在做数据处理时,需要用到不同的手法,如特征标准化,主成分分析,等等会重复用到某些参数,sklearn中提供了管道,可以一次性的解决该问题
先展示先通常的做法
import pandas as pd from sklearn.preprocessing import StandardScaler from sklearn.decomposition import PCA from sklearn.linear_model import LogisticRegression df = pd.read_csv(‘wdbc.csv‘) X = df.iloc[:, 2:].values y = df.iloc[:, 1].values # 标准化 sc = StandardScaler() X_train_std = sc.fit_transform(X_train) X_test_std = sc.transform(X_test) # 主成分分析PCA pca = PCA(n_components=2) X_train_pca = pca.fit_transform(X_train_std) X_test_pca = pca.transform(X_test_std) # 逻辑斯蒂回归预测 lr = LogisticRegression(random_state=1) lr.fit(X_train_pca, y_train) y_pred = lr.predict(X_test_pca)
先对数据标准化,然后做主成分分析降维,最后做回归预测
现在使用管道
from sklearn.pipeline import Pipeline pipe_lr = Pipeline([(‘sc‘, StandardScaler()), (‘pca‘, PCA(n_components=2)), (‘lr‘, LogisticRegression(random_state=1))]) pipe_lr.fit(X_train, y_train) pipe_lr.score(X_test, y_test)
Pipeline对象接收元组构成的列表作为输入,每个元组第一个值作为变量名,元组第二个元素是sklearn中的transformer或Estimator。
管道中间每一步由sklearn中的transformer构成,最后一步是一个Estimator。我们的例子中,管道包含两个中间步骤,一个StandardScaler和一个PCA,这俩都是transformer,逻辑斯蒂回归分类器是Estimator。
当管道pipe_lr执行fit方法时,首先StandardScaler执行fit和transform方法,然后将转换后的数据输入给PCA,PCA同样执行fit和transform方法,最后将数据输入给LogisticRegression,训练一个LR模型。
对于管道来说,中间有多少个transformer都可以。工作方式如下
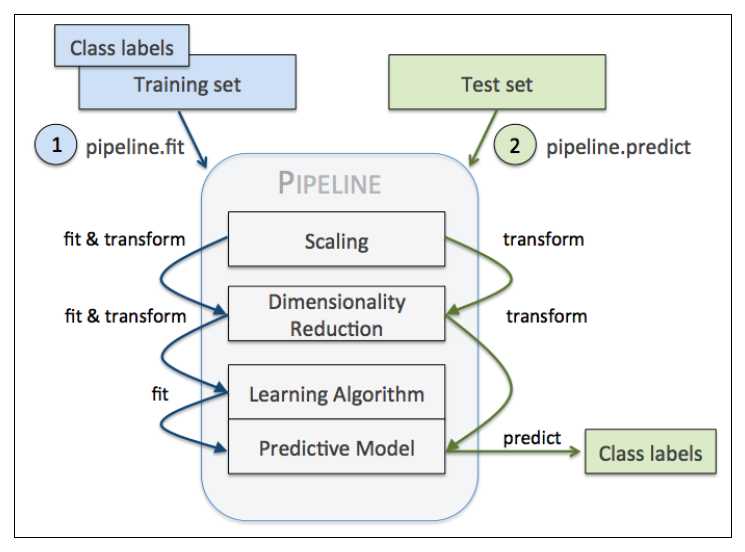
使用管道减少了很多代码量
现在回归模型的评估和调参
训练机器学习模型的关键一步是要评估模型的泛化能力。如果我们训练好模型后,还是用训练集取评估模型的性能,这显然是不符合逻辑的。一个模型如果性能不好,要么是因为模型过于复杂导致过拟合(高方差),要么是模型过于简单导致导致欠拟合(高偏差)。可是用什么方法评价模型的性能呢?这就是这一节要解决的问题,你会学习到两种交叉验证计数,holdout交叉验证和k折交叉验证, 来评估模型的泛化能力
一、holdout交叉验证(评估模型性能)
holdout方法很简单就是将数据集分为训练集和测试集,前者用于训练,后者用于评估
如果在模型选择的过程中,我们始终用测试集来评价模型性能,这实际上也将测试集变相地转为了训练集,这时候选择的最优模型很可能是过拟合的。
更好的holdout方法是将原始训练集分为三部分:训练集、验证集和测试集。训练机用于训练不同的模型,验证集用于模型选择。而测试集由于在训练模型和模型选择这两步都没有用到,对于模型来说是未知数据,因此可以用于评估模型的泛化能力。下图展示了holdout方法的步骤:
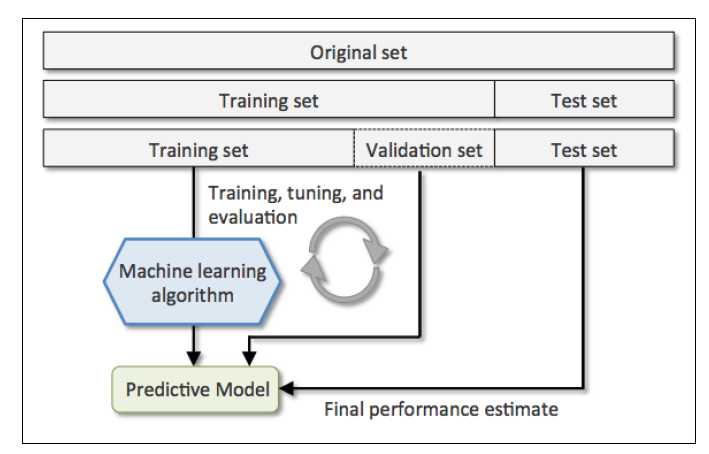
缺点:它对数据分割的方式很敏感,如果原始数据集分割不当,这包括训练集、验证集和测试集的样本数比例,以及分割后数据的分布情况是否和原始数据集分布情况相同等等。所以,不同的分割方式可能得到不同的最优模型参数
二、K折交叉验证(评估模型性能)
k折交叉验证的过程,第一步我们使用不重复抽样将原始数据随机分为k份,第二步 k-1份数据用于模型训练,剩下那一份数据用于测试模型。然后重复第二步k次,我们就得到了k个模型和他的评估结果(译者注:为了减小由于数据分割引入的误差,通常k折交叉验证要随机使用不同的划分方法重复p次,常见的有10次10折交叉验证)
然后我们计算k折交叉验证结果的平均值作为参数/模型的性能评估。使用k折交叉验证来寻找最优参数要比holdout方法更稳定。一旦我们找到最优参数,要使用这组参数在原始数据集上训练模型作为最终的模型。
