标签:dad 选项卡 跳线 集中 数据库服务 ef6 域账户 故障转移 页面
我们前面写了很多关于SQL Server相关的文章,近期公司为了提高服务的可用性,就想到了部署AlwaysOn,之前的环境只是部署了SQL Server Failover Cluster,所以决定将云端放一台SQL Server来配置ALwaysOn,具体思路就是在本地的SQL Server Failover Cluster中再增加一个节点,然后将新家的节点放到Azure云端,然后在这两个实例之间配置AlwaysOn,部署后,有个问题就是集群之间无法自动故障转移,需要手动干预才可以具体后期我们再做详细介绍,废话就不多说了,开始实践配置;Hostname:DC1
Role:DC
IP:192.168.5.20
Domain:ixmsoft.com
Hostname:ISCSI
IP:192.168.5.38
Role:Storage
Hostname:S1
Role:SQL Server 2016
IP:192.168.5.41
Hostname:S2
Role:SQL Server 2016
IP:192.168.5.42
Hostname:AO1
Role:SQL Server 2016
IP:192.168.5.43
SQL-CLUSTER
192.168.5.46
SQLCLUSTER
192.168.5.47
HA-LP1
ListenIP:192.168.5.48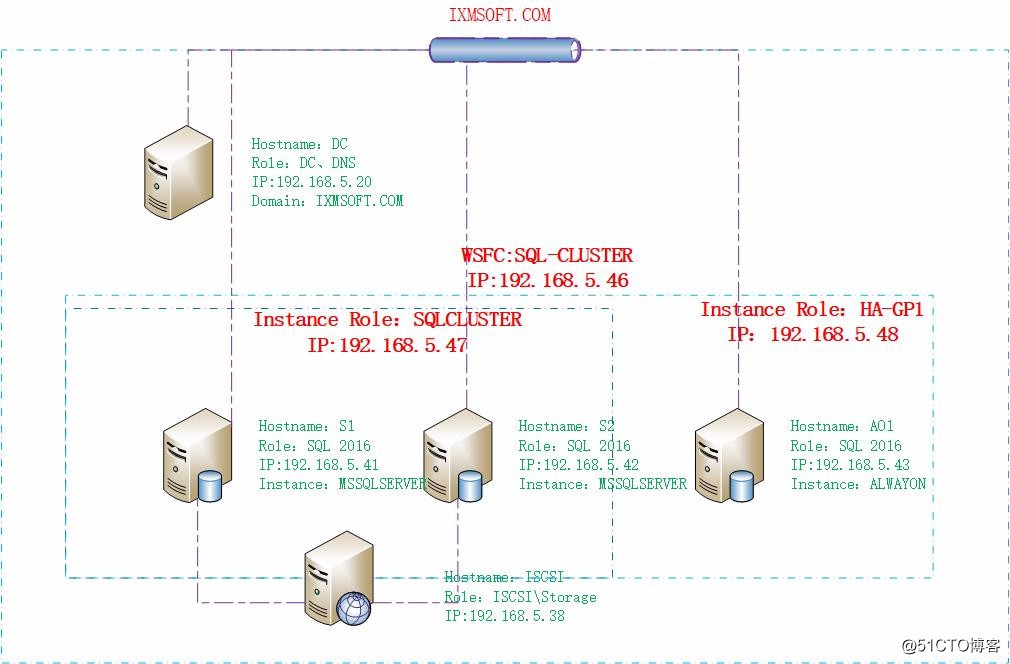
因为要做磁盘共享,所以我们使用系统自带的ISCSI做为连接器;
我们首先安装配置ISCSI服务器:
首先是挂载两块盘:一块是Data:50G,一块是仲裁:10G
然后安装ISCSI目标服务器
