一、数据库排名和流行趋势
1.1 Complete ranking
- 链接: https://db-engines.com/en/ranking
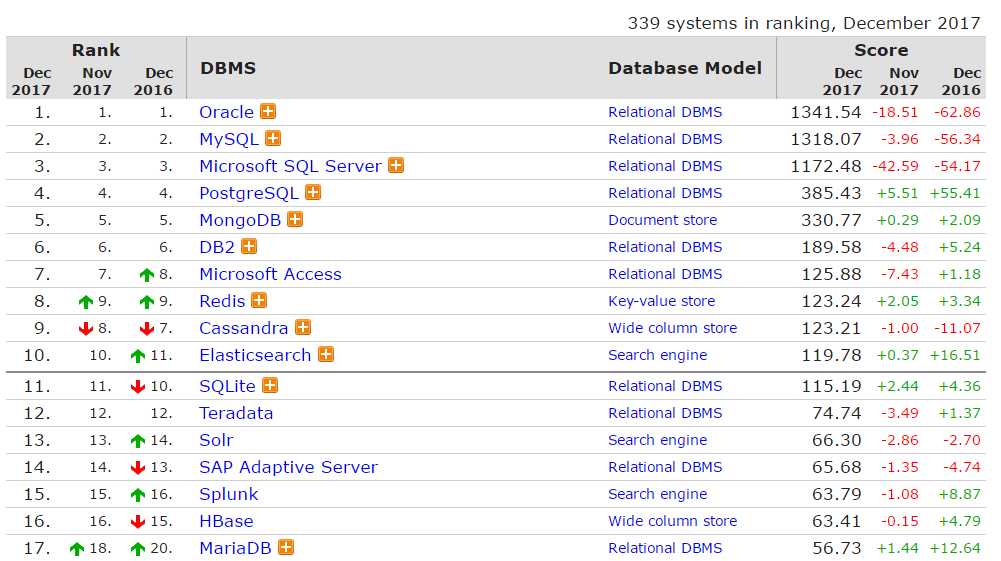
在这个网站列出了所有数据库的排名,还可以看到所属数据库类型等,每个月更新一次。有空可以看看。
1.2 DB-Engines Ranking - Trend Popularity
- 链接:https://db-engines.com/en/ranking_trend
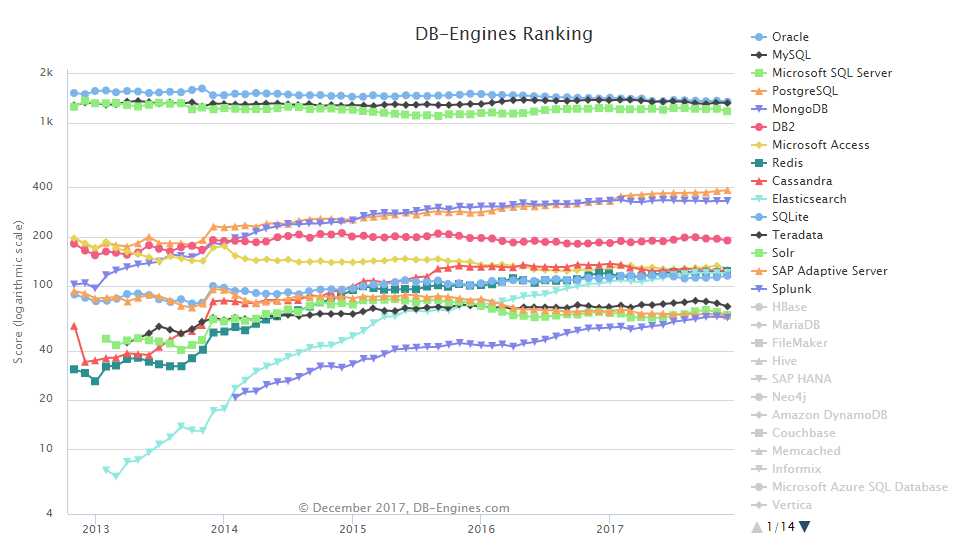
可以看到Oracle、MySQL、Microsoft SQL Server一直很主流,NoSQL的MongoDB、Redis、Cassandra、Elasticsearch上升很快。
二、关系型数据库
关系型数据库(RDBMS,),是建立在关系模型基础上的数据库,现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。
关系模型就是指二维表格模型,一个关系型数据库就是由二维表及其之间的联系组成的一个数据组织,是由关系数据结构、关系操作集合、关系完整性约束三部分组成。
2.1 关系数据结构
实体关系模型(Entity-Relationship Model),简称E-R Model是陈品山(Peter P.S Chen)博士于1976年提出的一套数据库的设计工具,运用真实世界中事物与关系的观念,来解释数据库中的抽象的数据架构。
2.2 关系操作集合
增删改查等,SQL(Structured Query Language)(结构化查询语言)就是一种基于关系数据库的语言,这种语言执行对关系数据库中数据的操作。
2.3 关系完整性约束
2.3.1 数据完整性
关系完整性约束是为保证数据库中数据的正确性和一致性,对关系模型提出的某种约束条件或规则。
完整性通常包括域完整性,实体完整性、参照完整性和用户定义完整性。
其中域完整性,实体完整性和参照完整性,是关系模型必须满足的完整性约束条件。
1)域完整性
域完整性是保证数据库字段取值的合理性,取值不能超出域,是否可以为NULL可以预先定义等。
- 域完整性约束(domain Integrity constrains)是最简单、最基本的约束。在当今的关系DBMS中,一般都有域完整性约束检查功能。
2)实体完整性
主键唯一,不能重复也不能取“空值"。
- 在关系模式中,以主键作为唯一性标识,不能取空值;如主关键字是多个属性的组合,则所有主属性均不得取空值。
3)参照完整性
指两个表的主关键字和外关键字的数据应一致(外键只能是所引用逐渐的值域中的值,或者为NULL;主键某值删除,则外键该值有一些约束-约束规则可选),保证了表之间的数据的一致性,防止了数据丢失或无意义的数据在数据库中扩散。
4)用户定义完整性
用户定义完整性(user defined integrity)是根据应用环境的要求和实际的需要,对某一具体应用所涉及的数据提出约束性条件。
- 这一约束机制一般不应由应用程序提供,而应有由关系模型提供定义并检验,用户定义完整性主要包括字段有效性约束和记录有效性。
2.3.2 数据完整性约束[1]
1)与表有关的约束
表中定义的一种约束,可在列定义是定义该约束(列约束),也可以在表定义时定义约束(表约束)。
相关的包括列约束(NOT NULL)和表约束(PRIMARY KEY,foreign key,check-定义某列值域,UNIQUE)。
在Insert和Update时都会检查约束。
2)域约束
在域定义中被定义的一种约束,定义后可应用于特定域中任何列。
- 相关的约束是check,定义后作为数据类型跟在列后即可使用。
3)断言
在断言定义时定义的一种约束,可以与一个或多个表进行关联。
- 相关的约束也是check。
2.4 范式[2]
范式是符合某一种级别的关系模式的集合,表示一个关系内部各属性之间联系的合理化程度。其最大的意义是为了避免数据的冗余和插入/删除/更新的异常。
目前数据库有1NF,2NF,3NF,BCNF,4NF,5NF,数据库一般最多考虑到BCNF。
符合高一级范式的设计,必定符合低一级范式。
2.4.1 第一范式(1NF)
符合1NF的关系中的每个属性都不可再分。
- 也就是列没有重复。1NF是所有关系型数据库的最基本要求。
2.4.2 第二范式(2NF)
2NF在1NF的基础之上,消除了非主属性对于码的部分函数依赖。
2.4.3 第三范式(3NF)
3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖。
2.4.3 BCNF
在#NF的基础上,消除主属性对于码的部分与传递函数依赖。(如果关系R符合3NF,且候选码只有一个,那么关系R必定符合BCNF)
具体解释参照文末的资料。
2.5 主流关系型数据库[3]
从全部数据库排名上可以看到流行的关系型数据库是Oracle、MySQL、Microsoft SQL Server、PostgreSQL、DB2、Microsoft Access。
- 其中,MySQL和PostgreSQL都是开源的,其他都是商业的;
- Access操作简单,是小型桌面数据库,一般记录数达到10万条左右的时候性能就会急剧下降,如果数据达到100M左右,很容易造成服务器iis假死(上限2GB,假设每行记录1KB,大概2百万条记录);
- SQL Server操作简单,没有获得安全证书,体积大,用户多时性能差,适合在Window操作系统(百万级记录);
- MySQL是开源的小型数据库,没有获得安全证书,体积小,快速,易于扩展,几乎不限用户数量,处理多达5000w以上的记录,命令执行速度最快,广泛应用于中小企业(5千万以上记录);
- Oracle性能高,获得最高ISO标准证书,管理维护麻烦,大部分企事业单位都用oracle(千万级记录);
- DB2最适合于海量数据,用于数据仓库,获得最高ISO标准认证,性能高,有很好的并行性,操作简单,在巨型企业得到广泛应用。
具体参数比较可以参考:
https://db-engines.com/en/system/Microsoft+SQL+Server%3BMySQL%3BOracle
- 除此之外,Hadoop分布式框架很流行,能处理PB级数据。后续会单独开一篇介绍Hadoop相关组件。
三、NoSQL
NoSQL(Not Only SQL),泛指非关系型的数据库。
随着web2.0的兴起,传统关系数据库在应对超大规模和高并发的纯动态网站已经显得力不从心,而这些数据可能不需要结构化存储就可以直接横向扩展,所以NoSQL数据库发展起来去很好的处理这些大的数据。[4]
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
3.1 RDBMS和NoSQL的区别[5]
我们在讲这两者的区别前先看几个理论:
3.1.1 CAP
CAP定理是指对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性(Consistency):所有节点在同一时间具有相同的数据。
在任何时间点,不管哪台服务器应答了一个请求,所有服务器都会给出同样的答案。 - 可用性(Availability):保证每个请求不管成功或失败都有应。
即使某些服务器宕机了,整个系统仍能正常工作。 - 分割容忍(Partition tolerance):系统中任意信息的丢失或失败不会影响系统的继续运作。
分区宽容度是指两台服务器之间的通信可以丢失,而系统仍能正常工作。
3.1.2 ACID
指事务数据库正确执行的四个要素,包括原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。目的是保证数据的正确性。
- 原子性(Atomic:):要么整个事务成功,要么整个不成功。
- 一致性(Consistency):数据库在事务之间处于一个一致的状态中。比方说,如果一条记录指向另一条记录,而到事务结束时这个指向是无效的,那么整个事务就必须回滚。
隔离性(Isolation):在其他事务结束之前,事务看不到被它们更改的数据。
持久性(Durability):一旦数据库系统通知用户事务成功,数据就永不丢失。
3.1.3 BASE
- Basically Available(基本可用):分布式系统在出现不可预知的故障的时候,允许损失部分可用性,但不等于系统不可用;
- Soft state(软状态):与硬状态相对,即是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时;
- Eventually consistent(最终一致性):强调系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。其本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。[6]
事实上实在没看懂这三个理论。
3.1.4 RDBMS和NoSQL区别:
- 后者不需要预定义模式:不需要事先定义数据模式,预定义表结构。数据中的每条记录都可能有不同的属性和格式。当插入数据时,并不需要预先定义它们的模式。
- 后者无共享架构:相对于将所有数据存储的存储区域网络中的全共享架构。NoSQL往往将数据划分后存储在各个本地服务器上。因为从本地磁盘读取数据的性能往往好于通过网络传输读取数据的性能,从而提高了系统的性能。
- 后者弹性可扩展:可以在系统运行的时候,动态增加或者删除结点。不需要停机维护,数据可以自动迁移。
- 分区:相对于将数据存放于同一个节点,NoSQL数据库需要将数据进行分区,将记录分散在多个节点上面。并且通常分区的同时还要做复制。这样既提高了并行性能,又能保证没有单点失效的问题。
- 后者是异步复制:和RAID存储系统不同的是,NoSQL中的复制,往往是基于日志的异步复制。这样,数据就可以尽快地写入一个节点,而不会被网络传输引起迟延。缺点是并不总是能保证一致性,这样的方式在出现故障的时候,可能会丢失少量的数据。
- RDBMS遵循ACID原则,而NoSQL有BASE原则,前者符合CAP里的CP,后者符合CAP里的AP(即前者牺牲可用性,后者牺牲一致性)[7]。
3.2 不同类型的NoSQL数据库
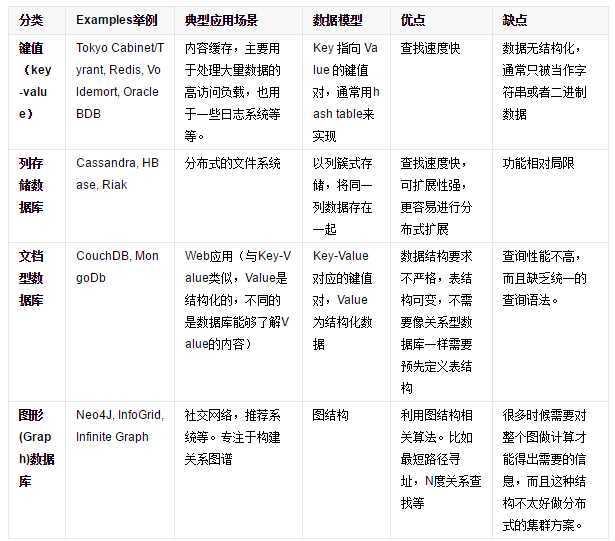
[8]
[1]数据完整性约束-百度百科
[2]范式-知乎
[3]数据量转换及几种关系型数据库优缺点比较
[4][8]NoSQL-百度百科
[5]NoSQL 简介-菜鸟教程
[6]从ACID到CAP到BASE
[7]CAP理论十二年回顾:"规则"变了