上一篇文章我们引出了GoogLeNet InceptionV1的网络结构,这篇文章中我们会详细讲到Inception V2/V3/V4的发展历程以及它们的网络结构和亮点。
GoogLeNet Inception V2
GoogLeNet Inception V2在《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》出现,最大亮点是提出了Batch Normalization方法,它起到以下作用:
- 使用较大的学习率而不用特别关心诸如梯度爆炸或消失等优化问题;
- 降低了模型效果对初始权重的依赖;
- 可以加速收敛,一定程度上可以不使用Dropout这种降低收敛速度的方法,但却起到了正则化作用提高了模型泛化性;
- 即使不使用ReLU也能缓解激活函数饱和问题;
- 能够学习到从当前层到下一层的分布缩放( scaling (方差),shift (期望))系数。
在机器学习中,我们通常会做一种假设:训练样本独立同分布(iid)且训练样本与测试样本分布一致,如果真实数据符合这个假设则模型效果可能会不错,反之亦然,这个在学术上叫Covariate Shift,所以从样本(外部)的角度说,对于神经网络也是一样的道理。从结构(内部)的角度说,由于神经网络由多层组成,样本在层与层之间边提特征边往前传播,如果每层的输入分布不一致,那么势必造成要么模型效果不好,要么学习速度较慢,学术上这个叫InternalCovariate Shift。
假设:$y$为样本标注,$X=\{x_{1},x_{2},x_{3},......\}$为样本$x$通过神经网络若干层后每层的输入;
理论上:$p(x,y)$的联合概率分布应该与集合$X$中任意一层输入的联合概率分布一致,如:$p(x,y)=p(x_{1},y)$;
但是:$p(x,y)=p(y|x)·p(x)$,其中条件概率$p(y|x)$是一致的,即$p(y|x)=p(y|x_{1})=p(y|x_{1})=......$,但由于神经网络每一层对输入分布的改变,导致边缘概率是不一致的,即$p(x)\neq p(x_{1})\neq p(x_{2})......$,甚至随着网络深度的加深,前面层微小的变化会导致后面层巨大的变化。
BN整个算法过程如下:

- 以batch的方式做训练,对m个样本求期望和方差后对训练数据做白化,通过白化操作可以去除特征相关性并把数据缩放在一个球体上,这么做的好处既可以加快优化算法的优化速度也可能提高优化精度,一个直观的解释:
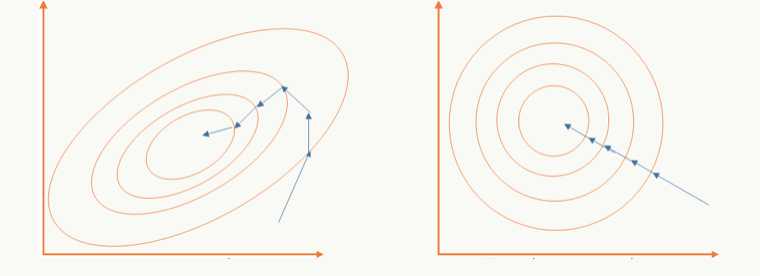
左边是未做白化的原始可行域,右边是做了白化的可行域;
- 当原始输入对模型学习更有利时能够恢复原始输入(和残差网络有点神似):
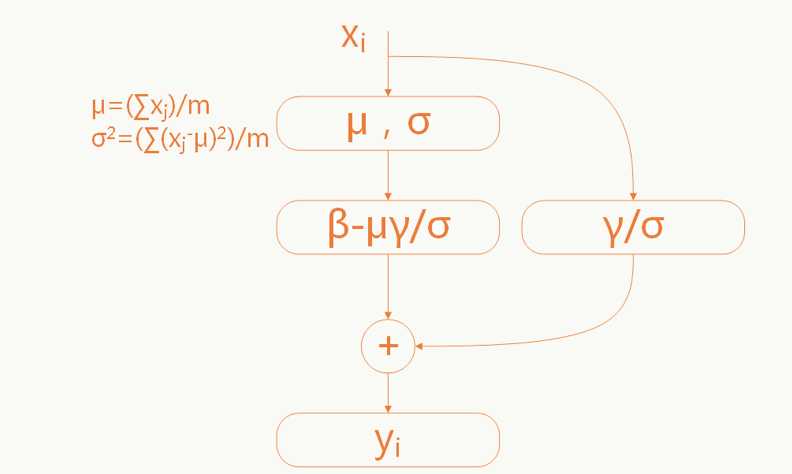
这里的参数$\gamma$和$\sigma$是需要学习的。
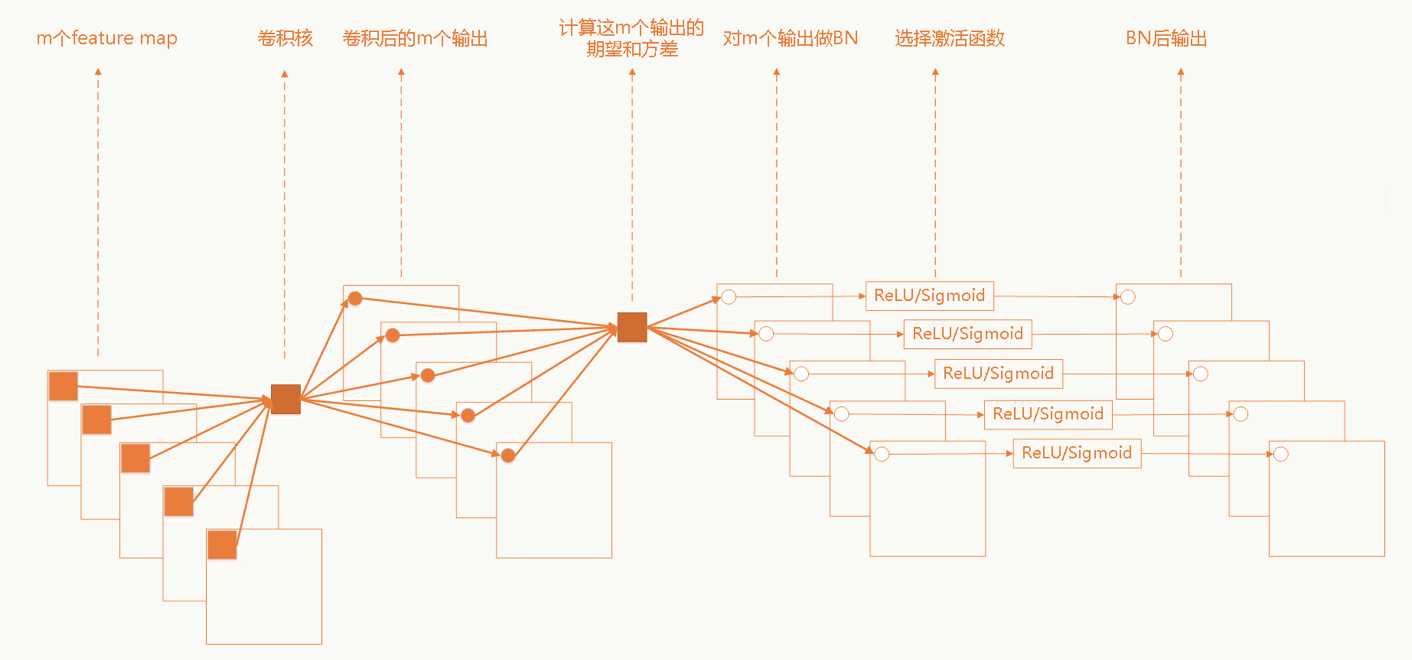
卷积神经网络中的BN
卷积网络中采用权重共享策略,每个feature map只有一对$\gamma$和$\sigma$需要学习。
GoogLeNet Inception V3
GoogLeNet Inception V3在《Rethinking the Inception Architecture for Computer Vision》中提出(注意,在这篇论文中作者把该网络结构叫做v2版,我们以最终的v4版论文的划分为标准),该论文的亮点在于:
- 提出通用的网络结构设计准则
- 引入卷积分解提高效率
- 引入高效的feature map降维
网络结构设计的准则
前面也说过,深度学习网络的探索更多是个实验科学,在实验中人们总结出一些结构设计准则,但说实话我觉得不一定都有实操性:
- 避免特征表示上的瓶颈,尤其在神经网络的前若干层
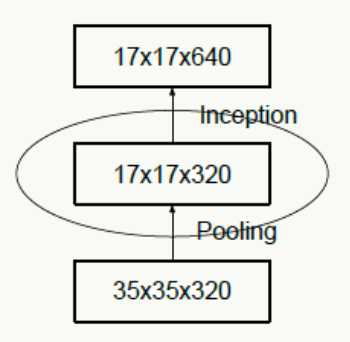
神经网络包含一个自动提取特征的过程,例如多层卷积,直观并符合常识的理解:如果在网络初期特征提取的太粗,细节已经丢了,后续即使结构再精细也没法做有效表示了;举个极端的例子:在宇宙中辨别一个星球,正常来说是通过由近及远,从房屋、树木到海洋、大陆板块再到整个星球之后进入整个宇宙,如果我们一开始就直接拉远到宇宙,你会发现所有星球都是球体,没法区分哪个是地球哪个是水星。所以feature map的大小应该是随着层数的加深逐步变小,但为了保证特征能得到有效表示和组合其通道数量会逐渐增加。
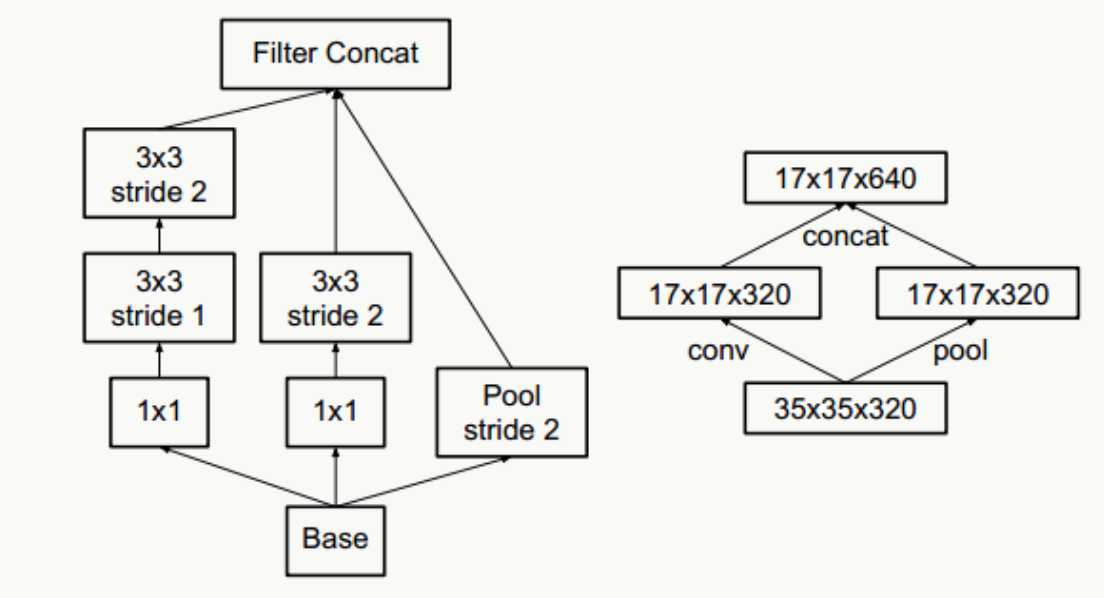
下图违反了这个原则,刚开就始直接从35×35×320被抽样降维到了17×17×320,特征细节被大量丢失,即使后面有Inception去做各种特征提取和组合也没用。
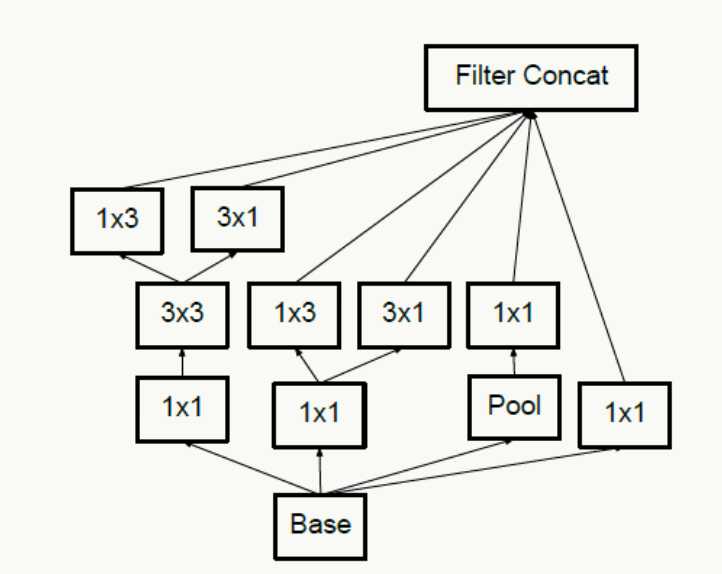
- 对于神经网络的某一层,通过更多的激活输出分支可以产生互相解耦的特征表示,从而产生高阶稀疏特征,从而加速收敛,注意下图的1×3和3×1激活输出:
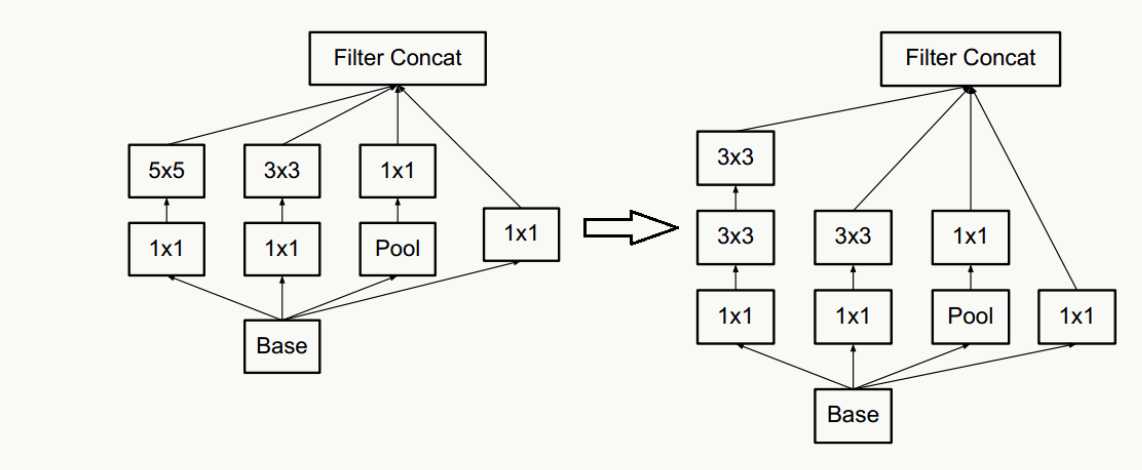
- 合理使用维度缩减不会破坏网络特征表示能力反而能加快收敛速度,典型的例如通过两个3×3代替一个5×5的降维策略,不考虑padding,用两个3×3代替一个5×5能节省1-(3×3+3×3)/(5×5)=28%的计算消耗。
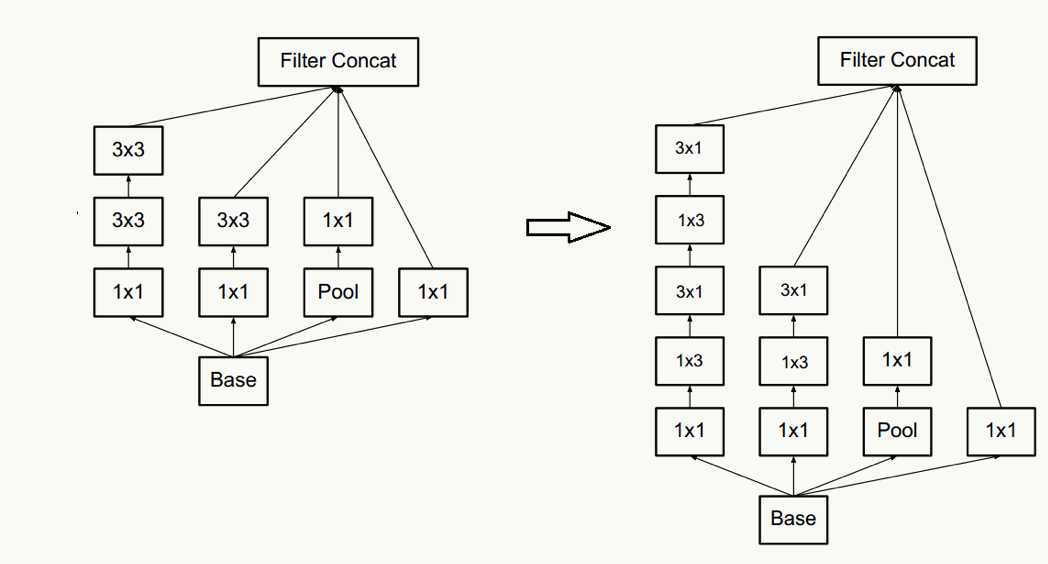
- 以及一个n×n卷积核通过顺序相连的两个1×n和n×1做降维(有点像矩阵分解),如果n=3,计算性能可以提升1-(3+3)/9=33%,但如果考虑高性能计算性能,这种分解可能会造成L1 cache miss率上升。
- 通过合理平衡网络的宽度和深度优化网络计算消耗(这句话尤其不具有实操性)。
- 抽样降维,传统抽样方法为pooling+卷积操作,为了防止出现特征表示的瓶颈,往往需要更多的卷积核,例如输入为n个d×d的feature map,共有k个卷积核,pooling时stride=2,为不出现特征表示瓶颈,往往k的取值为2n,通过引入inception module结构,即降低计算复杂度,又不会出现特征表示瓶颈,实现上有如下两种方式:
平滑样本标注
对于多分类的样本标注一般是one-hot的,例如[0,0,0,1],使用类似交叉熵的损失函数会使得模型学习中对ground truth标签分配过于置信的概率,并且由于ground truth标签的logit值与其他标签差距过大导致,出现过拟合,导致降低泛化性。一种解决方法是加正则项,即对样本标签给个概率分布做调节,使得样本标注变成“soft”的,例如[0.1,0.2,0.1,0.6],这种方式在实验中降低了top-1和top-5的错误率0.2%。
网络结构
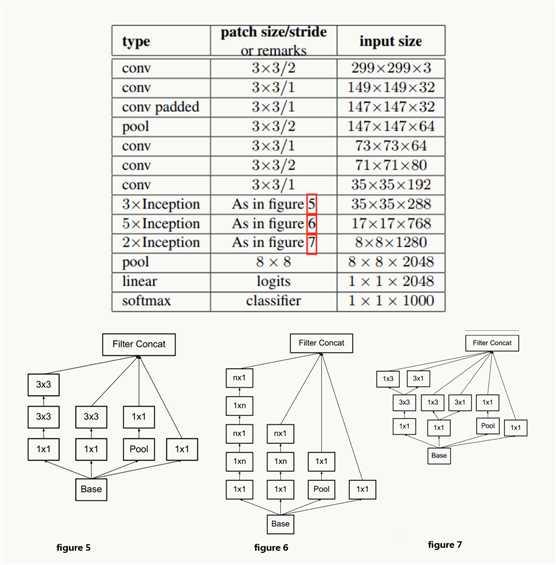
