1. 系统要求
1. Java运行环境 —— Java 1.8及以上
2. 内存 —— 足够的内存供配置的sources,channels 或者sinks使用
3. 硬盘空间 —— 足够的硬盘空间供配置的channels或者sinks使用
4. 文件权限 —— agent使用的文件夹读写权限
2. 架构及数据流模型
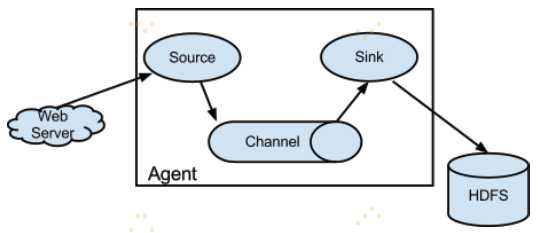
模型介绍详情参考:http://www.cnblogs.com/swordfall/p/8093464.html
3. 创建
3.1 创建一个Agent
Flume agent配置存储在一个本地的配置文件。这个text文件遵循Java配置文件格式。配置一个或多个agents可以在同一配置文件中。配置文件包含一个agent里的每一个source,sink和channel,以及它们怎样连接在一起,形成数据流。在流中每个组件(source,sink或者channel)有名字,类型和一系列配置。如,Avro source有hostname和port。内存channel可以有最大队列值(如capacity),HDFS sink有文件系统URI路径。
3.1.1 启动一个agent
agent需要使用flume-ng shell脚本启动运行,该脚本位于Flume文件夹的bin目录下。你需要在命令中指定agent名,config目录和config文件:

3.1.2 一个简单示例
下述是单节点Flume部署配置文件。该配置文件让用户生成Events并随后在控制台记录出来。
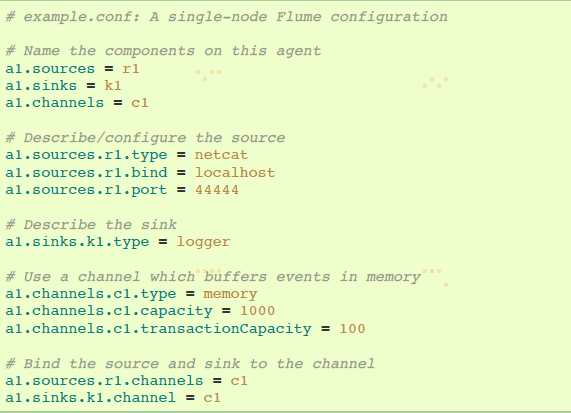
这个配置定义了一个简单agent,叫a1。a1 有一个source监听数据端口44444,一个channel在内存中缓存event数据,还有一个sink在控制台记录event日志。配置文件命名变量组件,然后描述组件的类型和配置属性。一个配置好的文件可能定义了几个不同的agent;当一个Flume进程运行时需要说明启动哪个agent。查看如下命令:

注意:一个完整部署应该包含多一个option:--conf=<conf-dir>。<conf-dir>目录包含flume-env.sh shell脚本和log4j配置文件。在这个例子中,我们通过Java选择强制Flume在控制台打印日志,没有通过传统的环境脚本。
通过一个独立终端,我们可以telnet port 44444 并给Flume发送一个event:

Flume原来的终端在log消息中打印event:

3.1.3 在配置文件中使用环境变量

这要实现需要设置 propertiesImplementation = org.apache.flume.node.EnvVarResolverProperties
Flume启动命令例如:
$ NC_PORT=44444 bin/flume-ng agent –conf conf –conf-file example.conf –name a1 -Dflume.root.logger=INFO,console -DpropertiesImplementation=org.apache.flume.node.EnvVarResolverProperties
注意环境变量也可以在conf/flume-env.sh文件中配置
3.1.4 记录原始数据
在许多生产环境不期望记录摄取通道上的原始数据流,因为这也许导致Flume日志文件泄漏敏感数据或者安全相关的配置,如密钥。默认的,Flume不会记录这类信息。另一方面,如果数据通道被打断,Flume会尝试提供调试问题的线索。
调试event管道上的问题的方法是去设置一个额外Memory Channel连接Logger Sink,这会在Flume logs上输出所有event 数据。在一些情况下,然而,这方法是不够的。
为了能记录event-和配置相关的数据,一些Java系统属性必须设置在log4j配置上。
启用配置相关的日志记录,设置Java系统属性 -Dorg.apache.flume.log.printconfig=true。这可以在命令行设置或者在flume-env.sh文件Java_OPTS变量设置。
启用数据日志记录,在上面描述的同样方法中设置-Dorg.apache.flume.log.rawdata=true。对于大多数组件,为了使event特定的日志出现在Flume日志中,log4j日志级别设置为DEBUG或者TRACE。下面例子,当设置Log4j 日志级别为DEBUG时,控制台能同时打印出配置日志和原始数据日志:
bin/flume-ng agent --conf conf --conf-file example.conf --name a1 -Dflume.root.logger=DEBUG,console -Dorg.apache.flume.log.printconfig=true -Dorg.apache.flume.log.rawdata=true