我们安装后,我们打开ISCSI管理---创建ISCSI虚拟磁盘
我们新选择DATA盘
我们增加需要分配磁盘的计算机IP
我们增加两台SQL Server服务器
确认信息
创建完成

再次新建一个虚拟磁盘用于仲裁
设置磁盘名称
所有的磁盘已增加完成
我们开始从5.41上通过ISCSI连接程序连接共享磁盘
提示确认启动服务
输入ISCSI服务器地址,快速链接
已连接
卷和设备已加载
我们此时就可以在192.168.5.41上看见分配的两块磁盘了
我们同理也按照上面的方法,在192.168.5.42上进行ISCSI链接
准备好以上操作后,我们就可以开始安装故障转移集群了;
我们首先在S1上进行操作安装
安装完成
安装后,我们同样在第二台S2上进行安装,安装后,我们就打开集群管理器
右击故障转移集群管理器----验证配置
增加两台SQL Server服务器
验证通过后,点击完成
验证通过后,我们就可以创建了;
我们定义集群名称及IP
SQL-CLUSTER
192.168.5.46
定以后,确认信息
开始创建集群
定义完成
两个节点信息
磁盘信息
配置仲裁
高级仲裁选项
选择所有节点
选择仲裁磁盘
我们同时将第一个磁盘增加到群集共享卷
我们准备安装SQL Server 2016
定义SQL Server网络名称
SQLCLUSTER
选择数据磁盘
定义群集网络IP
192.168.5.47
定义账户信息
定义数据目录,自动选择磁盘共享卷目录
安装完成
我们在群集管理器中就可以看见多了一个角色及管理IP
我们准备安装第二个节点
下一步即可
默认即可
确认信息

节点增加完成
测试集群
我们从节点1切换到节点2
切换中
切换完成
我们使用SSMS进行连接测试
我们使用SQL集群地址进行连接
我们使用群集网络地址链接
我们查看集群属性----集群化--true
