2.可优化语句的执行
可优化语句的共同特点是它们被查询编译器处理后都会生成査询计划树,这一类语句由执行器(Executor)处理。该模块对外提供了三个接口: ExecutorStart、ExecutorRun 和 ExecutorEnd,其输入是包含査询计划树的数据结构QueryDesc,输出则是相关执行信息或结果数据。如果希望执行某个计划树,仅需构造包含此计划树的QueryDesc,并依次调用ExecutorStart、ExecutorRun、ExecutorEnd 3个过程即能完成相应的处理过程。从我之前的文章跟我一起读postgresql源码(六)——Executor(查询执行模块之——查询执行策略)中可以看到,执行器的三个接口函数都是在Portal的相关函数中调用的,分别负责执行器的初始化、执行和清理工作,Portal在处理时也使用了同样的方式,这样可以把资源分配回收工作与执行过程独立开,能够简化执行过程,更是一种很好的资源管理方式。
执行器对于査询计划树的处理,最终被转换为针对计划树上每一个节点的处理。每种节点表示一种物理代数(Physical Algebra)操作,PostgreSQL会依次对其进行初始化、处理和清理。节点的处理被设计为demand-driven模式,父节点使用子节点提供的数据作为输入,并向其上层节点返回处理结果。实际执行时,从根节点开始处理,每个节点的执行过程会根据需求自动调用子节点的执行过程来获取输入数据(一般为元组),从而层层递归执行,实现整个计划树的遍历执行过程。初始化和清理也采用相同的设计模式,这种设计模式使得节点处理的代码结构简洁统一、语义明确,且实现方式简单有效。
接下来将会对执行器部分的各种原理、实现做进一步的介绍。
2.1处理模式
PostgreSQL中的计划节点被定义为有0~2个输入和一个输出,这是为了在实现中能够对应二叉树结构。所以你知道了:所有的计划节点都被组织为二叉树结构。
每一个计划节点对应于树中的一个节点,下层节点的输出作为上层节点输入。数据(元组)从底层节点向上层节点流动,直至根节点,而根节点的输出即为整个査询的结果。
例如有这么一个查询:
select a.q,b.w,c.e from a join b join c order by a.q limit 1;那么计划节点可能如下所示(其实说实话你explain一条查询就能看到各个节点直接的关系):
limit
^
|
sort
^
|
join
^^
/ join scan
^^
/ scan scan在PostgreSQL的实现中,上层函数通过ExecInitNode、ExecProcNode、ExecEndNode二个接口函数来统一对节点进行初始化、执行和清理,这三个函数会根据所处理节点的实际类型调用相应的初始化、执行、清理函数(可见我这这篇文章的末尾)。
由此可见,査询计划树上的节点就构成了物理元组到执行结果的管道,因此査询计划树的执行过程可以看成是拉动元组穿过管道的过程。PostgreSQL采用了一次一元组的执行模式,每个节点被执行一次仅向上层节点返回一条元组。因此,对于整个査询计划树的执行也是一次一元组的模式。这种模式有很多的优点:
减少了返回元组的延迟。
对于某些操作(例如游标、LIMIT子句等)不需要一次性获取所有的元组,节省了开销。
减少了实现过程中缓存结果带来的代码复杂性和执行过程中临时存储的开销。
2.2计划节点的数据结构
从前面的介绍我们已经看到査询计划树是由各种计划节点构成,那么在PostgreSQL中是如何存储和表示各类节点的呢?下图给出了Hash类型节点的数据结构表示。
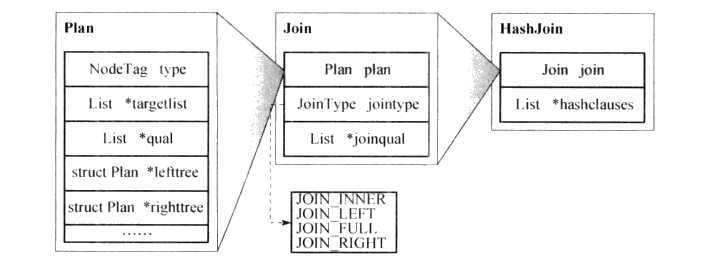
所有计划节点节点的数据结构都以一个Plan类型的字段开头,这有点像类的继承:把Plan看成一个父类,其他计划节点节点都是它的直接或者间接子类。浓浓的面向对象的味道。
如上图所示,Join节点是Plan的子类,从Plan中继承了左右子树指针(lefttree, rightlree)、节点类型(type)、选择表达式(qual)、投影链表(targedisO等公共字段,并有自己的扩展字段连接类型(jointype)和连接条件(joinqual); Hashjoin节点则是Join节点的子类,有自己的扩展字段hashclauses。
PostgreSQL系统中将所有的计划节点按功能分为四类:
控制节点(control node)
扫描节点(scan node)
连接节点(join node)
物化节点(materialization node)并分别为扫描、连接节点类型定义了公共父类Scan、Join。Hash连接属于连接节点,因此Hash连接继承于Join节点。连接节点类型的公共父类定义了连接的类型以及连接的条件。作为Hash连接节点,需要使用Hash函数,所以Hashjoin节点扩展定义了hashclauses字段来存储相关信息,其中包括需要做Hash的属性以及使用的Hash函数等。
Plan的众多子类节点通过lefttree和righttree字段构成了整个査询计划树,其根节点指针被保存在PlannedStmt类型的数据结构中,其中包含了语句的类型(commandType)、査询计划树根节点(planTrce)、査询涉及的范围表(rtable)、结果关系表(resultRelation )PlannedStmt 结构则被放在QueryDesc中,QueryDesc结构的基本定义如下图所示。
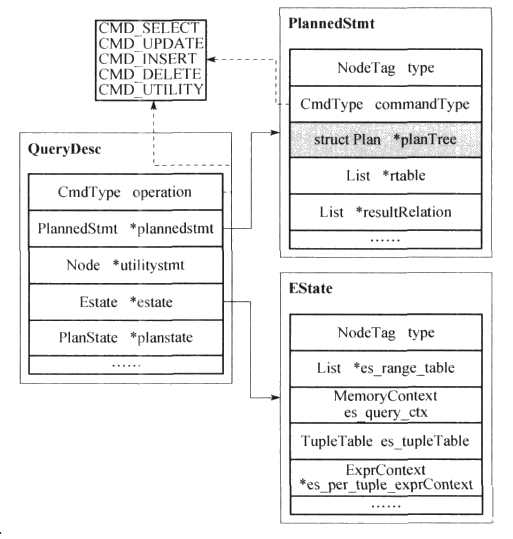
作为执行器的输入,QueryDesc中包含査询计划树(plannedstmt字段)、功能语句相关执行计划(utilitystmt字段)、执行器全局状态(estate字段)以及计划节点执行状态(planstate字段)等。从上图可以看出,执行器全局状态estate中保存了査询涉及的范围表(es_range_table)、Estate所在的内存上下文(es_query_cxt,也是执行过程中一直保持的内存上下文)、用于在节点间传递元组的全局元组表(es_TupleTable)和每获取一个元组就会回收的内存上下文(es_per_tuple_exprContext) 。
执行器初始化时,ExecutorStart会根据査询计划树构造执行器全局状态(estate)以及计划节点执行状态(planstate)。在査询计划树的执行过程中,执行器将使用planstate来记录计划节点执行状态和数据,并使用全局状态记录中的es_tupleTable字段在节点间传递结果元组。执行器的清理函数ExecutorEnd将回收执行器全局状态和计划节点执行状态。
下图给出了PostgreSQL中用于计划节点执行状态记录的数据结构与计划节点之间的对应关系。PostgreSQL为每种计划节点定义了一种状态节点。所有的状态节点均继承于PlanState节点,其中包含辅助计划节点指针(Plan)、执行器全局状态结构指针(state)、投影运算相关信息(targetlist)、选择运算相关条件(qual),以及左右子状态节点指针(lefttree、righttree)。
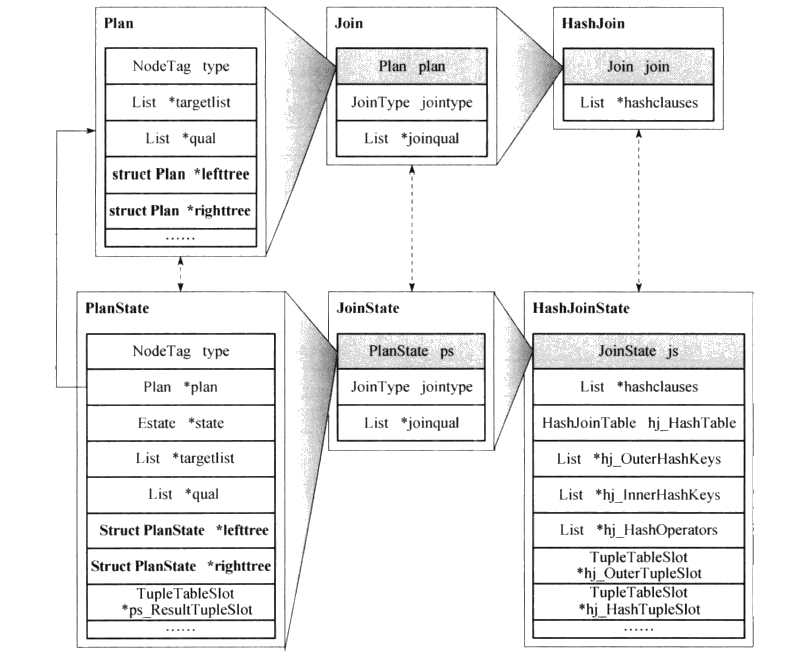
状态节点之间通过lefttree和righttree指针组织成和査询计划树结构类似的状态节点树,同时,每个状态节点都保存了指向其对应的计划节点的指针(PlanState类型中的Plan字段)。下图(计划节点和节点执行状态)中展示了连接节点状态的公共父类JoinStale,它继承于PlanState,扩展了连接类型(jointype)和连接条件(joinqual)属性。而HashJoinState继承于JoinState并扩展了更多的属性,包括Hash函数相关内容(hashclauses、hj_HashTable、hj_OuterHashKeys、hj_InnerHashKeys、hj_HashOperators)、左子节点返回元组指针(hj_OuterTupleSlot)、右子节点返回元组指针(hj_HashTupleSlot)等。
至此,执行器执行过程中涉及的主要各种数据结构已经介绍完毕。执行器的输入是QueryDesc,它包含了存储査询计划树根节点指针的PlannedStmt结构。执行器执行时,首先构造全局状态记录Estate结构,并为每个计划节点(Plan)构造对应的状态节点(PlanState),然后在执行中使用相关结构存储执行状态,执行完毕后释放相关的数据结构。
2.3执行器的运行
在PostgreSQL中提供了三个接口函数用于调用执行器,分别为ExecutorStart、ExecutorRun和ExecutorEnd。当需要使用执行器来处理査询计划时,仅需依次调用三个函数即可完成执行器的整个执
行过程。
执行器运行时的函数调用关系如下图所示,ExecutorStart通过调用standard_ExecutorStart对执行器进行必要的初始化,主要工作包括构造EState结构和査询计划树的初始化(即构造对应的PlanState树,由InitPlan函数完成)。ExecutorRun的功能由standard_ExecutorRun实现,在执行过程中会调用ExecutePlan完成査询计划的执行。ExecutorEnd由standard_ExecutorEnd函数完成,通过调用ExecEndPlan处理执行状态树根节点释放已分配的资源,最后释放执行器全局状态EState完成整个执行过程。