3.1.5 基于Zookeeper的配置
Flume通过Zookeeper支持Agent配置。这是实验性功能。配置文件需要上传到Zookeeper,有可配置的前缀。配置文件保存在Zookeeper Node data节点上。
一旦配置文件上传,启动带有下述选项的agent:
$ bin/flume-ng agent –conf conf -z zkhost:2181,zkhost1:2181 -p /flume –name a1 -Dflume.root.logger=INFO,console
| Argument Name | Default | Description |
|---|---|---|
| z | – | Zookeeper connection string. Comma separated list of hostname:port |
| p | /flume | Base Path in Zookeeper to store Agent configurations |
3.2 提取数据
3.2.1 RPC方式
Flume distribution包含的Avro客户端可以通过使用avro RPC机制发送文件到Flume Avro source.

上面命令将会在41414端口发送/usr/log.10文件内容发送到Flume source.
3.2.2 Network streams
FLume支持下面机制去从log流类型读取数据, 如: 1. Avro 2. Thrift 3. Syslog 4. Netcat
3.2.3 设置多个agent流
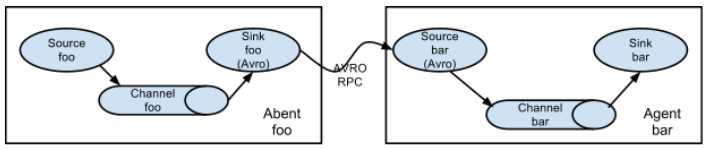
为了使数据流通多个agents或者hops, 前一个agent的sink和当前hop的source需要是avro类型, 同时sink指向source的hostname(或者IP地址)和port.
3.2.4 合并
大量的日志生成客户端发送数据到几个消费者agents, 这些agents连接着存储系统.例如, 几百个web servers收集的日志发送到多个agents, 最后agents写进HDFS集群.
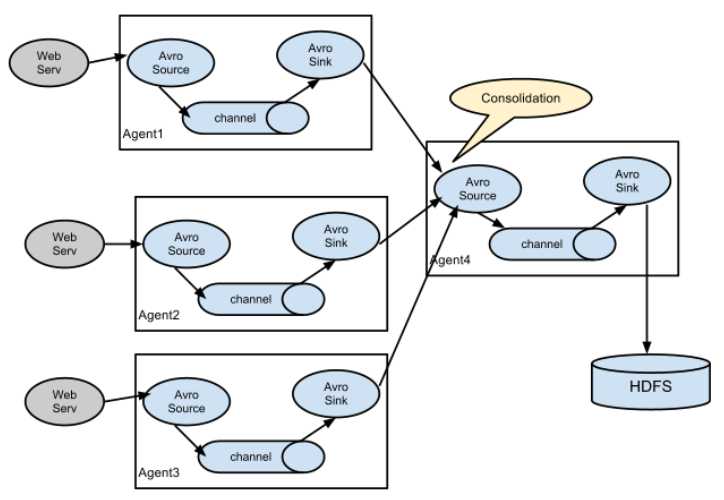
通过配置多个带有avro sink的一级agents, 然后全部指向单独agent的avro source(或者使用thrift sources/sinks/clients), 这在Flume上是可以实现的.二级agent的source合并接收的events进一个单独channel, 这个channel里面的events会被一个sink消费后进入到最终目的地.
3.2.5 多路复用流程
Flume支持复用event流向一个或多个目的地。通过定义可复制或者选择性地将event路由到一个或多个channels的流复用器实现。
