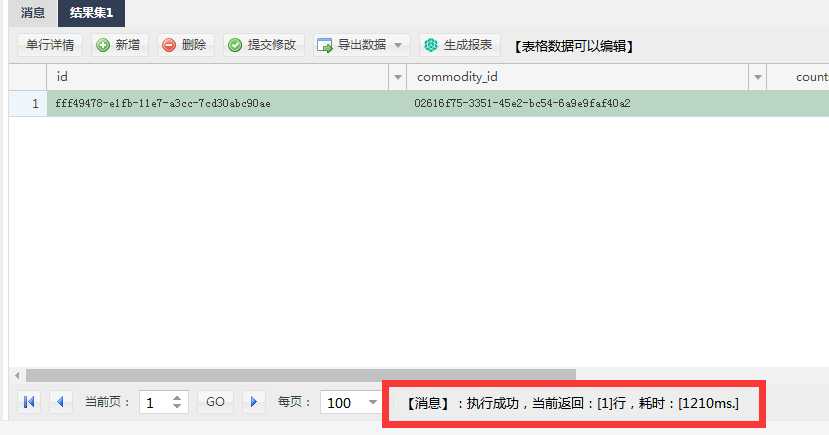
2.对查询内容不添加单引号
SELECT * FROM d_sku d where category_id=‘d2a17030-149d-11e5-a9de-000c29d7a3a0‘ and d.cert_no=5186354366;
【消息】:执行成功,当前返回:[1]行,耗时:[1210ms.]发现两者之间的执行效率显而易见啊。
2.两者区别分析
这样一查询效果真的是显而易见,添加单引号查询才1ms,不添加单引号查询的耗时是1210ms.一条数据就这么明显了。可想而知这种性能损失有多大。但是为什么会这样呢?先从分析索引看起。使用关键词 “explain” 查看sql执行效率详细(关键词使用介绍点传送门)。
explain SELECT * FROM d_sku d where category_id=‘d2a17030-149d-11e5-a9de-000c29d7a3a0‘ and d.cert_no=‘5186354366‘; explain SELECT * FROM d_sku d where category_id=‘d2a17030-149d-11e5-a9de-000c29d7a3a0‘ and d.cert_no=5186354366;
图一:添加单引号

图二:未添加单引号

两条数据对比分析:
图一:
添加单引号后的性能详情,其中表头key这里显示出来真正使用了组合索引“index_certNo_customerId” ,其中这两个索引对应的列正好是“category_id”和“cert_no”。再看rows这,表示查询这条数据只检索了一条数据,因为是这里索引生效了,所以通过“cert_no”编号直接查询到了数据。
图二:
未添加单引号后的性能详情,发现真正使用的索引只有“index_category_status”,回到创建表结构的时候可以发现这条索引信息是添加`category_id`,`status`这两个列的,表示只用到了category_id,而第二个条件的cert_no列并没有用到索引,所以性能的损耗就在这里发生了。
总结:
原因就是因为我们创建表结构的时候cert_no字段是varchar类型的,而where时未添加单引号的时候参数是被做为数字类型来使用的,那不同的类型做查询的时候肯定是要转型的,数据类型转换的话就无法正常使用索引了。所以可以得到一个结论就是Int类型的数据在转换varchar再使用是不会使用索引的。我们可以修改表结构将cert_no改为int类型后在使用不添加单引号的参数查询时性能也就是正常的了。同样也是可以通过添加单引号来实现。