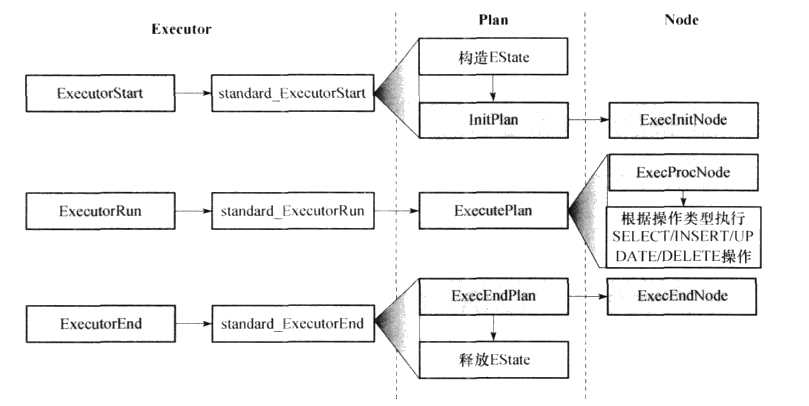
- (1) 初始化査询计划树
执行器中对査询计划树的初始化都是从其根节点开始,并递归地对其子节点进行初始化。计划节点的初始化过程一般都会经历如下图所示的几个基本步骤,该过程在完成计划节点的初始化之后会输出与该计划节点对应的PlanSute结构指针,计划节点的PlanState结构也会按照査询计划树的结构组织成计划节点执行状态树。对计划节点初始化的主要工作是根据计划节点中定义的相关信息,构造对应的PlanStale结构并对相关字段赋值。
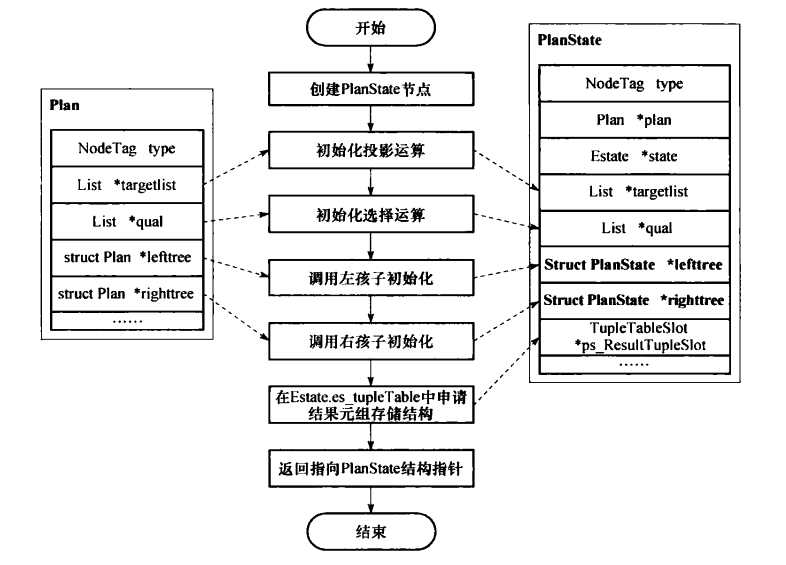
计划节点的初始化由函数ExecInitNode完成,该函数以要初始化的计划节点为输入,并返回该计划节点所对应的PlanState结构指针。在ExecInitNode中,通过判断计划节点的类型来调用相应的处理过程,每一种计划节点都有专门的初始化函数,且都以“ExecInit节点类型”的形式命名。例如,NestLoop节点的初始化函数为ExecInitNestLoop。在计划节点的初始化过程中,如果该节点还有下层的子节点,则会递归地调用子节点的初始化函数来对子节点进行初始化。ExecInitNode函数会根据计划节点的类型(T_NestLoop)调用该类型节点的初始化函数(ExecInitNestLoop)。由于NestLoop节点有两个子节点,因此ExecInitNestLoop会先调用ExecInitNode对其左子节点进行初始化,并将其返回的PlanState结构指针存放在为NestLoop构造的NestLoopState结构的lefttree字段中;然后以同样的方式初始化右子节点,将返回的PlanState结构指针存放于NestLoopState的righttree字段中。同样,如果左右子节点还有下层节点,初始化过程将以完全相同的方式递归下去,直到到达査询计划树的叶子节点。而在初始化过程中构造的树也会层层返回给上层节点,并被链接在上层节点的PlanState结构中,最终构造出完整的PlanState树。
- (2) 查询计划执行
査询计划的实际执行由函数ExecutePlan完成,该函数的主体部分是一个大的循环,每一次循环都通过ExecProcNode函数从计划节点状态树中获取一个元组,然后对该元组进行相应的处理(增删查改),然后返回处理的结果。当ExecProcNode从计划节点状态树中再也取不到有效的元组时结束循环过程。
ExecProoNode的执行过程也和ExecInitNode类似:从计划节点状态树的根节点获取数据,上层节点为了能够完成自己的处理将会递归调用ExecProcNode从下层节点获取输入数据(一般为元组),然后根据输入数据进行上层节点对应的处理,最后进行选择条件的运算和投影运算,并向更上层的节点返回结果元组的指针。同ExecInitNode 一样,ExecProcNode 也是一个选择函数,它会根据要处理的节点的类型调用对应的处理函数。例如,对于NestLoop类型的节点,其处理函数为ExecNestLoop。ExecNestLoop函数同样会对NestLoop类型的两个子节点调用ExecProcNode以获取输入数据。如果其子节点还有下层节点,则以同样的方式递归调用ExecProcNode进行处理,直到到达叶子节点。每一个节点被ExecProcNode处理之后都会返回一个结果元组,这些结果元组作为上层节点的输入被处理形成上层节点的结果元组,最终根节点将返回结果元组。
每当通过ExecProcNode从计划节点状态树中获得一个结果元组后,ExecutePlan函数将根据整个语句的操作类型调用相应的函数进行最后的处理。对于不扫描表的简单查询(例如select 1),调用的是Result节点,通过ExecResult函数直接输出“査询”结果。对于需要扫描表的查询(例如select xx from tablexx这种),系统在扫描完节点后直接返回结果,而对于增删改查询,情况特殊,有一个专门的ModifyTable节点来处理它:主要调用了ExecInsert、ExecDelete、ExecUpdate这三个函数进行处理。对于插入语句,则首先需要调用ExecConstraints对即将插入的元组进行约束检査,如果满足要求,ExecInsert会调用函数heap_insert将元组存储到存储系统。对于删除和更新,则分别由 ExecDelete 和 ExecUpdate 调用 heap_delete 和 heap_update 完成。
对于其他的特殊情况,也有特殊的节点去处理,这在Postgresql里面称为控制节点。读者们可以查看ExecProcNode函数获取详情。(这部分代码9.5.4和8.x版本差异较大)
- (3)执行器清理
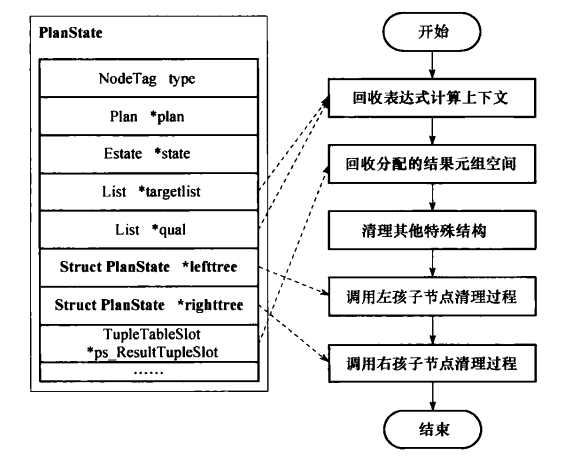
当执行器处理完所有能够获得的元组之后,由执行器清理函数ExecutorEnd负责善后工作。该函数调用ExecEndPlan对计划节点执行状态树进行清理。对计划节点执行状态树的清理和执行状态树的初始化、执行相类似:从根节点开始递归调用ExecEndNode对每一个计划节点的执行状态节点进行清理。同样,ExecEndNode只是一个选择函数,针对不同类型的节点有相应的淸理函数。例如,NestLoop节点的清理函数是ExecEndNestLoop。如下图所示,清理过程的任务主要是回收初始化过程中分配的资源、投影和选择结构的内存、结果元组存储空间等,计划节点执行状态树清理完之后,ExecutorEnd还将调用FreeExecutorState清理执行器全局状态。
注:本文中的图文大量参考了彭煜玮老师《Postgresql数据库内核分析》一书,在此鸣谢。
后面开始讲讲查询执行所涉及到的各种计划节点吧。