接着我们配置 ALwaysOn,我们准备了一台SQL服务器
但是也需要加入到集群节点;
我们现在在群集节点上增加节点,将第三台SQL加入该节点
输入新节点的名称
验证通过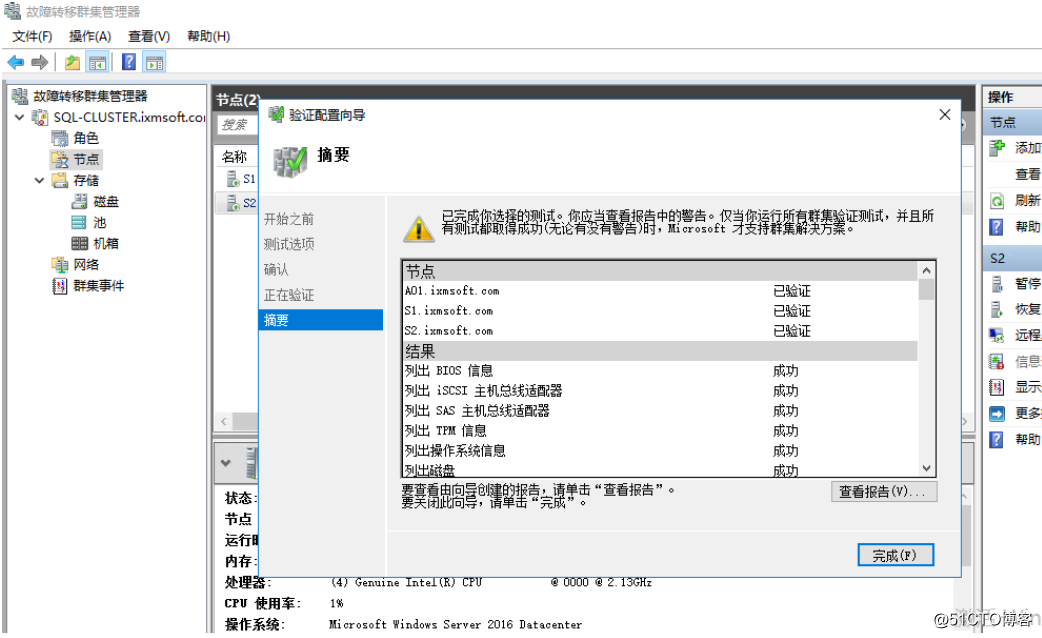
测试通过后,直接增加节点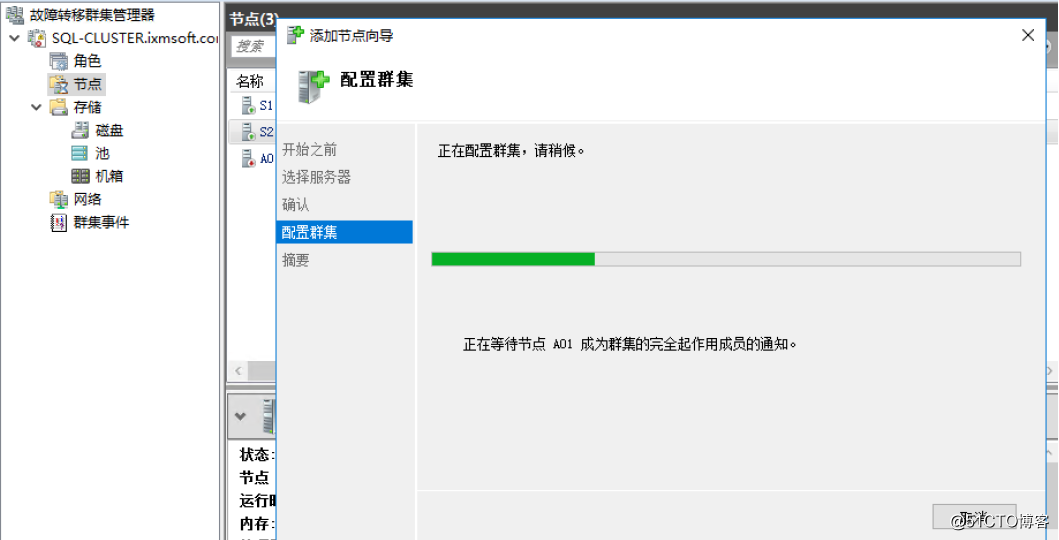
节点增加完成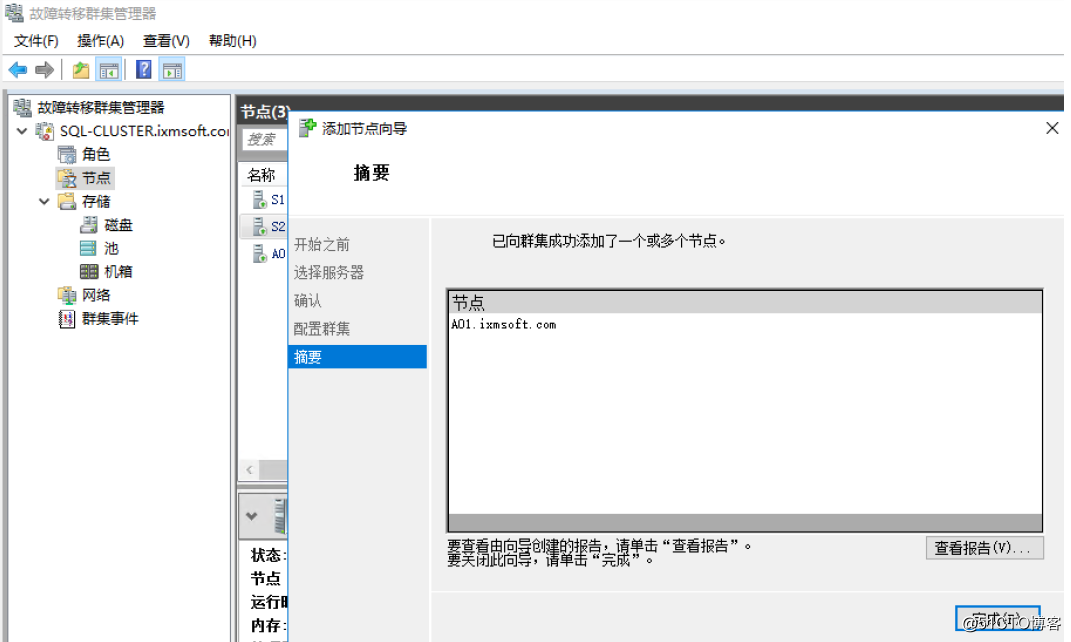
我们再次查看节点信息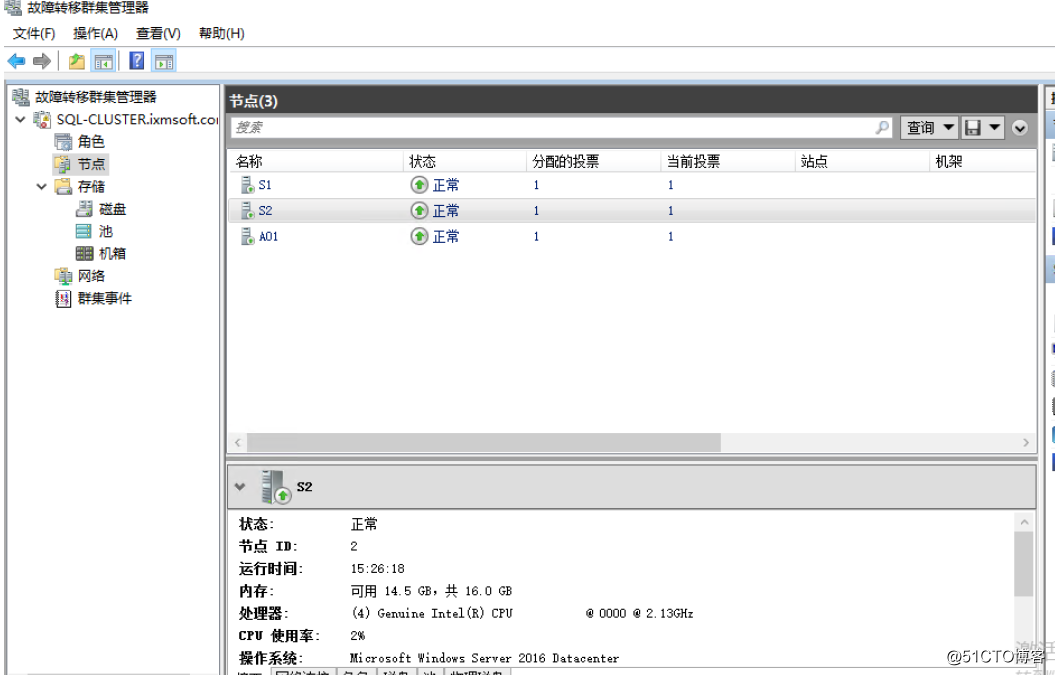
我们接着安装独立SQL实例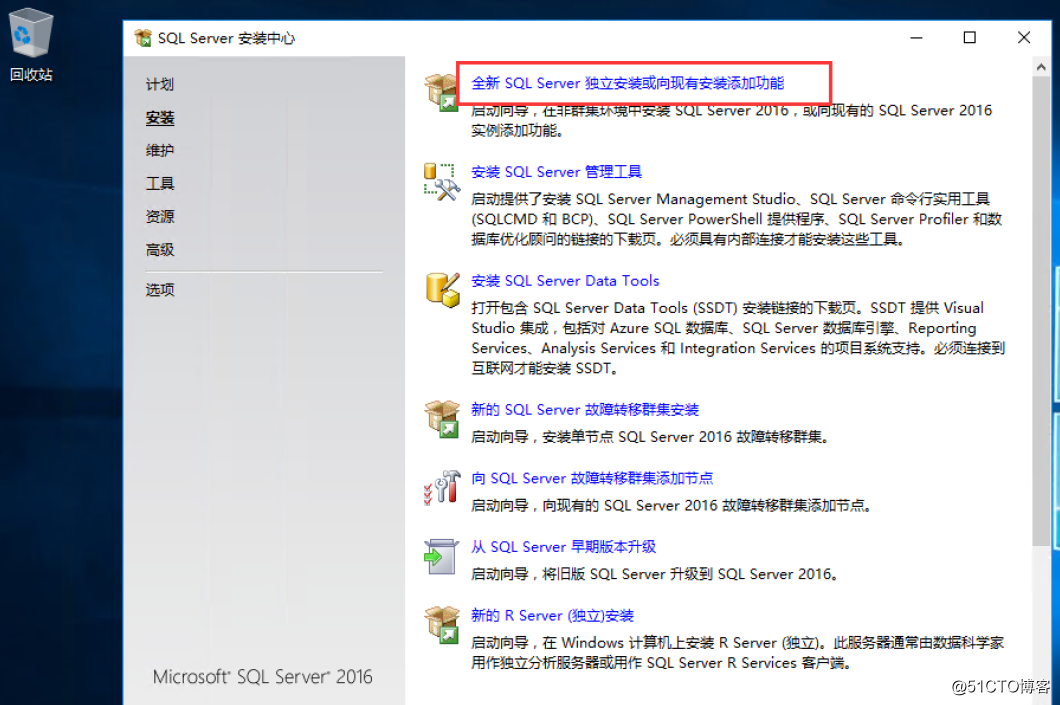
我们安装功能角色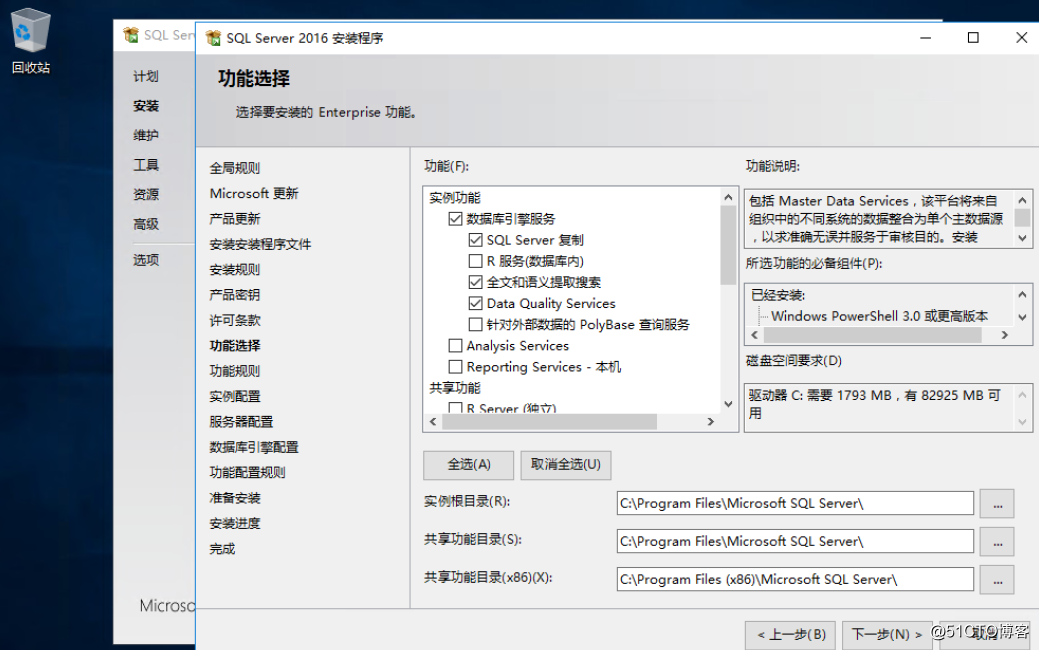
必须要命名一个实例,因为已经在集群中创建了一个默认实例;如果你已在群集中装了一个SQL群集实例,则再在群集中的节点上安装SQL实例时(无论单机
还是群集的),不能再使用这个实例名称。也就是说你已经在群集节点1、2上装了群集的SQL
默认实例的话,则在节点3上也不能再安装单机的SQL默认实例。这种情况下可以选择在节点
上3安装一个SQL命名实例,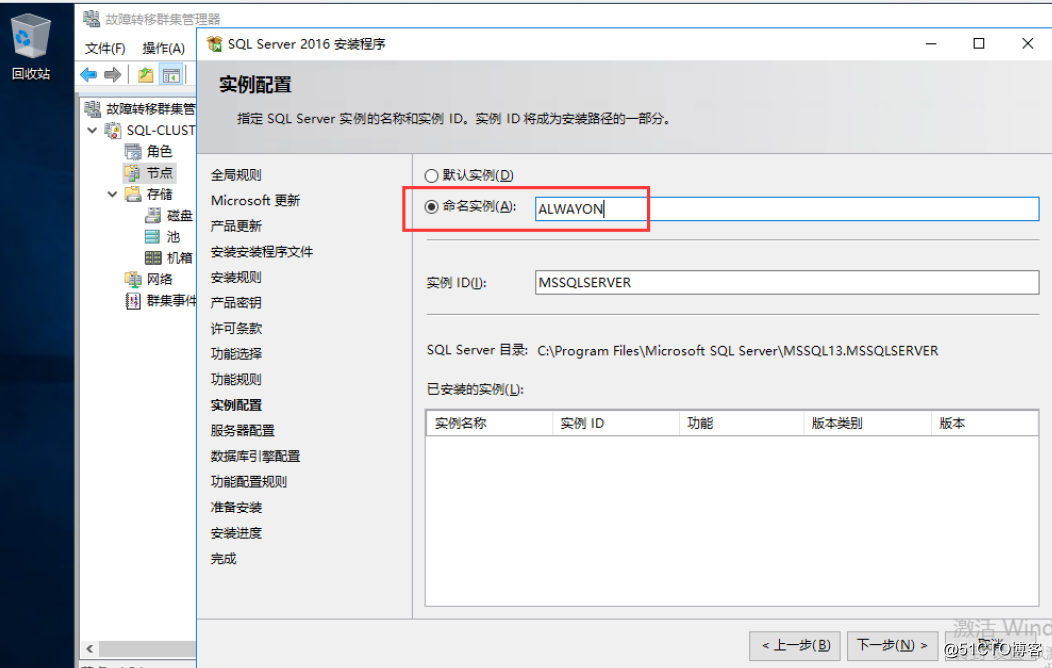
定义账户信息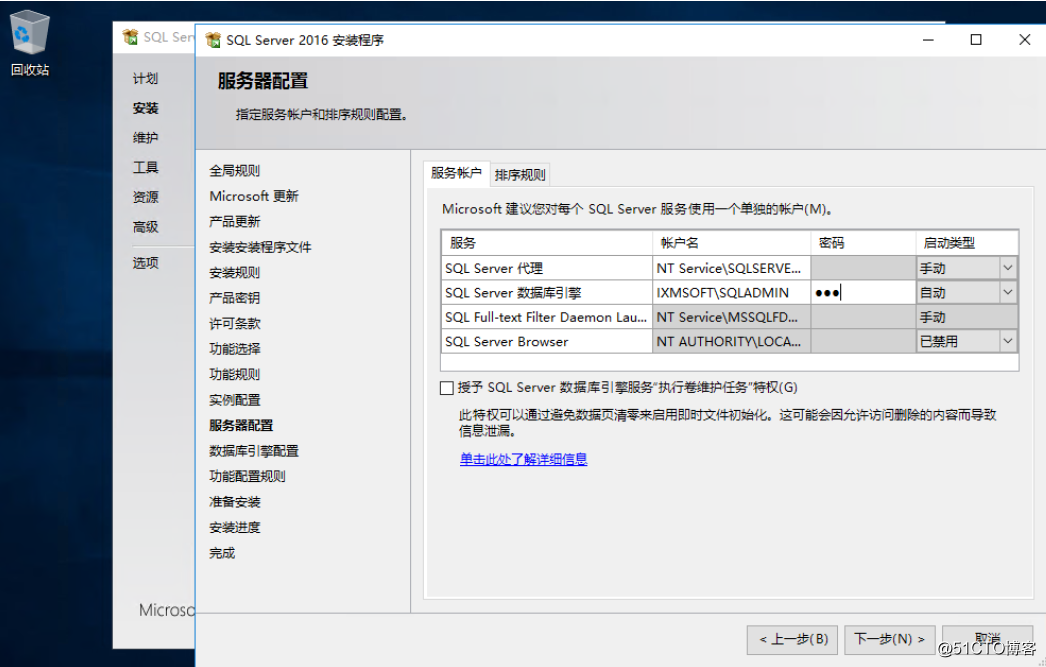
服务器配置信息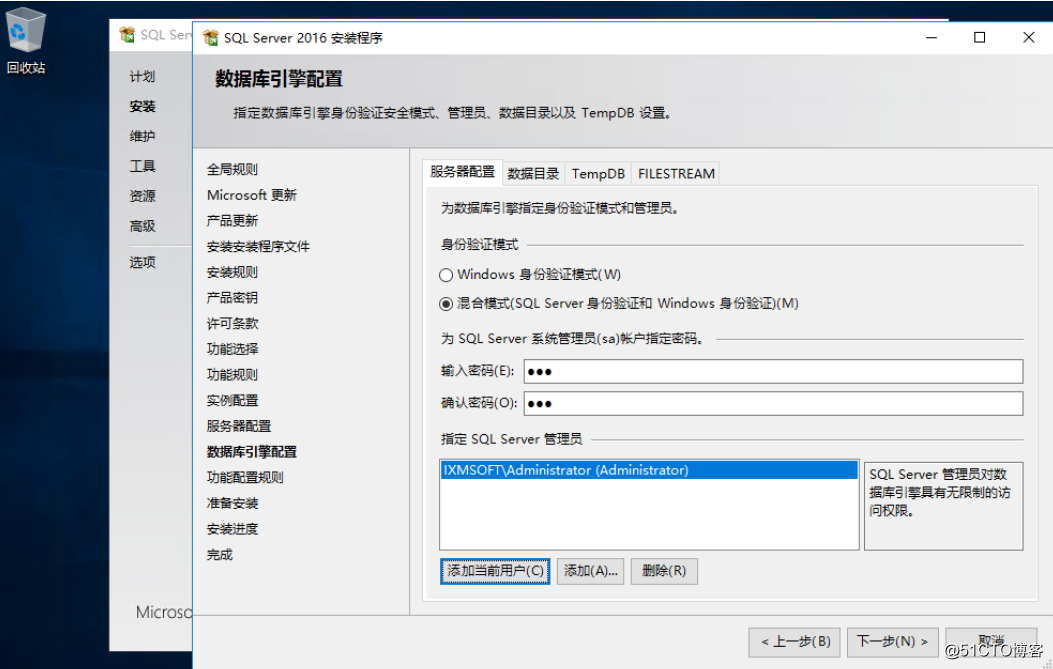
数据目录我们定义到本地即可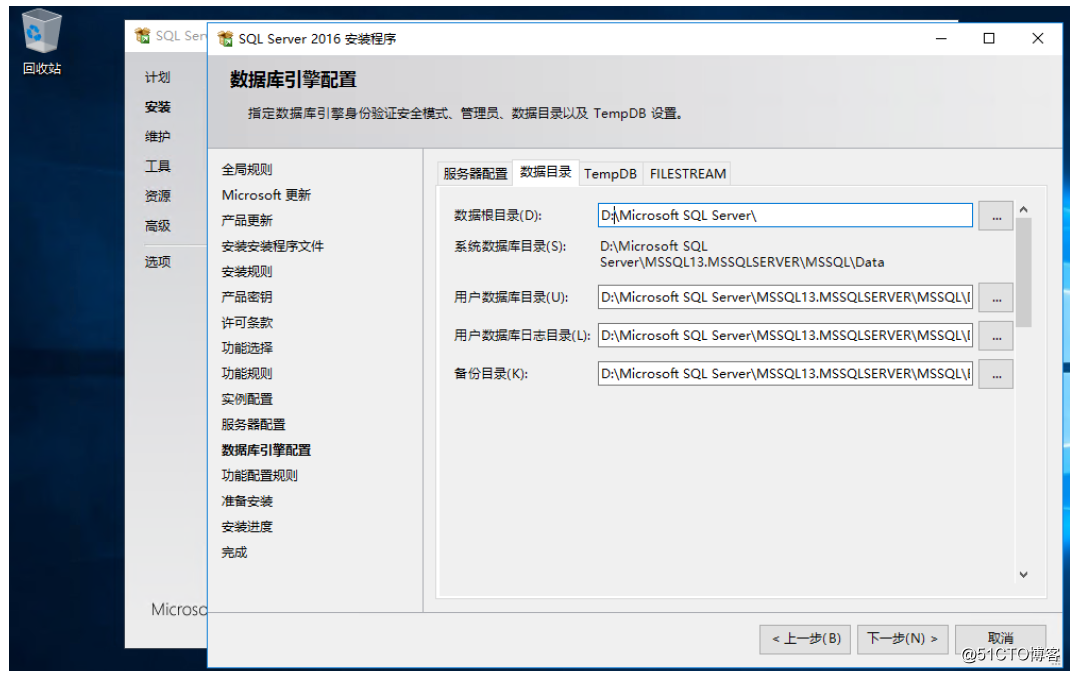
安装完成
节点三安装完后,我们发现服务没有端口,默认额SQL 端口是1433,所以我们修改默认端口---SQL Server配置管理中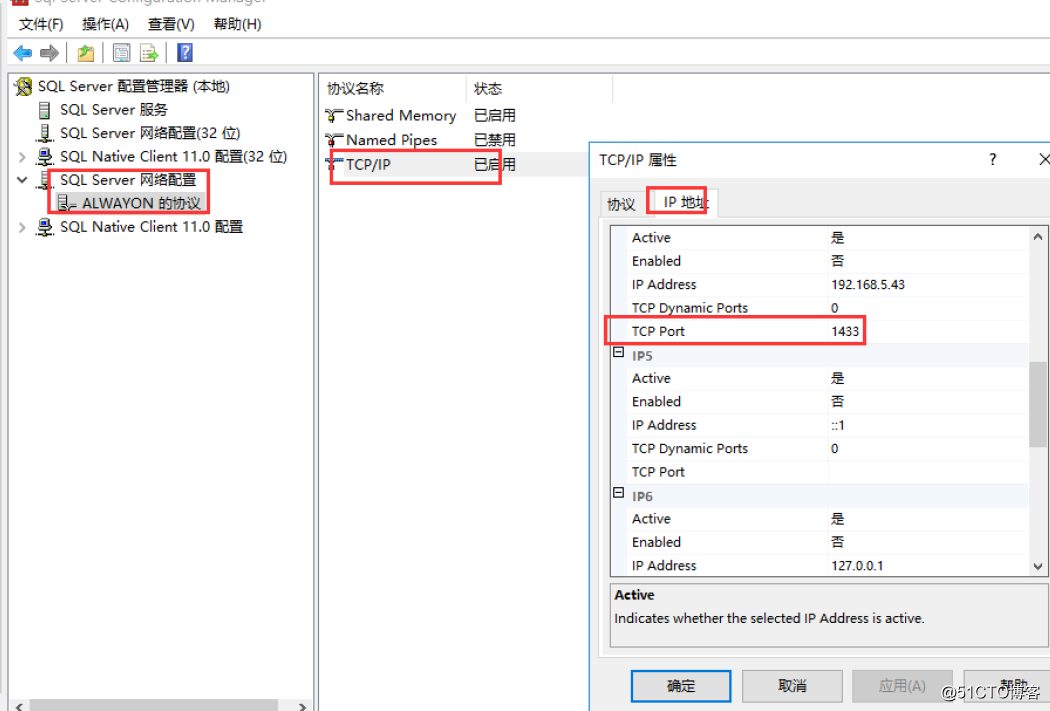
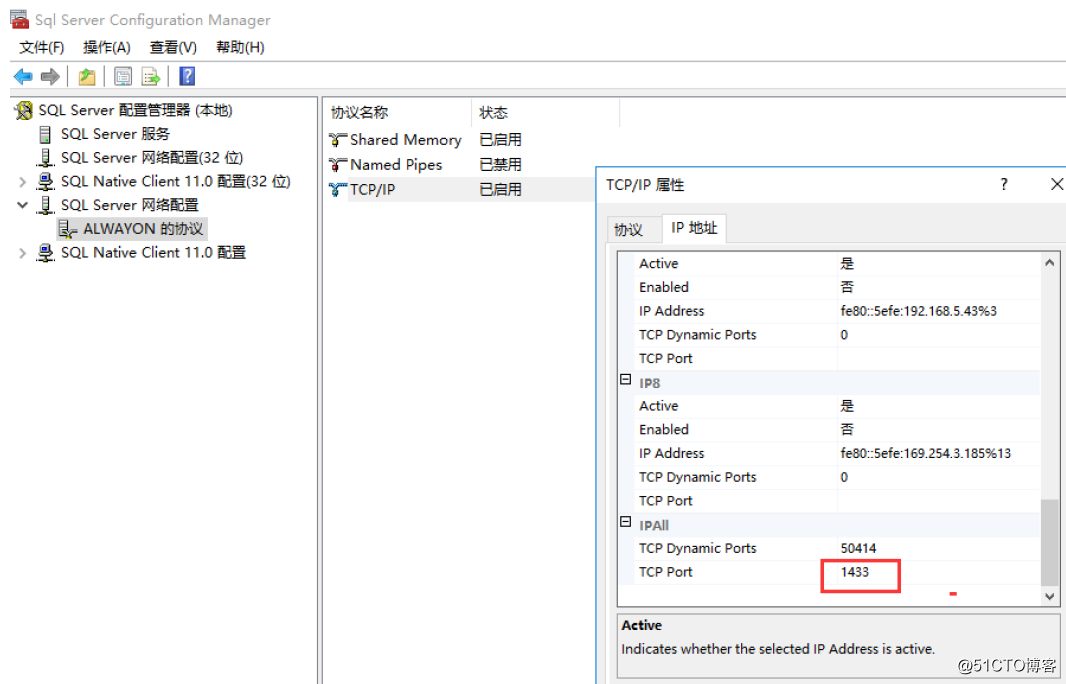
然后在它和之前的SQL群集实例之间创建AlwaysOn可用性组关系。另外AlwaysOn功能的开启是在实例级设置的,这里你一共有2个SQL实例,所以就需要对这2
个SQL实例分别进行设置。对于SQL群集实例,在其任一所有者节点上使用SQL Server
configuration manager设置一次就可以了(重启SQL服务后生效)。
我们通过SSMS右击--AlwayOn High Avaliablity 会有一个提示,意思是必须为服务器实例启用AlwaysOn功能,之后才能在此实例上创建可用性组,若要启用AlowaysOn,请打开SQL Server配置管理器,右键单击SQL Server实例名称,选择属性,然后使用SQL Server属性对话框的AlwaysOn高可用性选项卡,我们链接集群地址,点击ALways High Availability,提示我们开启的方法了
注意:我们使用SSMS连接到SQL Server后,在服务器属性对话框中,单击一般页面。 的HADR启用属性
显示下列值之一:真正的如果启用了总是在可用性组织;假,如果总是在可用性组是禁用的。
所以我们要开启功能
SQL Server服务---属性--右击
我们将SQL Server服务的登录账户换成域账户
我们勾选启用AlwayOn可用性组
应用--确认后,需要重启数据库服务
正在重启服务
第二台服务器的AlwaysOn当节点切换到节点2的时候,发先是自动勾选的;所以不用勾选;另外当角色不在操作的节点的时候,我们就会发现LWAYSON高可用无法操作;属于正常现