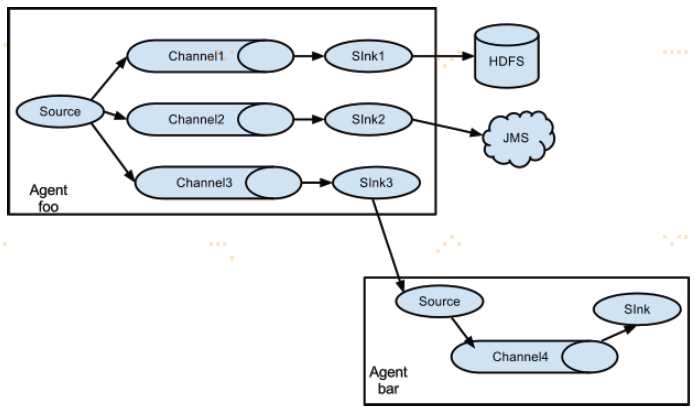
上述例子展示了一个agent "foo"的source把流量分散到三个不同的channels。这分散可以被复制或复用。在复制流量的情况下,每个event都被发送到三个channels。对于复用情况,当一个event的属性匹配到预配置的值时,该event被传递到可用channels的子集。例如,如果一个event属性“txnType” 被设置为“customer”,然后它应该去channel1和channel3,如果它是“vendor”,然后它应该去channel2,否则channel3。这个映射可以设置在agent的配置文件中。
4. 配置
4.1 定义flow
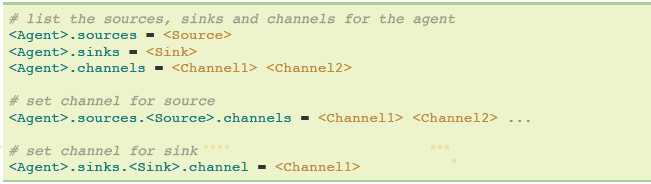
在一个简单agent中定义流程,你需要通过一个channel连接sources和sinks。你需要为给出的agent列出sources,sinks和channels,然后j将source和sink指向channel。一个source实例可以指定多个channels,但是一个sink实例只能指定一个channel。格式为下述:
举例,一个名叫agent_foo的agent从外部avro client读取数据,然后通过一个memory channel发送数据到HDFS。配置文件类似如下:
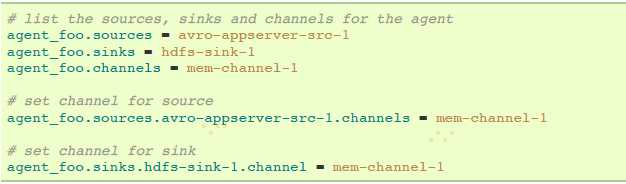
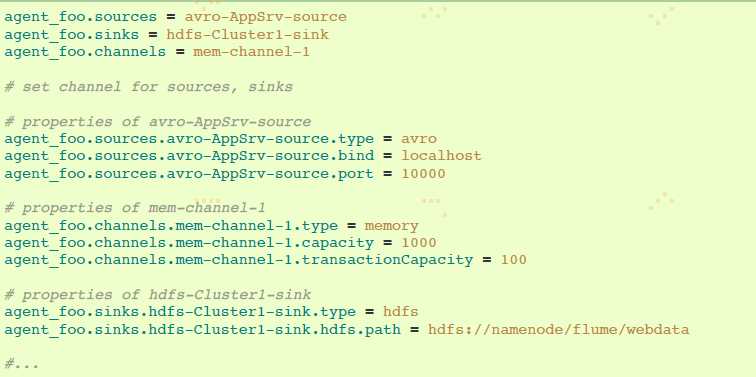
这个将会使events通过memory channel mem-channel-1从avro-AppSrv-source流向hdfs-sink-1。
4.2 配置单个组件
定义流程之后,你需要设置每个source、sink和channel的配置。在相同的阶级式名称空间中,你可以为每个组件特定的属性设置组件类型和其他值。
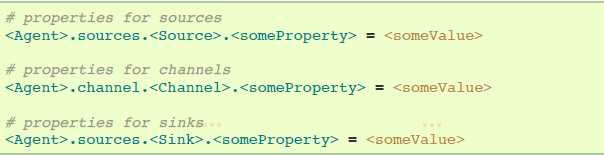
Flume的每个组件都需要设置类型“type”,为了指明组件需要成为哪种对象类型。每个source、sink和channel类型各自有一系列功能属性。当需要时,它们需要被设置出来。上一个例子,我们有通过memory channel mem-channel-1从avro-AppSrv-Source到hdfs-Cluster1-sink的流程。下面例子展示那些组件的配置:
4.3 在一个agent中添加多个流程
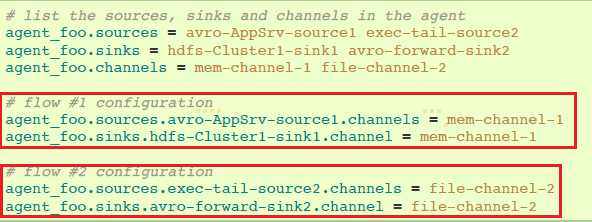
一个简单Flume agent可以包含多个独立的流程。你可以在配置中列出多个sources、sinks和channels。这些组件可以链接形成多个流程:

