关系型数据库的局限
NoSql出现在关系型数据库之后,主要是为了解决关系型数据库的短板,我们先来看看随着软件行业的发展,关系型数据库面临了哪些挑战:
1、高并发
一个最典型的就是电商网站,例如双11,几亿大军的点击造成在某一时刻的并发量是很高的,传统的关系型数据库肯定已经是不堪重负了,如Oracle的Session数量推荐的才只有500。
2、高效率存储海量数据
大数据时代,数据量已经不是用GB、TB来衡量了,而是EB、ZB了,面对这海量的数据,如何高效率的存储这些数据,关系型数据库无法解决这个问题,以Oracle为例,单机的物理扩展不仅成本高,而且难度也加大了。
3、高可用&高扩展
Oracle即使RAC能扩展数台机器,但数量也是有限。
NoSql的出现即是为了解决这些问题了,但是NoSql并不是用来替代关系型数据库的,因为它本身也有着不可克服的缺陷,俗话说,好处不可能都让你占了。
关系型数据库与NoSql一致性的比较
一般来说,构建NoSql,为了高可用和海量数据存储,我们会选择牺牲一致性,但这并不意味着我们不要一致性,而是我们可以选择不实现强一致性,而实现弱一致性或者最终一致性。无论是在关系型数据库或者NoSql中,我们都是通过事务来实现一致性,下面我们来讨论两者在一致性方面的差异:
关系型数据库事务的4个基本特性ACID,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
而对于分布式事务的特性BASE,则是反这个标准的,即基本可用(Basically Availble)、软状态/柔性事务(Soft-state)、最终一致性(Eventual Consistency)。下面是Brewer教授在PODC大会展示的ACID vs BASE:
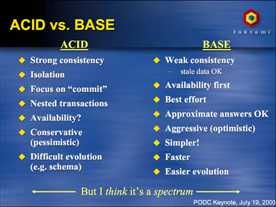
前面我们说过,NoSql的出现是为了解决高并发、海量数据、高可用等问题的,因而一般分布式是最优选项,我们先来说一下分布式系统的特性:CAP理论,当然,这也是NoSql的特性:
CAP理论
CAP理论是Brewer教授提出的:一个分布式系统不能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Tolerance of network Partition)。鱼和熊掌不可兼得。
一致性:任何一个读操作总是能读取到之前完成的写操作结果,也就是在分布式环境中,多点的数据是一致的。
可用性:每一个操作总是能在确定的时间内返回,也不是系统随时都是可用的。
分区容错性:在出现网络分区(如断网)的情况下,分离的系统也能正常运行。
PS:这里有人可能会问,可用性与分区容错性是不是一个意思(既然分区都可以容错了,不就是可用么),个人理解这里可用性说的是调用不会被阻塞。
而市场上的NoSql则以CAP理论为指导,大多选择实现了CAP理论的两点(如CA、CP、AP),未实现的即其缺陷部分。下面则是常见NoSql系统的特性:
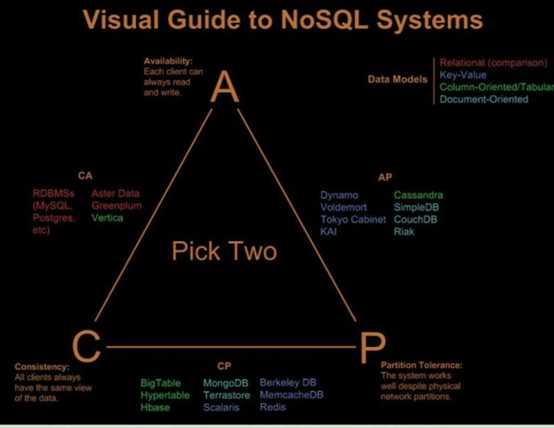
常见NoSql的分类
|
类型 |
部分代表 |
特点 |
|
列存储 |
Hbase Cassandra Hypertable |
顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。 |
|
文档存储 |
MongoDB CouchDB |
文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有有机会对某些字段建立索引,实现关系数据库的某些功能。 |
|
kv存储 |
Tokyo Cabinet / Tyrant Berkeley DB MemcacheDB Redis |
可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) |
|
图存储 |
Neo4J FlockDB |
图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 |
|
对象存储 |
db4o Versant |
通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 |
|
xml数据库 |
Berkeley DB XML |
高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath。 |
参考文档
https://www.zhihu.com/question/54105974
http://blog.sina.com.cn/s/blog_3fe961ae010139u6.html
https://www.cnblogs.com/chaser24/p/6417757.html
https://baike.baidu.com/item/NoSQL/8828247
http://www.studyofnet.com/news/365.html