象;我们可以通过系统提示的信息就会知道
我们再次查看角色的状态:以下状态属于正常现象,原因是由于启用了ALwaysOn高可用
这种情况下可以选择在节点上3安装一个SQL命名实例,然后在它和之前的SQL群集实例之间创建AlwaysOn可用性组关系。
另外AlwaysOn功能的开启是在实例级设置的,这里你一共有2个SQL实例,所以就需要对这2个SQL实例分别进行设置。对于SQL群集实例,在其任一所有者节点上使用SQL Server
configuration manager设置一次就可以了(重启SQL服务后生效)。
我们同样先将节点三的ALwaysOn高可用性功能打开
我们用SSMS链接实例
我们都知道高可用性是基于DB的,所以我们需要创建数据库:HAGourpDB1
同时创建一张表,perinfo
我们插入数据
我们开始在集群实例下创建高可用性组
勾选数据库层运行状态检测,定义高可用性组的名称:HA-GP1
提示需要首先完整备份
所以我们先备份一下
完整备份及备份类型
备份完成
我们同样备份Log
我们需要将备份的数据库和log在三节点还原一次
恢复状态:RESTORE WITH NORECOVERY
恢复完成
数据库状态未还原模式
恢复事务log
同样选择恢复状态
恢复完成
我们继续创建高可用性组,满足条件继续下一步
我们增加副本
无论是主副本或者辅助副本都选择同步提交模式,辅助副本的Readable Secondary选择为Yes。只是为了后面的只读辅助数据库准备。
AlwaysOn和镜像一样都采用Endpoint(端点)来进行数据传输。AlwaysOn使用端点是为了和辅助副本进行日志传输和心跳线的通信
备份优先级勾选Prefer Secondary。意思是有限考虑辅助副本上做数据备份。只有在没有辅助副本的情况下才使用主副本。把辅助副本的优先级别调为100,而主副本50。
我们监听端口稍后创建
确认即可---yes
这个地方是选择初始化数据库的方式。如果你选择Full,你需要提供一个共享地址,AlwaysOn自己自动备份数据库然后还原到目标的辅助副本上。这里我们选择Join only,所以
我们需要事先把数据库备份并还原到目标的辅助数据库上----Join only
开始下一步后,我们查看状态
创建完成

我们展开数据库高可用性组
我们查看角色会多出一个高可用性组角色
我们接着创建一个监听
AlwaysOn创建后,客户端就需要进行连接,为了让应用程序能够透明地连接到主副本而不受故障故障转移的影响,我们需要创建一个侦听器,侦听器就是一个虚拟的网络名称,可以通过这个虚拟网络名称访问可用性组,而不用关心连接的是哪一个节点,它会自动将请求转发到主节点,当主节点发生故障后,辅助节点会变为主节点,侦听器也会自动去侦听主节点。
一个侦听器包括虚拟IP地址、虚拟网络名称、端口号三个元素,一旦创建成功,虚拟网络名称会注册到DNS中,同时为可用性组资源添加IP地址资源和网络名称资源。用户就可以使用此名称来连接到可用性组中。与故障转移群集不同,除了使用虚拟网络名称之外,主副本的真实实例名还可以被用来连接。
SQL Server2012早期版本的SQL Server只有在实例启动的时候地会尝试绑定IP和端口,但是SQL Server2012却允许在副本实例处于运行状况的时候随时绑定新的IP地址、网络名称和端口号。因此可以为随时为为可用性组添加侦听器,而且这个操作会立即生效。当添加了侦听器之后,在SQL Server的错误日志中可以看到类似:在虚拟网络名称上停止和启动侦听器的消息。
要注意的是,SQLBrowser服务是不支持Listener的。这是因为应用程序在使用Listener的虚拟网络名连接SQLServer时,是以一个默认实例的形式进行访问的(只有主机名,没有实例名),因此客户端根本就不会去尝试使用SQLBrowser服务。