你可以将sources和sinks链接到它们相应的channels,建立两个不同的流程。例如,如果你需要在一个agent建立两个流程,一个从外部avro client到外部HDFS,另一个从tail输出到avro sink,配置如下:
4.4 配置一个多agent流程
为了建立一个多层流程,你需要第一层的avro/thrift sink 指向下一层的avro/thrift source。这将会导致第一个Flume agent的events转发给下一个Flume agent。例如,你正在用avro client定期发送文件(一个文件即为event)到本地的Flume agent,然后这个本地agent会把文件转发给另一个有存储功能的agent。
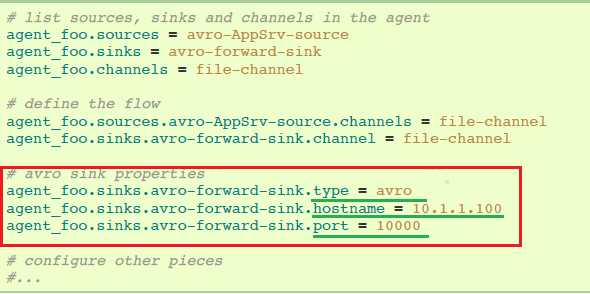
Weblog agent配置:
HDFS agent配置:
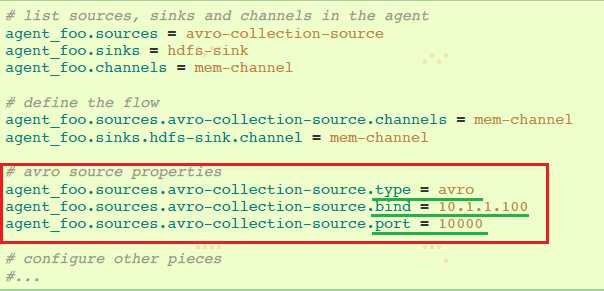
这里,我们将weblog agent的avro-forward-sink链接到hdfs agent的avro-collection-source。这导致来自外部appserver source的events最终存储在HDFS中。
4.5 分散流程
如上节讨论的那样,Flume支持从一个source到多个channels的分散流程。分散有两种模式,复制(replicating)和复用(multiplexing)。在复制流程中,event将会被发送到全部配置的channels。在复用情况下,event只会被发送到符合要求的channels。在分散流程中,需要指定source的channels列表和分散规则。添加一个channel "selector",可以是replicating或者multiplexing,然后指定选择规则,如果你没有指定一个selector,默认replicating:
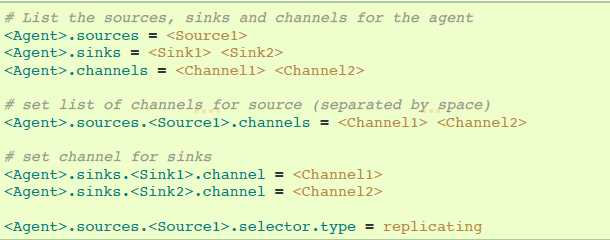
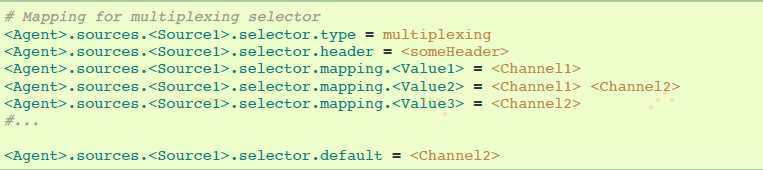
复用选择有一系列属性去分流流程。这要求在channel设置指定event属性的mapping。selector在event的header检查每个配置的属性。如果匹配到指定的值,该event会被发送到映射该值的channels。如果没有匹配到,event将会发送到配置好默认的channels。
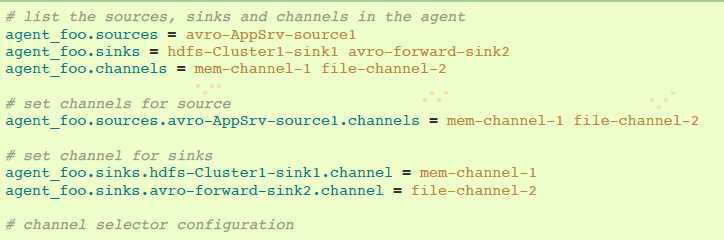
下面的例子展示,一个简单流程多路复用到两条路径。名叫agent_foo的agent有一个简单avro source和两个链接到两个sinks的channels:

selector检查叫“State”的header。如果值为“CA”,然后它所属的event将会被发送到mem-channel-1,如果值为“AZ”则发送到file-channel-2,或者值为“NY”则两个channels都发送。如果“State“ header没有设置或者匹配不到三个值中的一个,则event被发送到默认的mem-channel-1。
selector也支持可选的channel。为header指定可选的channels,配置属性‘optional’可以像下面那样使用:
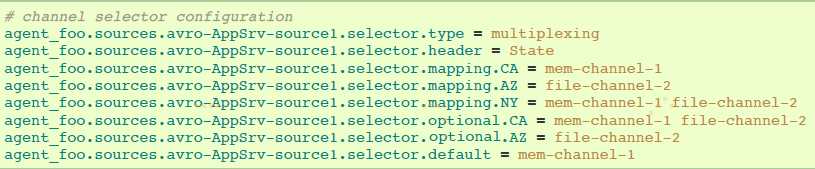
selector第一次将会尝试向要求的channels发送events,如果这些channels消费events失败,则提交事务失败,事务将会再次向这些channels提交。一旦要求的channels消费完这些events,selector将会向可选的channels发送events。如果这些可选channels消费失败,将会被忽略,不会再次提交事务。
注意:如果header没有要求的channels,events将会写进默认channels,也会试图写进可选的channels。如果没有要求channels指定,指定可选的channels将会同样造成event被写进默认channels。如果没有默认的和要求的channels,selector将会把events试图写进可选channels。在这种情况下,失败将会被忽略。
4.6 Flume Sources
4.6.1 Avro Source
监听Avro端口,从Avro client streams接收events。要求属性是粗体字。

