-
1、实验目的
在上一轮的实验中,oracle 11g r2版本下,在87县市实验数据的基础上,比较了分表与分区的效率,得出了分区+全局索引效率较高的结论(见上一篇博客)。不过我们尚未比较过不同的分区粒度有什么效率差异。这一轮的实验,着重于以下几个目的:
- 使实验场景更接近真实使用场景——使用oracle 12c,用更大的数据量进行实验。
- 对比分析按县分区与按省分区的查询效率。
- 继续比较本地空间索引与全局空间索引在不同算法下的查询效率。
-
2、实验数据
实验数据为全国2531个区县,要素总数为46982394。根据不同的数据组织+索引形式,形成了3个不同的实验主体:
- 按县分区+本地空间索引
- 按县分区+全局空间索引
- 按省分区+本地空间索引
-
3、实验方法
在1:500、1:2000、1:10000、1:25000、1:50000、1:100000比例尺下,随机从全国范围内选择3个样本范围,作为空间查询时的查询范围。将6*3个样本范围分别与3个实验主体进行空间查询运算,记录每次查询的耗时。
空间查询所用的算法仍然同于上一篇博客《Oracle Spatial分区应用研究之一:分表与分区性能对比》中介绍的、适用于分区的3种算法,即part_query、part_query2、part_query3。同时,本次实验中,还将通过并行框架对3种算法进行衍生,得到另外3种算法,标记为part_query_p、part_query2_p、part_query3_p。
因此,对每一个实验主体来说,在每一种比例尺样本下均需要用6种算法来进行查询运算。另外,因为算法执行有先后顺序,后执行的算法由于缓存的原因,会比先执行的算法有优势。为了尽量避免这种干扰,会将算法以不同的执行顺序进行两组实验。
-
4、实验结果
-
4.1 第一组实验结果
-
第一组实验,其算法执行顺序为:
Part_query→Part_query2→Part_query3→Part_query_p→Part_query2_p→Part_query3_p
执行结果如下图:
说明:表中蓝色区域为按县分区+本地空间索引在不同比例尺、不同算法下的查询效率;同理,红色区域代表按县分区+全局空间索引,绿色区域代表按省分区+本地空间索引。黄色斑块表示该行的最小值。

根据黄色斑块坐落的位置,可知:
- 在所有比例尺下,按省分区+本地空间索引效率最高,所有耗时最小的查询均发生在该区域。
- Part_query_p算法的查询效率最高,18个实验样本,耗时最小命中17次。
-
4.2 第二组实验结果
第二组实验,其算法执行顺序为:
Part_query_p→Part_query2_p→Part_query3_p→Part_query→Part_query2→Part_query3
执行结果如下图:

根据黄色斑块坐落的位置,可知:
- 在所有比例尺下,按省分区+本地空间索引效率最高,所有耗时最小的查询均发生在该区域。
- Part_query算法的查询效率最高,18个实验样本,耗时最小命中18次。
-
4.3 补充说明
两种实验,分别得出Part_query_p与Part_query算法效率最高的结论。这看似矛盾,实际上正是上文提到的,当算法执行有先后顺序时,会受到缓存的原因。那么对于Part_query_p与Part_query,谁的效率更高呢?
在两组实验中,Part_query_p与Part_query分别是最先执行的算法。分别从两组实验结果中取出Part_query_p与Part_query的实验数据,就可几乎完全排除缓存的影响。
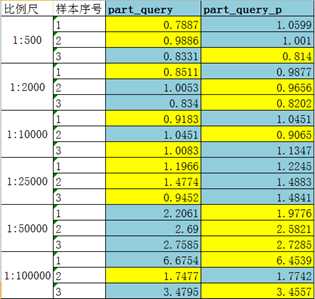
两种算法,各命中9次。说明效率相当。但很明显的是,part_query在大比例尺下(大于1:25000)命中率较高;part_query_p在小比例尺下命中率较高。这与我们的认知一致,即在大任务作业时,并行才会体现优势。
-
5、实验结论
- Oracle 12c环境下,在要素量为四千万级别时,按省分区+本地空间索引效率较高。
- 采用按省分区+本地空间数据组织方式时,Part_query算法较为高效。
(未完待续)