定义监听名称及IP
名称:HA-LST;
IP地址:192.168.5.48;
Port为1433
定义完成
我们在查看角色,就会发现有对应的管理地址了
定义完成后,我们可以查看高可用行组的显示面板
我们可以通过显示面板查看高可用性组的状态
接下来我们切换一下;切换前我们需要注意一个问题:切换的时候不能在集群管理器里面切换,需要在高可用性组下切换,不然会有问题,就算切换成功了,有些数据也会出现问题
我们首先在集群管理器里面查看节点所有者
另外我们连接到群集节点后,发现高可用性组下的可用性副本的节点属于辅助节点;
接下来我们准备开始切换,我们使用SSMS连接到第三个节点实例
查看当前可用性组下在第三个节点处于辅助副本状态
我们开始切换
选择主副本
确认信息
转移完成
我们再查看AO1第三节点的AG状态就成了主副本了
我们再从主切换到备
选择新的主副本
链接副本
开始连接
链接成功
确认转移信息
转移完成
我们从SQLCLUSTER上插入一条数据
然后从AO1上查看数据
我们从AO1上插入数据提示,数据库为只读,所以无法插入数据
原因是由于当前节点属于第二节点,如果可读可写的话,需要将该节点转移到主副本节点才可以
我们将AO1\ALWAYON下的AG下的HA-GP1从从副本转移到主副本我们再次插入数据
转移完成

我们再次尝试插入数据
我们从SQLCLUSTER集群节点查看数据是否同步
我们再次到SQLCLUSTER节点插入数据,提示错误
原因是节点属于AO1
但是我们查看数据,从当前节点从AO1插入的数据依然可以同步到SQLCLUSTER
各副本间的数据同步