k折交叉验证使用不重复采样,优点是每个样本只会在训练集或测试中出现一次,这样得到的模型评估结果有更低的方法。
下图演示了10折交叉验证:
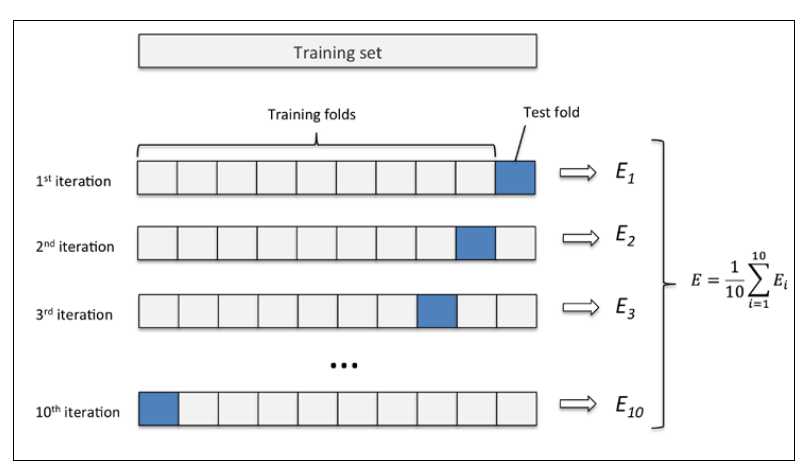
10次10折交叉验证我的理解是将按十种划分方法,每次将数据随机分成k分,k-1份训练,k份测试。获取十个模型和评估结果,然后取10次的平均值作为性能评估
from sklearn.cross_validation import StratifiedKFold
pipe_lr = Pipeline([(‘sc‘, StandardScaler()), (‘pca‘, PCA(n_components=2)), (‘lr‘, LogisticRegression(random_state=1))]) pipe_lr.fit(X_train, y_train) kfold = StratifiedKFold(y=y_train, n_folds=10, random_state=1) scores= [] for k, (train, test) in enumerate(kfold): pipe_lr.fit(X_train[train], y_train[train]) score = pipe_lr.score(X_train[test], y_train[test]) scores.append(scores) print(‘Fold: %s, Class dist.: %s, Acc: %.3f‘ %(k+1, np.bincount(y_train[train]), score))print(‘CV accuracy: %.3f +/- %.3f‘ %(np.mean(scores), np.std(scores)))
更简单的方法
from sklearn.cross_validation import StratifiedKFold pipe_lr = Pipeline([(‘sc‘, StandardScaler()), (‘pca‘, PCA(n_components=2)), (‘lr‘, LogisticRegression(random_state=1))]) pipe_lr.fit(X_train, y_train) scores = cross_val_score(estimator=pipe_lr, X=X_train, y=y_train, cv=10, n_jobs=1) print(‘CV accuracy scores: %s‘ %scores) print(‘CV accuracy: %.3f +/- %.3f‘ %(np.mean(scores), np.std(scores)))
cv即k
三、学习曲线(调试算法)
from sklearn.learning_curve import learning_curve pipe_lr = Pipeline([(‘scl‘, StandardScaler()), (‘clf‘, LogisticRegression(penalty=‘l2‘, random_state=0))]) train_sizes, train_scores, test_scores = learning_curve(estimator=pipe_lr, X=X_train, y=y_train, train_sizes=np.linspace(0.1, 1.0, 10), cv=10, n_jobs=1) train_mean = np.mean(train_scores, axis=1) train_std = np.std(train_scores, axis=1) test_mean = np.mean(test_scores, axis=1) test_std = np.std(test_scores, axis=1) plt.plot(train_sizes, train_mean, color=‘blue‘, marker=‘0‘, markersize=5, label=‘training accuracy‘) plt.fill_between(train_sizes, train_mean + train_std, train_mean - train_std, alpha=0.15, color=‘blue‘) plt.plot(train_sizes, test_mean, color=‘green‘, linestyle=‘--‘, marker=‘s‘, markersize=5, label=‘validation accuracy‘) plt.fill_between(train_sizes, test_mean + test_std, test_mean - test_std, alpha=0.15, color=‘green‘) plt.grid() plt.xlabel(‘Number of training samples‘) plt.ylabel(‘Accuracy‘) plt.legend(loc=‘lower right‘) plt.ylim([0.8, 1.0]) plt.show()