agent a1例子:

ipFilterRules例子:
ipFilterRules=allow:ip:127.*, allow:name:localhost,deny:ip:*
4.6.2 Thrift Source
监听Thrift端口和从外部Thrift client streams接收events。要求属性为粗体字:
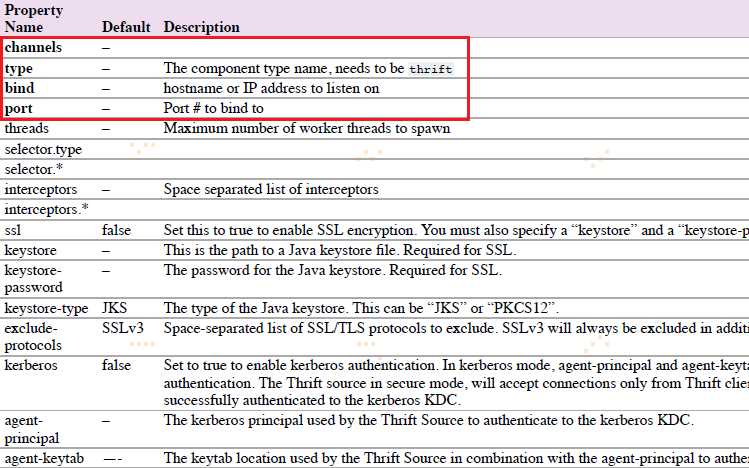
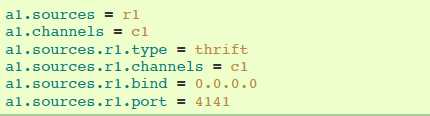
agent a1 例子:
4.6.3 Exec Source
Exec Source在启动时运行一个Unix命令行,并期望这过程在标准输出上连续生产数据。要求属性为粗体字:

agent a1例子:

‘shell‘配置被用来通过一个命令shell调用‘command’。

4.6.4 JMS Source
JMS Source从JMS目标(如队列或者主题)读取消息。JMS应用程序应该可以与任何JMS提供程序一起工作,但是只能使用ActiveMQ进行测试。要求属性是粗体字。
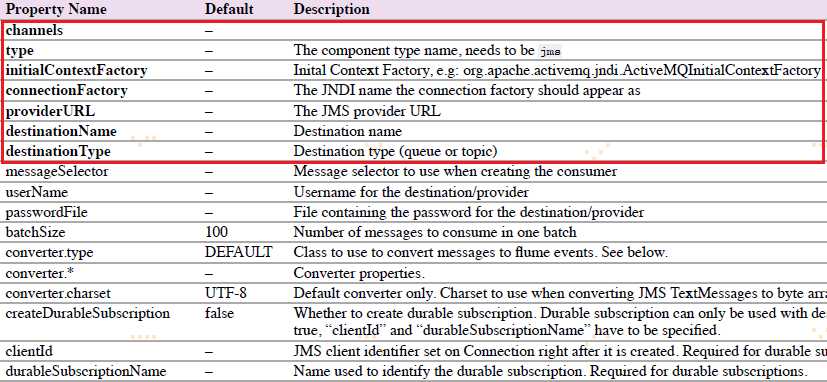
agent a1例子:

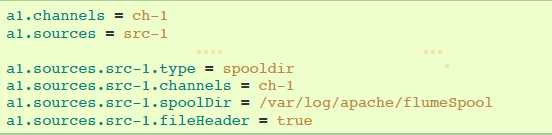
4.6.5 Spooling Directory Source
该source让你通过放置被提取文件在磁盘”spooling“目录下这一方式,提取数据。该source将会监控指定目录的新增文件,当新文件出现时解析event。event解析逻辑是可插入的。当一个给定文件被全部读取进channel之后,它被重命名,以标识为已完成(或者可选择deleted)。
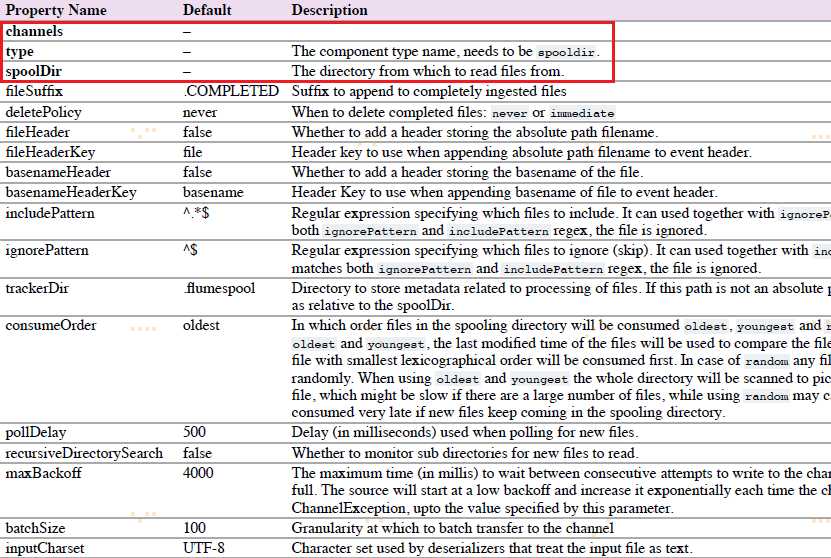

