1、urllib和urllib2区别实例
urllib和urllib2都是接受URL请求相关模块,但是提供了不同的功能,两个最显著的不同如下:
urllib可以接受URL,不能创建设置headers的Request类实例,urlib2可以。
url转码
https://www.baidu.com/s?wd=%E5%AD%A6%E7%A5%9E
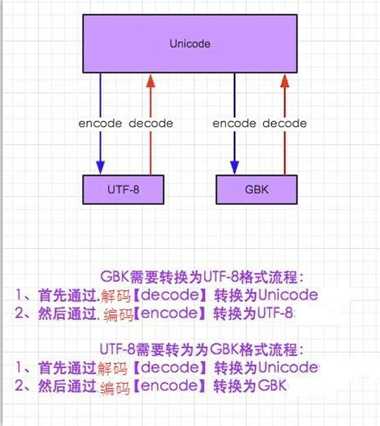
python字符集解码加码过程:
2.爬虫GET提交实例


#coding:utf-8 import urllib #负责url编码处理 import urllib2 url = "https://www.baidu.com/s" word = {"wd": "繁华"} word = urllib.urlencode(word) #转换成url编码格式(字符串) newurl = url + "?" + word headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} request = urllib2.Request(newurl, headers=headers) response = urllib2.urlopen(request) print response.read()
#coding:utf-8 import urllib #负责url编码处理 import urllib2 url = "https://www.baidu.com/s" word = {"wd": "咖菲猫"} word = urllib.urlencode(word) #转换成url编码格式(字符串) newurl = url + "?" + word headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} request = urllib2.Request(newurl, headers=headers) response = urllib2.urlopen(request) print response.read()
自定义爬虫GET提交实例
#coding:utf-8 import urllib #负责url编码处理 import urllib2 url = "https://www.baidu.com/s" keyword = raw_input("请输入要查询的关键字:") word = {"wd": keyword} word = urllib.urlencode(word) #转换成url编码格式(字符串) newurl = url + "?" + word headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} request = urllib2.Request(newurl, headers=headers) response = urllib2.urlopen(request) print response.read()
3.批量爬取贴吧页面数据
分析贴吧URL
http://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F
pn递增50为一页
0为第一页
http://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&pn=0
50为第二页
http://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&pn=50
100为第三页
http://tieba.baidu.com/f?kw=%E7%BB%9D%E5%9C%B0%E6%B1%82%E7%94%9F&pn=100
批量爬贴吧实例
#coding:utf-8 import urllib import urllib2 def loadPage(url, filename): ‘‘‘ 作用:根据url发送请求, 获取服务器响应文件 url:需要爬取的url地址 filename:文件名 ‘‘‘ print "正在下载" + filename headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} request = urllib2.Request(url, headers = headers) response = urllib2.urlopen(request) return response.read() def writeFile(html, filename): ‘‘‘ 作用:保存服务器相应文件到本地硬盘文件里 html:服务器相应文件 filename:本地磁盘文件名 ‘‘‘ print "正在存储" + filename with open(unicode(filename, ‘utf-8‘), ‘w‘) as f: f.write(html) print "-" * 20 def tiebaSpider(url, beginPage, endPage, name): ‘‘‘ 作用:负责处理url,分配每个url去发送请求 url:需要处理的第一个url beginPage:爬虫执行的起始页面 endPage:爬虫执行的截止页面 ‘‘‘ for page in range(beginPage, endPage + 1): pn = (page - 1) * 50 filename = "第" + name + "-" + str(page) + "页.html" #组合为完整的url,并且pn值每次增加50 fullurl = url + "&pn=" + str(pn) #print fullurl #调用loadPage()发送请求获取HTML页面 html = loadPage(fullurl, filename) #将获取到的HTML页面写入本地磁盘文件 writeFile(html, filename) #模拟main函数" if __name__ == "__main__": kw = raw_input("请输入需要爬取的贴吧:") beginPage = int(raw_input("请输入起始页:")) endPage = int(raw_input("请输入终止页:")) url = "http://tieba.baidu.com/f?" key = urllib.urlencode({"kw": kw}) #组合后的url示例:http://tieba.baidu.com/f?kw=绝地求生 newurl = url + key tiebaSpider(newurl, beginPage, endPage, kw)
4.Fidder使用安装
下载fidder
安装后,照下图设置
5.有道翻译POST分析
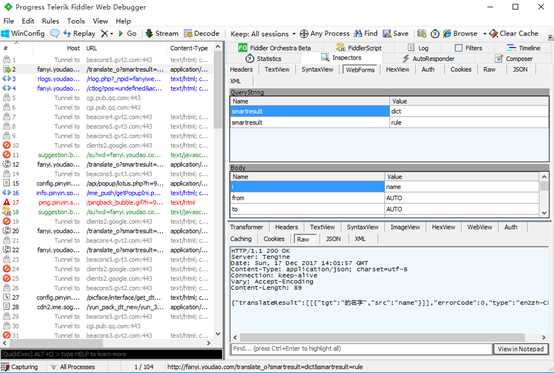
调用有道翻译POST API实例
#coding:utf-8 import urllib import urllib2 #通过抓包的方式获取的url,并不是浏览器上显示的url url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null" #完整的headers headers = { "Accept": "application/json, text/javascript, */*; q=0.01", "Origin": "http://fanyi.youdao.com", "X-Requested-With": "XMLHttpRequest", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36", "Content-Type": "application/x-www-form-urlencoded; charset=UTF-8" } #用户接口输入 key = raw_input("请输入需要翻译的英文单词:") #发送到web服务器的表单数据 formdata = { "i": key, "from": "AUTO", "to": "AUTO", "smartresult": "dict", "client": "fanyideskweb", "salt": "1513519318944", "sign": "29e3219b8c4e75f76f6e6aba0bb3c4b5", "doctype": "json", "version": "2.1", "keyfrom": "fanyi.web", "action": "FY_BY_REALTIME", "typoResult": "false" } #经过urlencode转码 data = urllib.urlencode(formdata) #如果Request()方法里的data参数有值,那么这个请求就是POST #如果没有,就是Get request = urllib2.Request(url, data= data, headers= headers) print urllib2.urlopen(request).read()
6.Ajax加载方式的数据获取
豆瓣分析Ajax
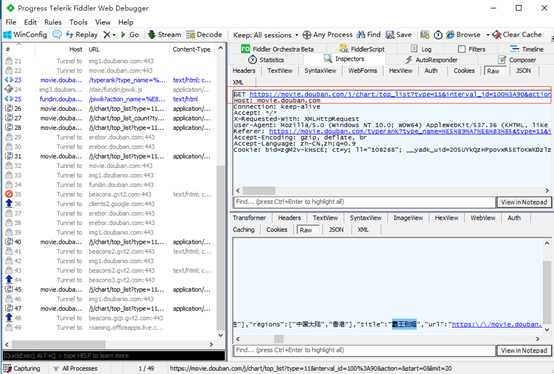
爬取豆瓣电影排行信息实例
#coding:utf-8 import urllib2 import urllib url = "https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=" headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36"} formdata = { "start": "0", "limit": "20" } data = urllib.urlencode(formdata) request = urllib2.Request(url, data = data, headers = headers) print urllib2.urlopen(request).read()