标签:三层 alt 必须 ash 海量数据 节点配置 rdbms bin processor
Flume是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中。轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均衡。并且它拥有非常丰富的组件。Flume采用的是三层架构:Agent层,Collector层和Store层,每一层均可水平拓展。其中Agent包含Source,Channel和 Sink,三者组建了一个Agent。三者的职责如下所示: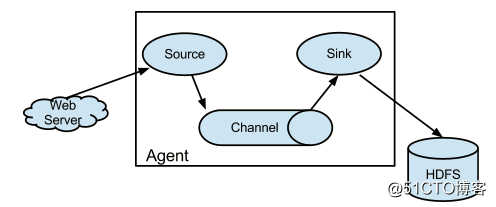
1.1 下载安装
[hadoop@hdp01 ~]$ http://mirrors.hust.edu.cn/apache/flume/stable/apache-flume-1.8.0-bin.tar.gz
[hadoop@hdp01 ~]$ tar -xzf apache-flume-1.8.0-bin.tar.gz;mv apache-flume-1.8.0-bin /u01/flume1.2 设置环境变量
[hadoop@hdp01 ~]$ vi .bash_profile
export FLUME_HOME=/u01/flume
export PATH=$PATH:$FLUME_HOME/bin1.3 创建Flume配置文件
[hadoop@hdp01 ~]$ vi /u01/flume/conf/flume-hdfs.conf
#Agent Name
a1.sources = so1
a1.sinks = si1
a1.channels = ch1
#Setting Source so1
a1.sources.so1.type = spooldir
a1.sources.so1.spoolDir = /u01/flume/loghdfs
a1.sources.so1.channels = ch1
a1.sources.so1.fileHeader = false
a1.sources.so1.interceptors = i1
a1.sources.so1.interceptors.i1.type = timestamp
a1.sources.so1.ignorePattern = ^(.)*\\.tmp$
#Setting Sink With HDFS
a1.sinks.si1.channel = ch1
a1.sinks.si1.type = hdfs
a1.sinks.si1.hdfs.path = hdfs://NNcluster/flume/input
a1.sinks.si1.hdfs.fileType = DataStream
a1.sinks.si1.hdfs.writeFormat = Text
a1.sinks.si1.hdfs.rollInternal = 1
a1.sinks.si1.hdfs.filePrefix = %Y-%m-%d
a1.sinks.si1.hdfs.fileSuffix= .txt
#Binding Source and Sink to Channel
a1.channels.ch1.type = file
a1.channels.ch1.checkpointDir = /u01/flume/loghdfs/point
a1.channels.ch1.dataDirs = /u01/flume/loghdfs
[hadoop@hdp01 ~]$ cp /u01/flume/conf/flume-env.sh.template /u01/flume/conf/flume-env.sh
[hadoop@hdp01 ~]$ vi /u01/flume/conf/flume-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_152
--创建相关目录
[hadoop@hdp01 ~]$ mkdir -p /u01/flume/loghdfs/point
--链接hadoop配置文件?/u01/flume/conf
现有的Hadoop环境配置了NameNode高可用,必须链接相关配置,否则flume不知道往哪存数据。
[hadoop@hdp01 ~]$ ln -s /u01/hadoop/etc/hadoop/core-site.xml /u01/flume/conf/core-site.xml
[hadoop@hdp01 ~]$ ln -s /u01/hadoop/etc/hadoop/hdfs-site.xml /u01/flume/conf/hdfs-site.xml到此,单节点模式就配置完成。
1.4 启动flume服务
[hadoop@hdp01 ~]$ flume-ng agent --conf conf --conf-file /u01/flume/conf/flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,console > /u01/flume/logs/flume-hdfs.log 2>&1 &注意:命令中的a1表示配置文件中的Agent的Name;而flume的配置文件必须使用绝对路径。
1.5 效果测试
在/u01/flume/loghdfs下面,随便创建一个文件,并写入数据,结果如下图:
Flume集群模式的架构图(官方图)如下图所示: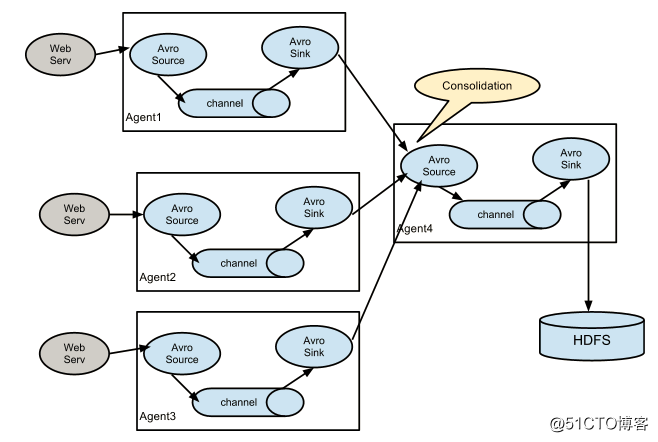
图中,Flume的存储可以支持多种,这里只列举了HDFS和Kafka(如:存储最新的一周日志,并给Storm系统提供实时日志流)。这里以Oracle的alert日志为例。环境如下表所示: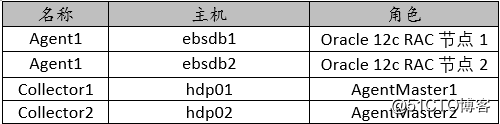
表中的RAC两个节点的alert日志通过Collector1和Collector2存入HDFS。另外Flume本身提供了Failover机制,可以自动切换和恢复。
2.1 RAC节点安装Flume
[Oracle@ebsdb1 ~]$ http://mirrors.hust.edu.cn/apache/flume/stable/apache-flume-1.8.0-bin.tar.gz
[Oracle@ebsdb1 ~]$ tar -xzf apache-flume-1.8.0-bin.tar.gz;mv apache-flume-1.8.0-bin /u01/app/oracle/flumeRAC的其他节点也类似安装
2.2 配置RAC节点的Agent
2.2.1 配置ebsdb1的agent
[oracle@ebsdb1 ~]$ vi /u01/flume/conf/flume-client.properties
#agent name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
#set gruop
agent1.sinkgroups = g1
#Setting Channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 100000
agent1.channels.c1.transactionCapacity = 100
#Just For Fllowing Error Messgaes
#Space for commit to queue couldn‘t be acquired. Sinks are likely not keeping up with sources, or the buffer size is too tight
agent1.channels.c1.byteCapacityBufferPercentage=20
agent1.channels.c1.byteCapacity=800000
agent1.channels.c1.keep-alive = 60
#Setting Sources
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /u01/app/oracle/diag/rdbms/prod/prod1/trace/alert_prod1.log
agent1.sources.r1.interceptors = i1 i2
agent1.sources.r1.interceptors.i1.type = static
agent1.sources.r1.interceptors.i1.key = Type
agent1.sources.r1.interceptors.i1.value = LOGIN
agent1.sources.r1.interceptors.i2.type = timestamp
# Setting Sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = hdp01
agent1.sinks.k1.port = 52020
# Setting Sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = hdp02
agent1.sinks.k2.port = 52020
#Seting Sink Group
agent1.sinkgroups.g1.sinks = k1 k2
#Setting Failover
agent1.sinkgroups.g1.processor.type = failover
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 1
agent1.sinkgroups.g1.processor.maxpenalty = 100002.2.2 配置ebsdb2的agent
[oracle@ebsdb2 ~]$ vi /u01/flume/conf/flume-client.properties
#Setting Agent Name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
#Setting Gruop
agent1.sinkgroups = g1
#Setting Channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 100000
agent1.channels.c1.transactionCapacity = 100
#Just For Fllowing Error Messgaes
#Space for commit to queue couldn‘t be acquired. Sinks are likely not keeping up with sources, or the buffer size is too tight#
agent1.channels.c1.byteCapacityBufferPercentage=20
agent1.channels.c1.byteCapacity=800000
agent1.channels.c1.keep-alive = 60
#Seting Sources
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /u01/app/oracle/diag/rdbms/prod/prod2/trace/alert_prod2.log
agent1.sources.r1.interceptors = i1 i2
agent1.sources.r1.interceptors.i1.type = static
agent1.sources.r1.interceptors.i1.key = Type
agent1.sources.r1.interceptors.i1.value = LOGIN
agent1.sources.r1.interceptors.i2.type = timestamp
#Settinf Sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = hdp01
agent1.sinks.k1.port = 52020
# Setting Sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = hdp02
agent1.sinks.k2.port = 52020
#Setting Sink Group
agent1.sinkgroups.g1.sinks = k1 k2
#Set Failover
agent1.sinkgroups.g1.processor.type = failover
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 1
agent1.sinkgroups.g1.processor.maxpenalty = 100002.3 配置Flume的Collector
2.3.1 hdp01的collector配置
[hadoop@hdp01 conf]$ vi flume-server.properties
#Setting Agent Name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#Setting Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#Setting Sources
a1.sources.r1.type = avro
a1.sources.r1.bind = hdp01
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hdp01
a1.sources.r1.channels = c1
#Setting Sink To HDFS
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://NNcluster/flume/Oracle/logs
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
a1.sinks.k1.hdfs.rollInterval=1
