前言:存储二叉树的关键是如何表示结点之间的逻辑关系,也就是双亲和孩子之间的关系。在具体应用中,可能要求从任一结点能直接访问到它的孩子。
一、二叉链表
二叉树一般多采用二叉链表(binary linked list)存储,其基本思想是:令二叉树的每一个结点对应一个链表结点链表结点除了存放与二叉树结点有关的数据信息外,还要设置指示左右孩子的指针。二叉链表的结点结构如下图所示:
| lchild | data | rchild |
其中,data为数据域,存放该结点的数据信息;
lchild为左指针域,存放指向左孩子的指针,当左孩子不存在时为空指针;
rchild为右指针域,存放指向右孩子的指针,当右孩子不存在时为空指针;
可以用C++语言中的结构体类型描述二叉链表的结点,由于二叉链表的结点类型不确定,所以采用C++的模板机制。如下:
1 // 二叉链表的节点 2 template<class T> 3 struct BiNode 4 { 5 T data; // 数据域 6 BiNode<T>*lchild, *rchild; // 左右指针域 7 };
二、C++实现
将二叉树的二叉链表存储结构用C++的类实现。为了避免类的调用者访问BiTree类的私有变量root,在构造函数、析构函数以及遍历函数中调用了相应的私有函数。
具体代码实现如下:
1、头文件“cirqueue.h”
此头文件为队列的类实现,层序遍历要用到队列,所以自己定义了一个队列。
1 #pragma once 2 #include <iostream> 3 const int queueSize = 100; 4 template<class T> 5 class queue 6 { 7 public: 8 .... 9 T data[queueSize]; 10 int front, rear; 11 .... 12 };
2、头文件“bitree.h”
此头文件为二叉链表的类实现。
#pragma once #include <iostream> #include "cirqueue.h" // 二叉链表的节点 template<class T> struct BiNode { T data; // 数据域 BiNode<T>*lchild, *rchild; // 左右指针域 }; // 二叉链表类实现 template<class T> class BiTree { public: BiTree() { root = Creat(root); } // 构造函数,建立一颗二叉树 ~BiTree() { Release(root); } // 析构函数,释放各节点的存储空间 void PreOrder() { PreOrder(root); } // 递归前序遍历二叉树 void InOrder() { InOrder(root); } // 递归中序遍历二叉树 void PostOrder() { PostOrder(root); } // 递归后序遍历二叉树 void LeverOrder(); // 层序遍历二叉树 private: BiNode<T>* root; // 指向根节点的头节点 BiNode<T>* Creat(BiNode<T>* bt); // 构造函数调用 void Release(BiNode<T>* bt); // 析构函数调用 void PreOrder(BiNode<T>* bt); // 前序遍历函数调用 void InOrder(BiNode<T>* bt); // 中序遍历函数调用 void PostOrder(BiNode<T>* bt); // 后序遍历函数调用 }; template<class T> inline void BiTree<T>::LeverOrder() { queue<BiNode<T>*> Q; // 定义一个队列 Q.front = Q.rear = -1; // 顺序队列 if (root == NULL) return; Q.data[++Q.rear] = root; // 根指针入队 while (Q.front != Q.rear) { BiNode<T>* q = Q.data[++Q.front]; // 出队 cout << q->data; if (q->lchild != NULL) Q.data[++Q.rear] = q->lchild; // 左孩子入队 if (q->rchild != NULL) Q.data[++Q.rear] = q->rchild; // 右孩子入队 } } template<class T> inline BiNode<T>* BiTree<T>::Creat(BiNode<T>* bt) { T ch; cin >> ch; // 输入结点的数据信息,假设为字符 if (ch == ‘#‘) // 建立一棵空树 bt = NULL; else { bt = new BiNode<T>; // 生成一个结点,数据域为ch bt->data = ch; bt->lchild = Creat(bt->lchild); // 递归建立左子树 bt->rchild = Creat(bt->rchild); // 递归建立右子树 } return bt; } template<class T> inline void BiTree<T>::Release(BiNode<T>* bt) { if (bt != NULL) { Release(bt->lchild); // 释放左子树 Release(bt->rchild); // 释放右子树 delete bt; // 释放根节点 } } template<class T> inline void BiTree<T>::PreOrder(BiNode<T>* bt) { if (bt == NULL) // 递归调用的结束条件 return; cout << bt->data; // 访问根节点bt的数据域 PreOrder(bt->lchild); // 前序递归遍历bt的左子树 PreOrder(bt->rchild); // 前序递归遍历bt的右子树 } template<class T> inline void BiTree<T>::InOrder(BiNode<T>* bt) { if (bt == NULL) return; InOrder(bt->lchild); cout << bt->data; InOrder(bt->rchild); } template<class T> inline void BiTree<T>::PostOrder(BiNode<T>* bt) { if (bt == NULL) return; PostOrder(bt->lchild); PostOrder(bt->rchild); cout << bt->data; }
说明:1、除了层序遍历,其他遍历均为递归算法。
2、为什么层序遍历使用队列:在进行层序遍历时,对某一层的结点访问完后,再按照它们的访问次序对各个结点的左孩子和右孩子顺序访问,这样一层一层进行,先访问的结点其左右孩子也要先访问,这符合队列的操作特性,因此,在进行层序遍历时,可设置一个队列存放已访问的结点。
3、构造函数对二叉树的特殊处理:将二叉树中每个结点的空指针引出一个虚结点,其值为一特定值,如‘#’,以标识其为空。
4、二叉链表属于动态内存分配,需要在析构函数中释放二叉链表的所有结点。在释放某结点时,该结点的左右都子树已经释放,所以应该采用后序遍历。
3、主函数
1 #include"bitree.h" 2 using namespace std; 3 4 int main() 5 { 6 BiTree<char>* bitree=new BiTree<char>(); // 创建一棵二叉树 7 bitree->PreOrder(); // 前序遍历 8 cout << endl; 9 bitree->InOrder(); // 中序遍历 10 cout << endl; 11 bitree->PostOrder(); // 后序遍历 12 cout << endl; 13 bitree->LeverOrder(); // 层序遍历 14 delete bitree; 15 16 system("pause"); 17 return 0; 18 }
三、实例
建立如下二叉树,并输出四种遍历的结果。
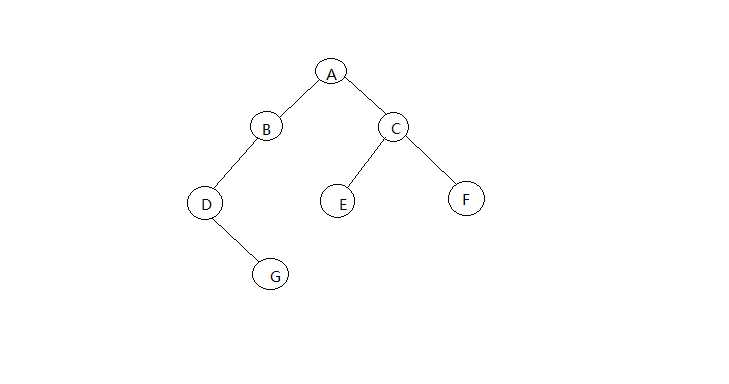
运行结果:

结果正确。
参考文献:
[1]王红梅, 胡明, 王涛. 数据结构(C++版)[M]. 北京:清华大学出版社。
马上元旦了,祝大家元旦快乐!!2017-12-29