网上教程太啰嗦,本人最讨厌一大堆没用的废话,直接上,就是干!
网络爬虫?非监督学习?
只有两步,只有两个步骤?
Are you kidding me?
Are you ok?
来吧,follow me, come on!
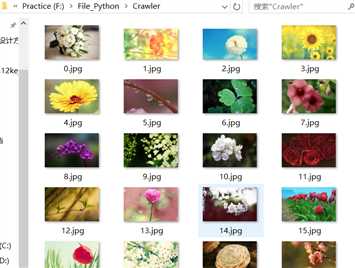
第一步:首先,我们从网上获取图片自动下载到自己电脑的文件内,如从网址,下载到F:\File_Python\Crawler文件夹内,具体代码请查看http://www.cnblogs.com/yunyaniu/p/8244490.html
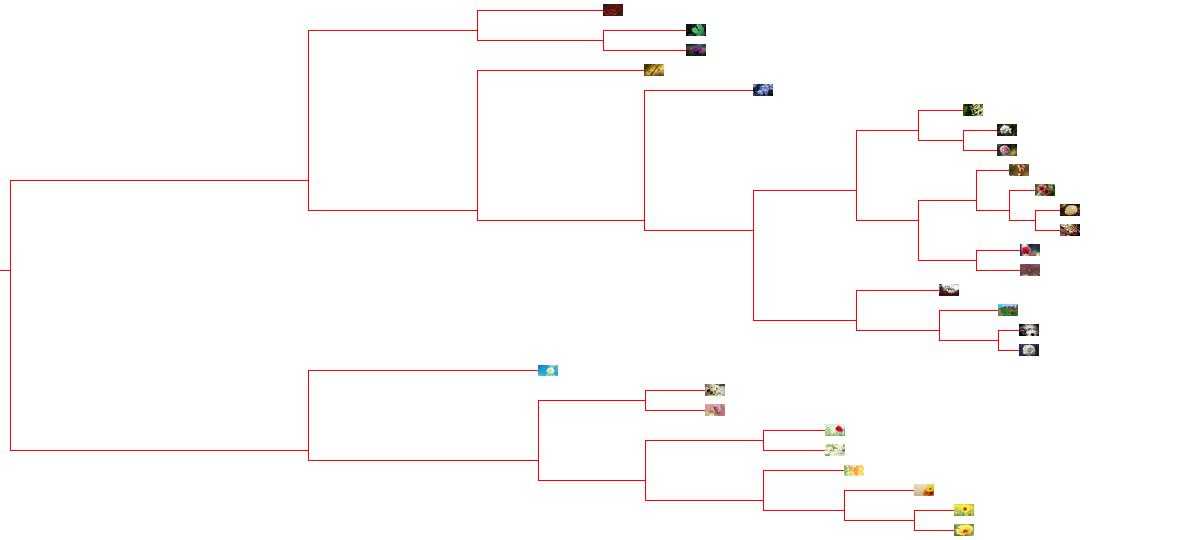
第二步:我们利用非监督学习的Hierarchical clustering层次聚类算法将图片按照色调进行自动分类,具体代码请查看http://www.cnblogs.com/yunyaniu/p/8244533.html