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
a1.sinks.k1.hdfs.fileSuffix=.txt2.3.2 hdp02的collector配置
[hadoop@hdp02 conf]$ vi flume-server.properties
#Setting Agent Name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#Setting Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Seting Sources
a1.sources.r1.type = avro
a1.sources.r1.bind = hdp02
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hdp02
a1.sources.r1.channels = c1
#Setting Sink To HDFS
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://NNcluster/flume/Oracle/logs
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
a1.sinks.k1.hdfs.rollInterval=1
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
a1.sinks.k1.hdfs.fileSuffix=.txt2.4 Flume集群服务启动
2.4.1 启动Flume的Collector
[hadoop@hdp01 conf]$ flume-ng agent --conf conf --conf-file /u01/flume/conf/flume-server.properties --name a1 -Dflume.root.logger=INFO,console > /u01/flume/logs/flume-server.log 2>&1 &
[hadoop@hdp02 conf]$ flume-ng agent --conf conf --conf-file /u01/flume/conf/flume-server.properties --name a1 -Dflume.root.logger=INFO,console > /u01/flume/logs/flume-server.log 2>&1 &启动后,可查看flume的日志文件,内容如下图:
2.4.2 启动Flume的Agent
[oracle@ebsdb1 bin]$ ./flume-ng agent --conf conf --conf-file /u01/app/oracle/flume/conf/flume-client.properties --name agent1 -Dflume.root.logger=INFO,console > /u01/app/oracle/flume/logs/flume-client.log 2>&1 &
[oracle@ebsdb2 bin]$ ./flume-ng agent --conf conf --conf-file /u01/app/oracle/flume/conf/flume-client.properties --name agent1 -Dflume.root.logger=INFO,console > /u01/app/oracle/flume/logs/flume-client.log 2>&1 & 待agent启动完毕后,观察collecter日志,就会发现agent已成功连接到collector,如下图:
2.5 Flume高可用测试
由于collector1配置的权重大于collector2,所以 Collector1优先采集并上传到存储系统。这里假如kill掉collector1,由Collector2负责日志的采集上传工作,看是否上传成功。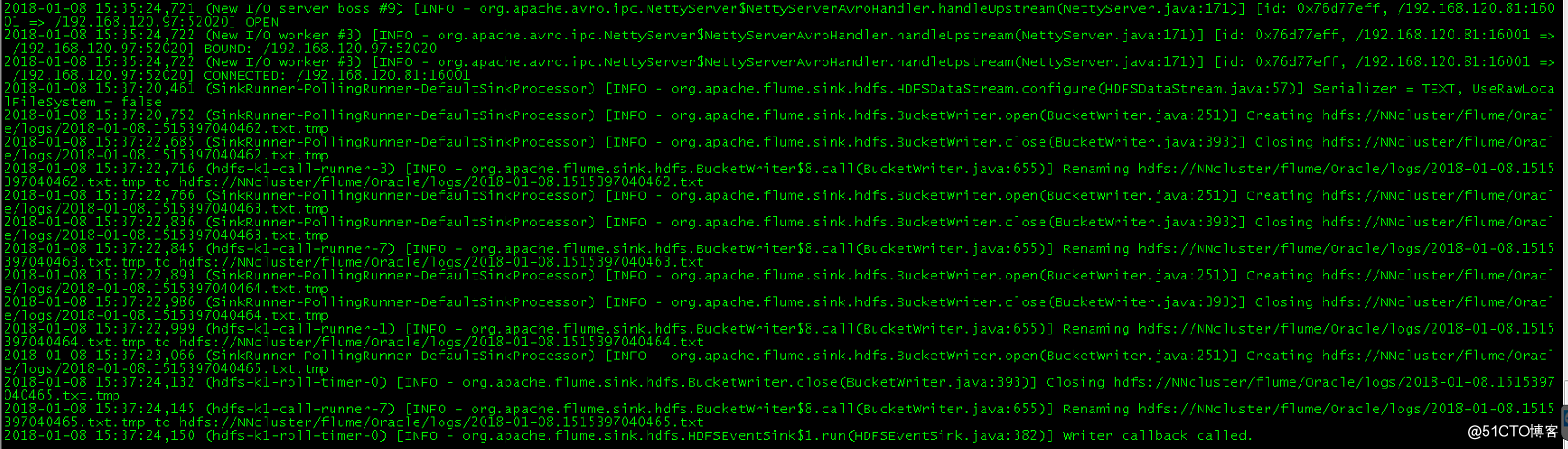
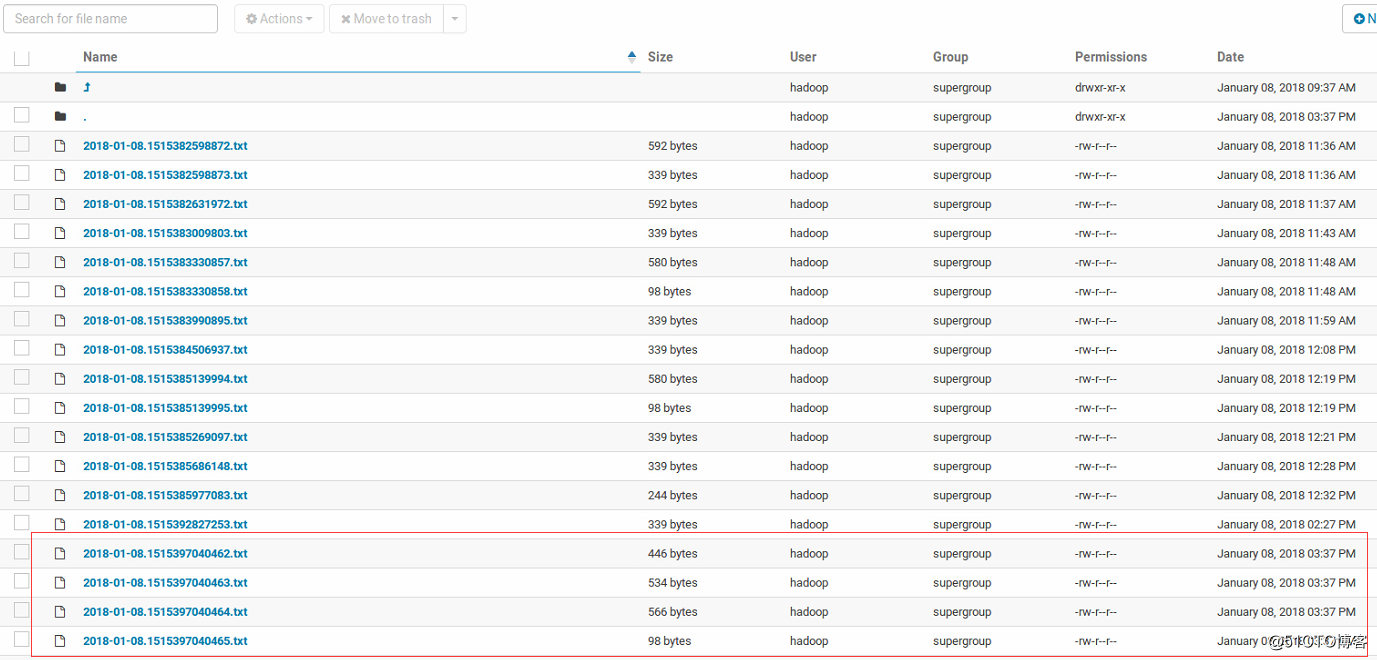
接着恢复Collector1节点的Flume服务,再次在Agent1上传文件,发现Collector1恢复优先级别的采集工作。
参考文献:
1、Flume 1.8.0 User Guide
Setting Up Flume High Availability
标签:三层 alt 必须 ash 海量数据 节点配置 rdbms bin processor
原文地址:http://blog.51cto.com/candon123/2058635