agent-1例子:
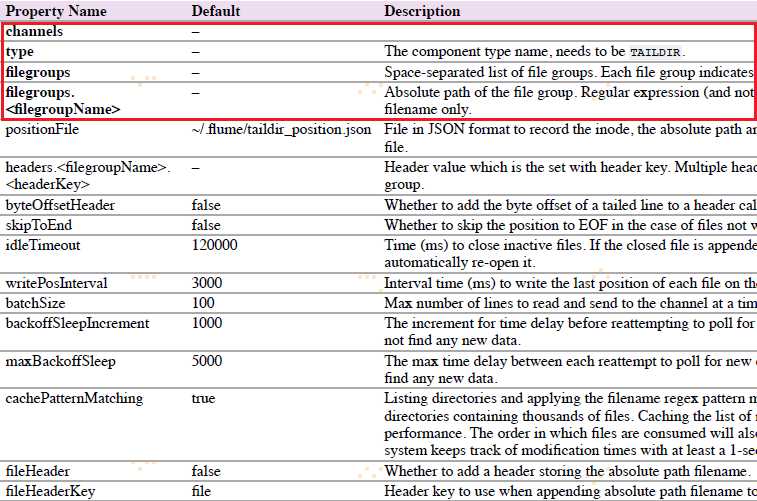
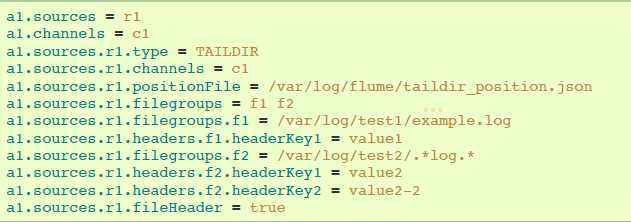
4.6.6 Taildir Source
注意:该source不能用于windows。
agent a1例子:
4.6.7 Twitter 1% firehose Source(试验)
略
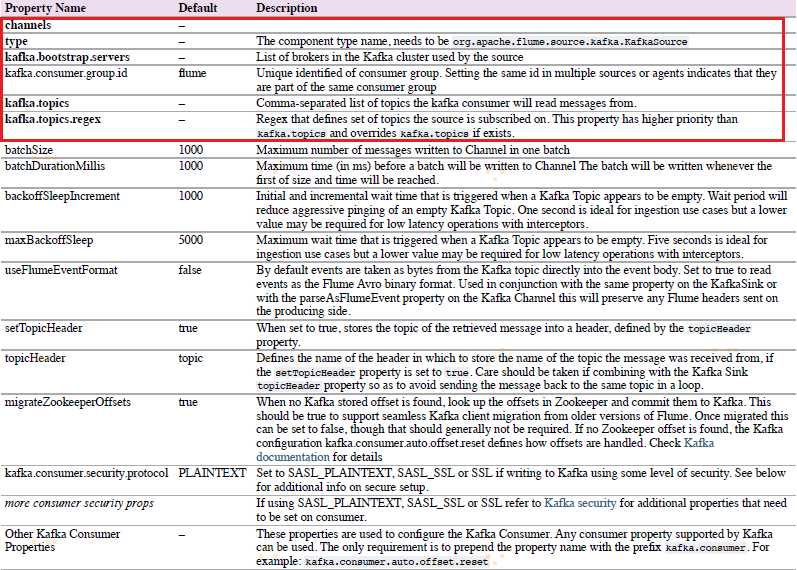
4.6.8 Kafka Source
Kafka Source是Apache Kafka消费者,从Kfaka topics读取消息。如果你有多个Kafka source在跑,你可以配置它们在相同的Consumer Group,以使它们每个读取topics独特的分区。
以逗号分隔的topic列表进行topic订阅的例子:
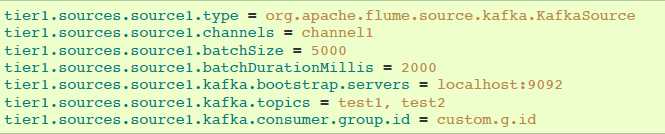
通过正则表达式进行topic订阅的例子:

