前面一篇应该算是比较详细的介绍了spark的基础知识,在了解了一些spark的知识之后相必大家对spark应该不算陌生了吧!如果你之前写过MapReduce,现在对spark也很熟悉的话我想你再也不想用MapReduce去写一个应用程序了,不是说MapReduce有多繁琐(相对而言),还有运行的效率等问题。而且用spark写出来的程序比较优雅,这里我指的是scala版的,如果你用java版的spark去写一个应用程序,对比scala版的,想必你肯定会爱上scala这门语言的,哈哈哈(以上纯属个人观点,具体场景具体对待)
实现目标1:根据采集的日志信息,统计总的pv量 。
需求分析:在大数据领域,采集数据的常采用的手段就是怼网站进行埋点然后根据需求收集相关的数据,这里我们用的是最基本的日志信息来做处理,数据来源于某网站,可以分享出来给大家使用,完了后我会将代码还有数据 文件放到GitHub上供大家下载。首先我们来看看日志文件(access.log)的格式:
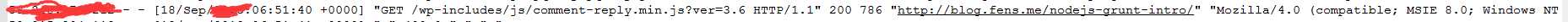
这是标准的一条日志信息,当然我们如果是统计网站的pv总量的话不需要考虑对日志进行清洗的工作。以下是pv统计的代码:
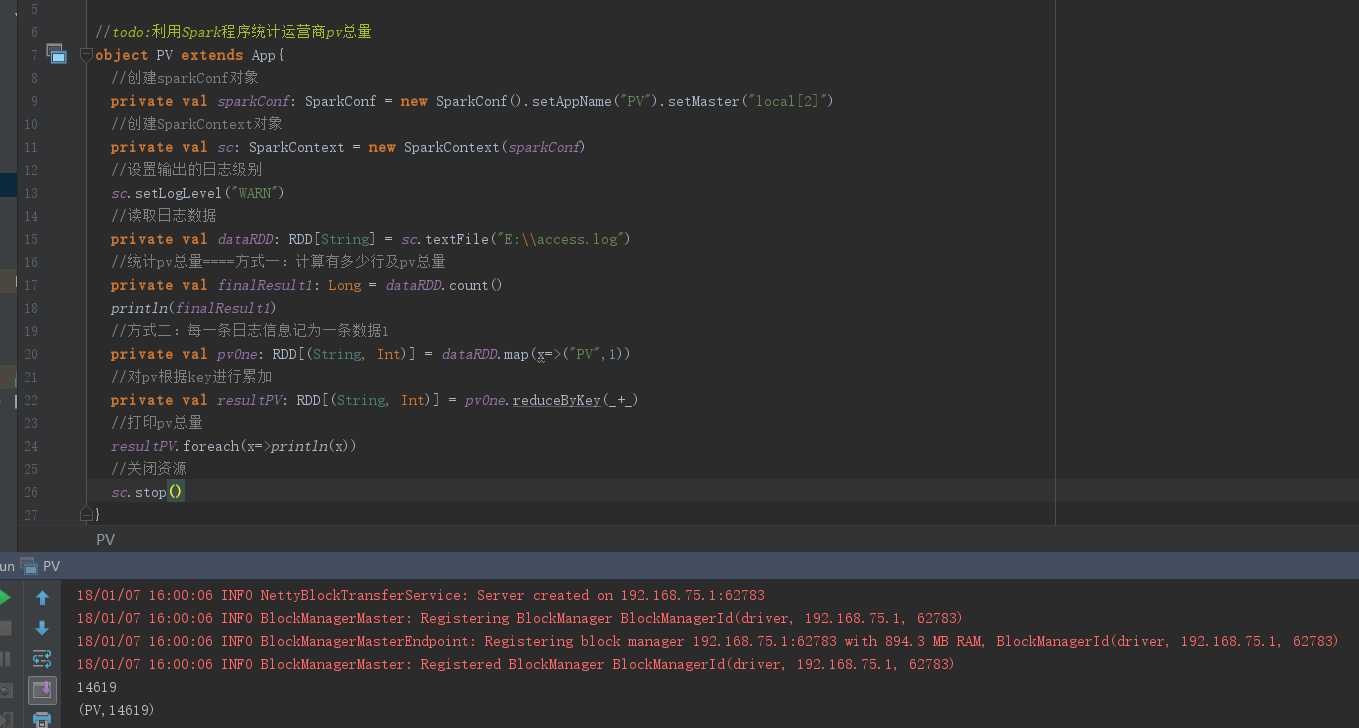
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} //todo:利用Spark程序统计运营商pv总量 object PV extends App{ //创建sparkConf对象 private val sparkConf: SparkConf = new SparkConf().setAppName("PV").setMaster("local[2]") //创建SparkContext对象 private val sc: SparkContext = new SparkContext(sparkConf) //设置输出的日志级别 sc.setLogLevel("WARN") //读取日志数据 private val dataRDD: RDD[String] = sc.textFile("E:\\access.log") //统计pv总量====方式一:计算有多少行及pv总量 private val finalResult1: Long = dataRDD.count() println(finalResult1) //方式二:每一条日志信息记为一条数据1 private val pvOne: RDD[(String, Int)] = dataRDD.map(x=>("PV",1)) //对pv根据key进行累加 private val resultPV: RDD[(String, Int)] = pvOne.reduceByKey(_+_) //打印pv总量 resultPV.foreach(x=>println(x)) //关闭资源 sc.stop() }
结果如下:
实现目标2:根据采集的日志信息,统计总的uv量 。
需求分析:目标数据文件还是access.log,比较简单,直接看代码:
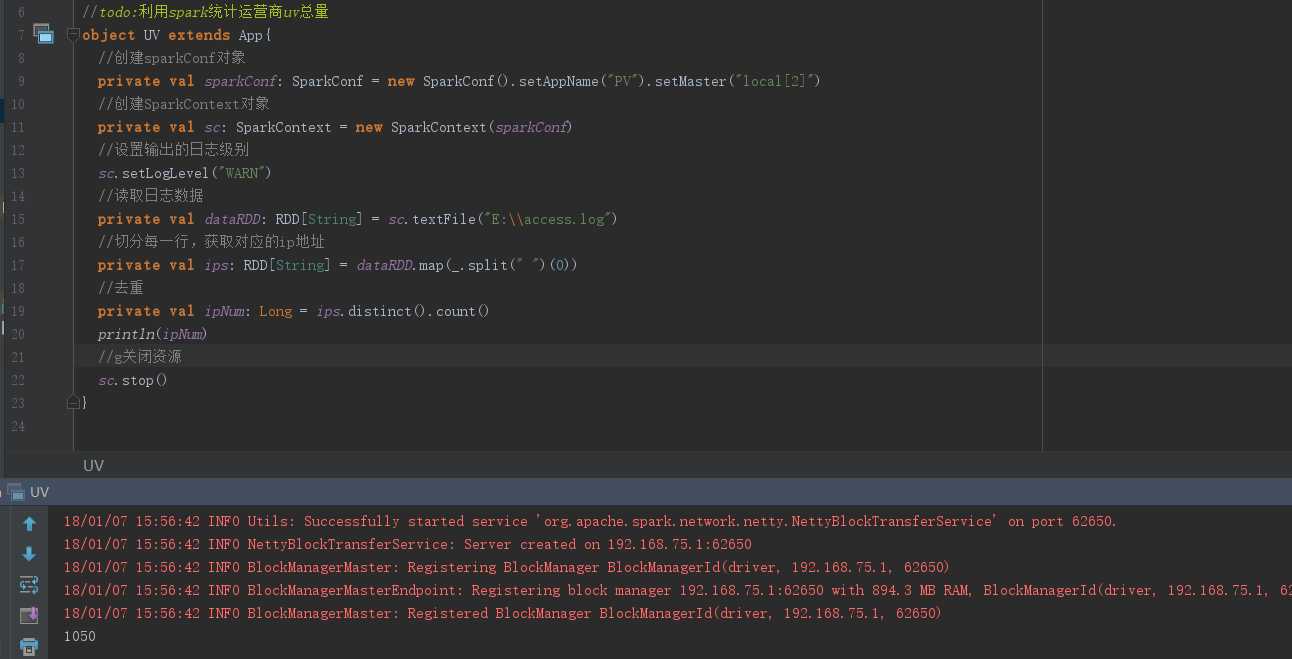
import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.rdd.RDD //todo:利用spark统计运营商uv总量 object UV extends App{ //创建sparkConf对象 private val sparkConf: SparkConf = new SparkConf().setAppName("PV").setMaster("local[2]") //创建SparkContext对象 private val sc: SparkContext = new SparkContext(sparkConf) //设置输出的日志级别 sc.setLogLevel("WARN") //读取日志数据 private val dataRDD: RDD[String] = sc.textFile("E:\\access.log") //切分每一行,获取对应的ip地址 private val ips: RDD[String] = dataRDD.map(_.split(" ")(0)) //去重 private val ipNum: Long = ips.distinct().count() println(ipNum) //g关闭资源 sc.stop() }
结果 如下:
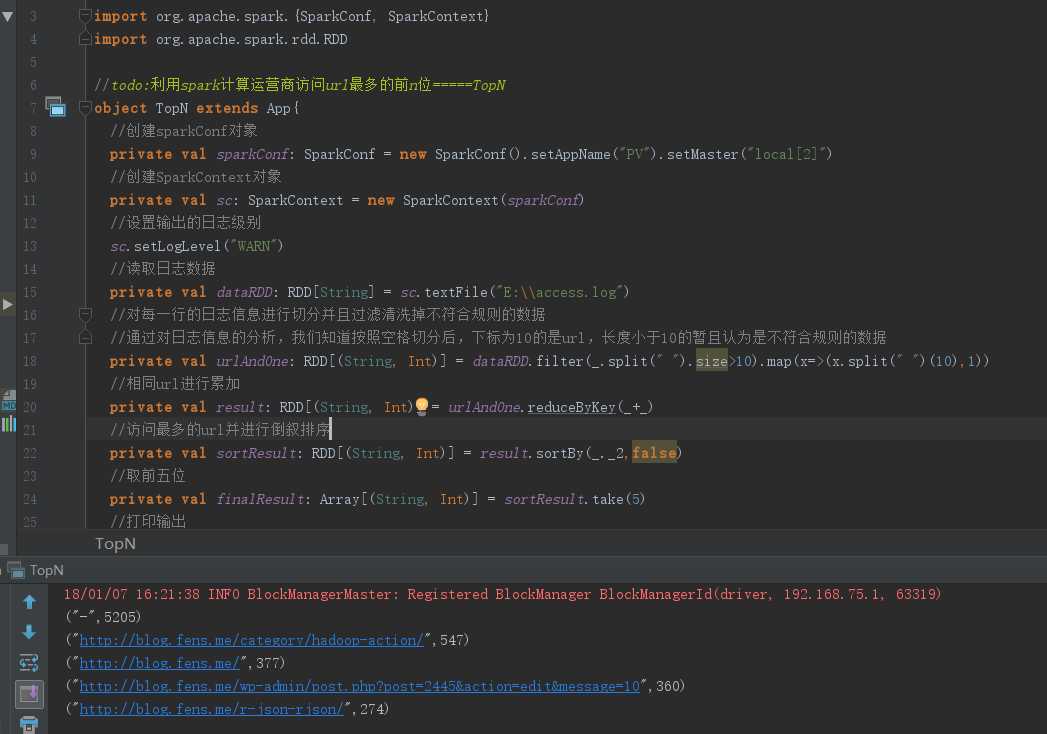
实现目标3:根据采集的日志信息,统计访问最多的前五位网站降序排列 TopN。
import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.rdd.RDD //todo:利用spark计算运营商访问url最多的前n位=====TopN object TopN extends App{ //创建sparkConf对象 private val sparkConf: SparkConf = new SparkConf().setAppName("PV").setMaster("local[2]") //创建SparkContext对象 private val sc: SparkContext = new SparkContext(sparkConf) //设置输出的日志级别 sc.setLogLevel("WARN") //读取日志数据 private val dataRDD: RDD[String] = sc.textFile("E:\\access.log") //对每一行的日志信息进行切分并且过滤清洗掉不符合规则的数据 //通过对日志信息的分析,我们知道按照空格切分后,下标为10的是url,长度小于10的暂且认为是不符合规则的数据 private val urlAndOne: RDD[(String, Int)] = dataRDD.filter(_.split(" ").size>10).map(x=>(x.split(" ")(10),1)) //相同url进行累加 private val result: RDD[(String, Int)] = urlAndOne.reduceByKey(_+_) //访问最多的url并进行倒叙排序 private val sortResult: RDD[(String, Int)] = result.sortBy(_._2,false) //取前五位 private val finalResult: Array[(String, Int)] = sortResult.take(5) //打印输出 finalResult.foreach(println) sc.stop() }
运行结果: