ASCII字符集:ASCII码于1961年提出,用于在不同计算机硬件和软件系统中实现数据传输标准化,在大多数的小型机和全部的个人计算机都使用此码。标准ASCII码为7位,扩充为8位。
ASCII码划分为两个集合:128个字符的标准ASCII码和附加的128个字符的扩充和ASCII码。其中96个字符可打印字符,包括常用的字母、数字、标点符号等,另外32个不可以显示的控制字符。
字母和数字的 ASCII 码的记忆是非常简单的。我们只要记住了一个字母或数字的 ASCII 码(例如记住 A 为 65 , 0 的 ASCII 码为 48 ),知道相应的大小写字母之间差 32 ,就可以推算出其余字母、数字的 ASCII 码。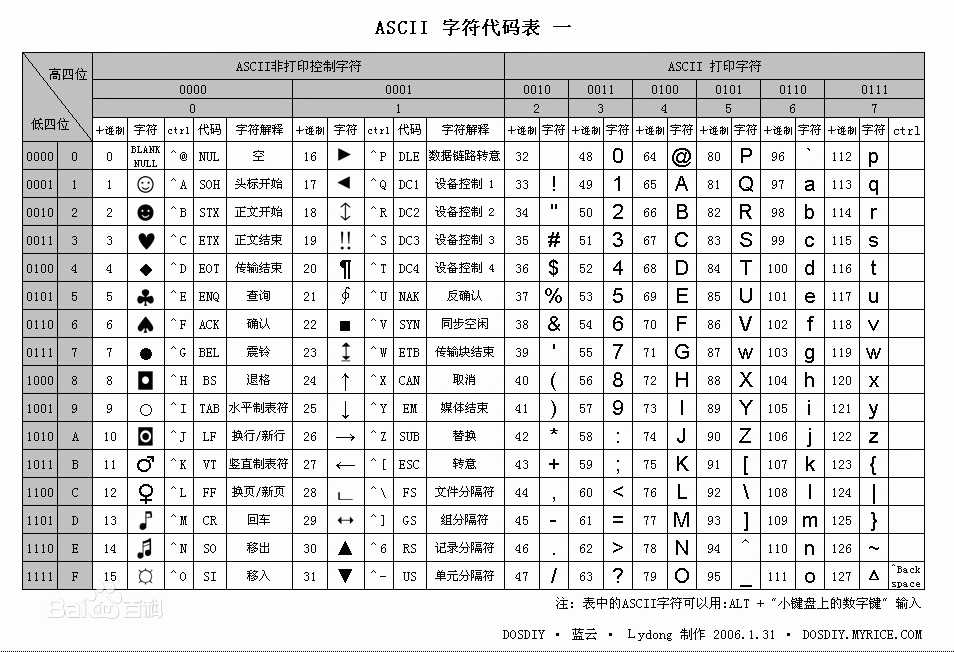
中文编码
1、GB2312:GB2312 也是ANSI编码里的一种,对ANSI编码最初始的ASCII编码进行扩充,为了满足国内在计算机中使用汉字的需要,中国国家标准总局发布了一系列的汉字字符集国家标准编码,统称为GB码,或国标码。其中标准号为GB 2312-1980最有影响力,因其使用非常普遍,也常被通称为国标码。1980年发布的GB2312面向简体中文字符集,并不支持繁体汉字。
GB 2312是一个简体中文字符集,由6763个常用汉字和682个全角的非汉字字符组成,收录了7445个字符。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
2、GBK1.0和GB18030: GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
3、Unicode(万国码):如上ANSI编码条例中所述,世界上存在着多种编码方式,在ANSi编码下,同一个编码值,在不同的编码体系里代表着不同的字。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码,可能最终显示的是中文,也可能显示的是日文。在ANSI编码体系下,要想打开一个文本文件,不但要知道它的编码方式,还要安装有对应编码表,否则就可能无法读取或出现乱码。为什么电子邮件和网页都经常会出现乱码,就是因为信息的提供者可能是日文的ANSI编码体系和信息的读取者可能是中文的编码体系,他们对同一个二进制编码值进行显示,采用了不同的编码,导致乱码。这个问题促使了unicode码的诞生。
如果有一种编码,将世界上所有的符号都纳入其中,无论是英文、日文、还是中文等,大家都使用这个编码表,就不会出现编码不匹配现象。每个符号对应一个唯一的编码,乱码问题就不存在了。这就是Unicode编码。