安全和Kafka Source
Kafka 0.9.0支持SASL/GSSAPI 或者 SSL 协议。
设置 kafka.consumer.security.protocol的值:
①SASL_PLAINTEXT - Kerberos or plaintext authentication with no data encryption
②SASL_SSL - Kerberos or plaintext authentication with data encryption
③SSL - TLS based encryption with optional authentication.
TLS和Kafka Source
带有服务端认证和数据加密配置的例子:

注意:属性ssl.endpoint.identification.algorithm没有定义,因此没有hostname验证,为了是hostname验证,可以设置属性:

如果要求有客户端认证,在Flume agent配置中添加下述配置。每个Flume agent必须有它的客户端凭证,以便被Kafka brokers信任。

如果keystore和key使用不用的密码保护,那么ssl.key.password属性需要提供出来:

Kerberos和Kafka Soure:
kerberos配置文件可以在flume-env.sh通过JAVA_OPTS指定:

使用SASL_PLAINTEST的安全配置示例:

使用SASL_SSL的安全配置示例:

JAAS文件实例(暂时没看懂):

4.6.9 NetCat TCP Source
netcat source监听一个给定的端口,然后把text文件的每一行转换成一个event。要求属性是粗体字。

agent a1示例:
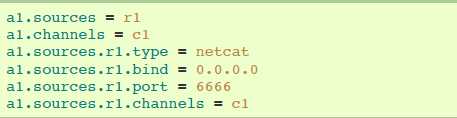
4.6.10 NetCat UDP Source
netcat source监听一个给定的端口,然后把text文件的每一行转换成一个event。要求属性是粗体字。


agent a1的示例:
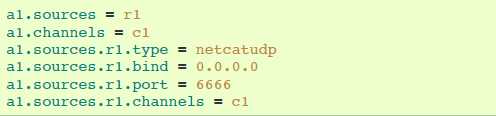
4.6.11 Sequence Generator Source
一个简单的序列生成器可以不断生成events,带有counter计数器,从0开始,以1递增,在totalEvents停止。当不能发送events到channels时会不断尝试。
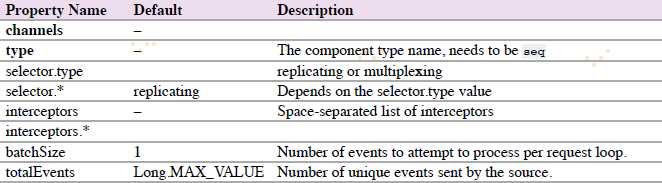
agent a1示例:

4.6.12 Syslog Sources
读取系统日志,并生成Flume events。UDP source以整条消息作为一个简单event。TCP source以新一行”n“分割的字符串作为一个新的event。
4.6.12.1 Syslog TCP Source
原始的,可靠的Syslog TCP source。
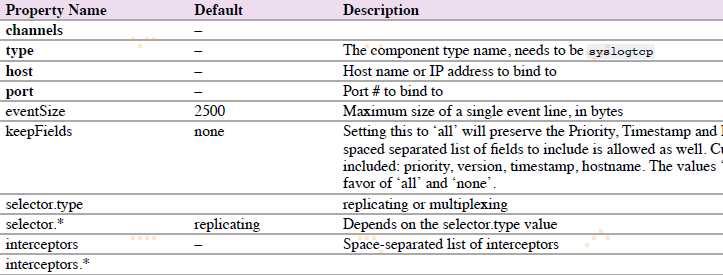
agent a1的syslog TCP source示例:
4.6.12.2 Multiport Syslog TCP Source
这是一个新的,更快的,多端口的Syslog TCP source版本。注意ports配置替代port。
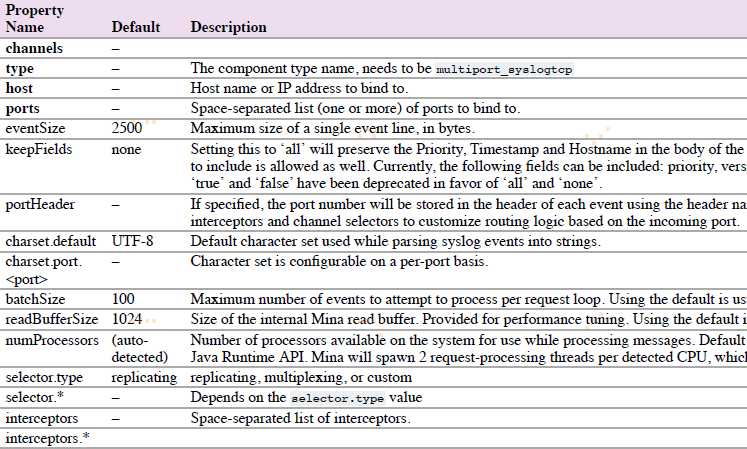
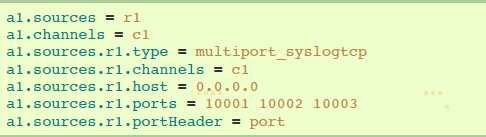
agent a1的multiport syslog TCP source示例:
4.6.12.3 Syslog UDP Source
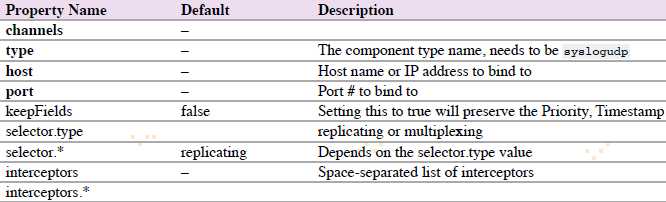
agent a1的syslog UDP source示例:
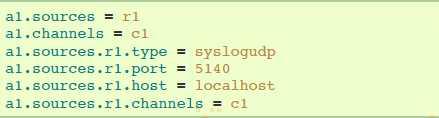
4.6.13 HTTP Source
source 通过HTTP POST 和 GET,接收Flume events。GET只能用于试验。HTTP requests通过 必须实现 HTTPSourceHandler接口的 ”handler“ 转换成flume events。该handler获取HttpServletRequest,然后返回一系列的flume events。
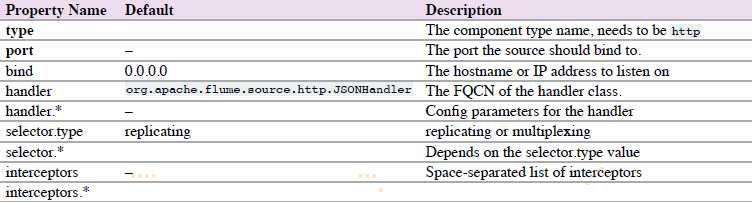