AlwaysOn必须要维护各副本间的数据一致性,当主副本上的数据发生变化,会同步到辅助副本上。这里AlwaysOn通过三个步骤来完成:
步骤1:主副本记录发生变化的数据;
步骤2:将记录传输到各个辅助副本;
步骤3:把数据变化操作在辅助副本上执行一遍。
具体实现如下:
在主副本和辅助副本上,SQL Server都会启动相应的线程来完成相应的任务。对于一般的SQL Server服务器,即没有配置高可用性,会运行Log Writer的线程,当发生数据修改事务时,此线程负责将本次操对应的日志信息记录到日志缓冲区中,然后再写入到物理日志文件。但如果配置了AlwaysOny主副本的数据库,SQL Server会为它建立一个叫Log Scanner的线程,不间断的工作,负责将日志从日志缓冲区或日志文件里读出,打包成日志块,发送到辅助副本。因此可以保证发生的数据变化,不断送给各辅助副本。
辅助副本上存在固化和重做两个线程完成数据更新操作,固化线程会将主副本Log Scanner所发过来的日志块写入辅助副本磁盘上的日志文件里,因此称为固化,然后重做线程负责从磁盘上读取日志块,将日志记录对应的操作重演一遍,此时主副本和辅助副本上的数据就一致了。重做线程每隔固定的时间点,会跟主副本通信,告知自己的工作进度。主副本由此知道两边数据的差距。Log Scanner负责传送日志块,不需要等待Log Writer完成日志固化;辅助副本完成日志固化以后就会发送消息到主副本,告知数据传输完成,而不需要等待重做完成,这样各自独立的设计,是尽可能减少 AlwaysOn所带来的操作对数据库性能的影响。
SQL Server 2016 Failover + ALwaysOn
标签:dad 选项卡 跳线 集中 数据库服务 ef6 域账户 故障转移 页面
原文地址:http://blog.51cto.com/gaowenlong/2059427