GoogLeNet Inception V4
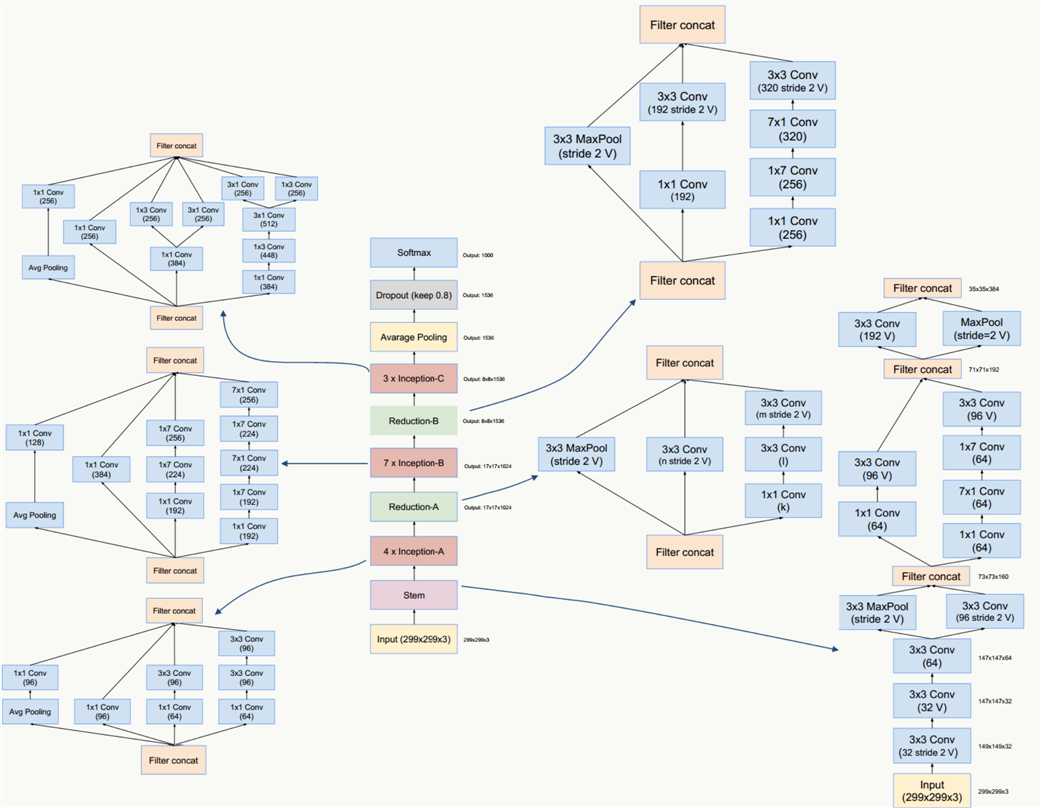
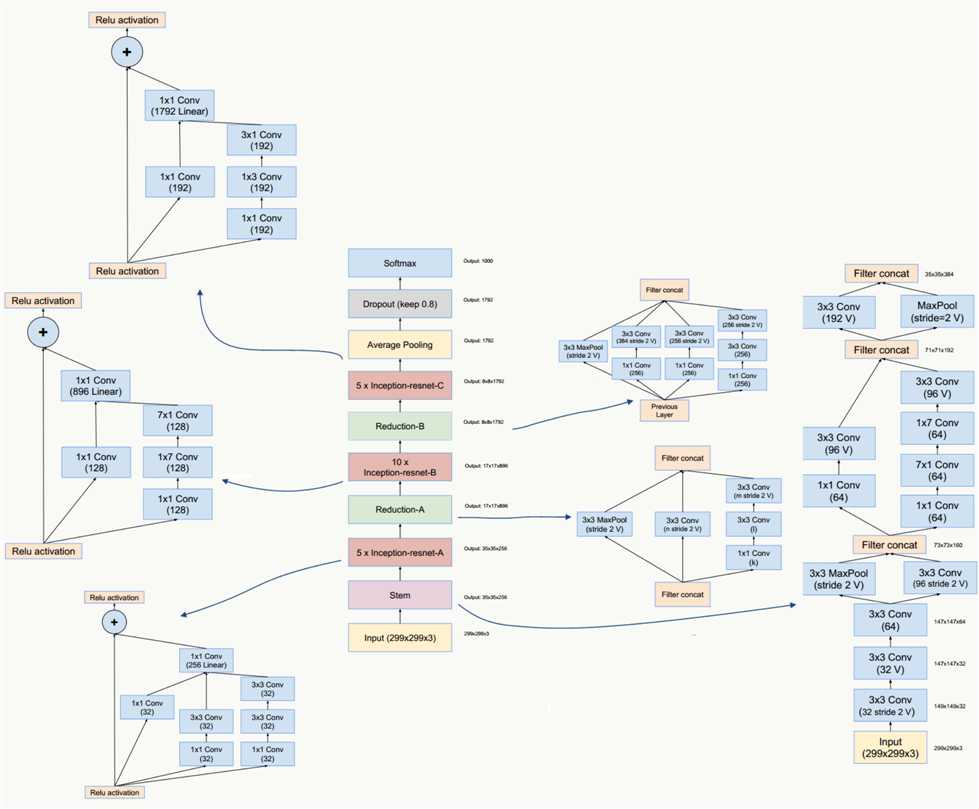
GoogLeNet Inception V4/和ResNet V1/V2这三种结构在《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》一文中提出,论文的亮点是:提出了效果更好的GoogLeNet Inception v4网络结构;与残差网络融合,提出效果不逊于v4但训练速度更快的结构。
GoogLeNet Inception V4网络结构
GoogLeNet Inception ResNet网络结构
代码实践
Tensorflow的代码在slim模块下有完整的实现,paddlepaddle的可以参考上篇文章中写的inception v1的代码来写。
总结
这篇文章比较偏理论,主要讲了GoogLeNet的inception模块的发展,包括在v2中提出的batch normalization,v3中提出的卷积分级与更通用的网络结构准则,v4中的与残差网络结合等,在实际应用过程中可以可以对同一份数据用不同的网络结构跑一跑,看看结果如何,实际体验一下不同网络结构的loss下降速率,对准确率的提升等。