agent a1的http source示例:
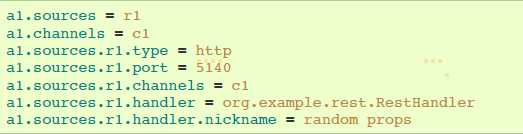
Handler属性有两种,一是JSONHandler,一是BlobHandler。
BlobHandler用于处理请求参数带有比较大的对象(Binary Large Object),如PDF或者JPG。

4.6.14 Stress Source
StressSource 是内部负载生成source的实现,这对于压力测试是非常有用的。它允许用户配置Event有效载荷的大小。

agent a1的示例:

4.6.15 Legacy Sources
legacy sources允许Flume 1.x agent接收来自Flume 0.9.4 agents的events。
legacy source 支持Avro和Thrift RPC 连接。为了使用两个Flume 版本搭建的桥梁,你需要开始一个带有avroLegacy或者thriftLegacy source的Flume 1.x agent。0.9.4agent应该有agent Sink指向1.x agent的host/port。
4.6.15.1 Avro Legacy Source
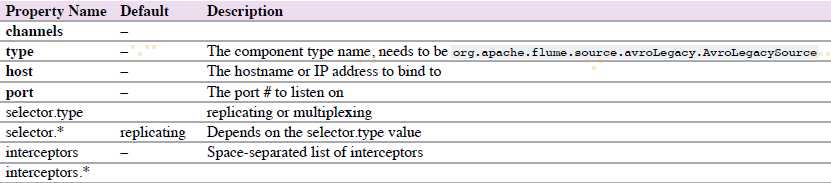
agent a1的示例:

4.6.15.2 Thrift Legacy Source
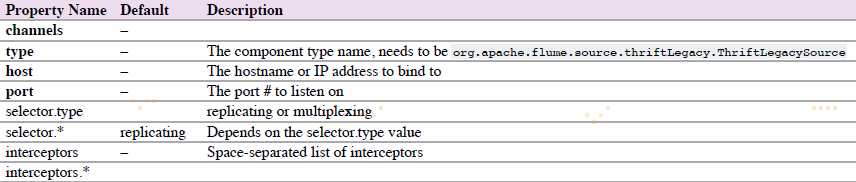
agent a1的示例:

4.6.16 Custom Source(自定义Source)
自定义Source是你实现Source接口。当启动Flume agent时,一个自定义source类和它依赖项必须在agent的classpath中。
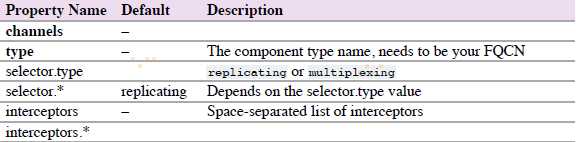
agent a1的示例:

4.6.17 Scrible Source
Scribe是另一种类型的提取系统。采用现有的Scribe提取系统,Flume应该使用基于Thrift的兼容传输协议的ScribeSource。


agent a1示例:

参考资料: