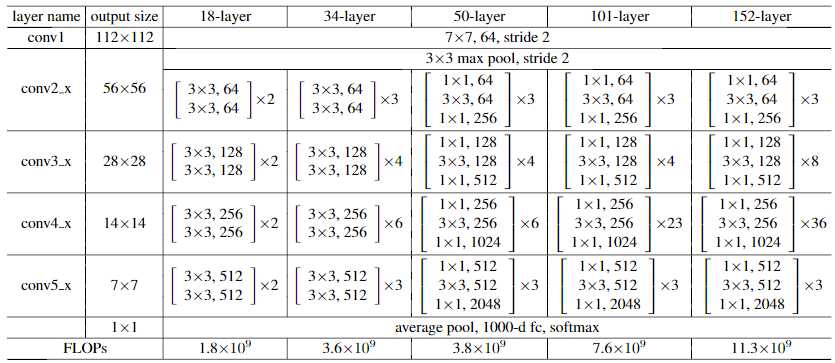
resnet_v1: Deep Residual Learning for Image Recognition
Conv--> bn--> relu
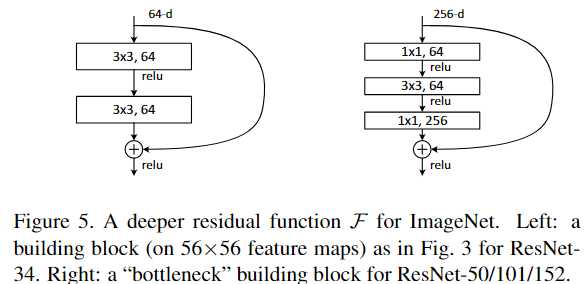
bottleneck结构如下: {because of concerns on the training time that we can afford,所以改成了bottleneck结构}
一下两个结构有相同的复杂度,但是发下左边的维度是64 右边是256 其实就是4倍的关系
resnet_v2 : Identity Mappings in Deep Residual Networks
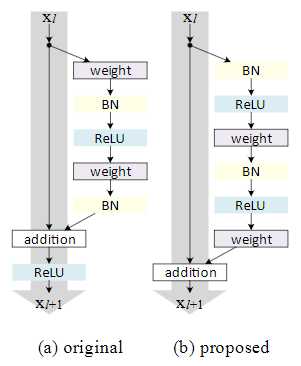
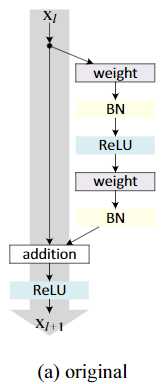
(a)就是第一篇论文采取的结构
这篇文章侧重在想创造一条直接的通路用来传播信息,不仅仅是在一个残差单元内,而是考虑在整个网络中。
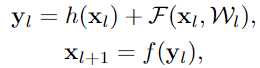
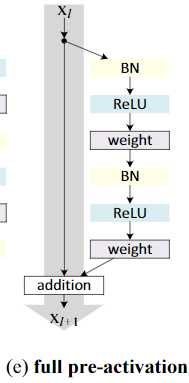
论文发现当h(x)和f(y)都是自映射,信号能直接传播到下个单元,无论是前向传播或是后向传播,所以设计了上图(b)的结构
实验发现h(x)使用1x1卷积或者gate 都不如直接自映射得到的结果好
由post-activation 变成了 pre-activation 之前是relu在conv后, 现在relu在conv前
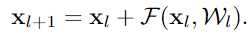
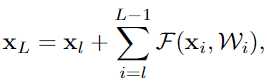
(1) 任何一层的输出都可以由之前某个底层的输出及一个残差结构表示
(2) 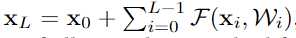
任何一层的输出都可以由原始输入和到它的所有残差输出之和表示, 而以前的网络都是层与层的积表示
(3) 对loss求导发现
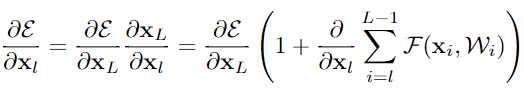
求和那项不会永远都为-1,所以梯度不会弥散 vanish, 即使当weights任意小的时候
对比了不同的shortcut方式,发现就是简单的identity比较好,1x1conv效果更差,可以用来对不同维度的数据进行处理
对比了不同的relu,bn,conv的组合方式,发现以下的full pre-activation的结构效果最好
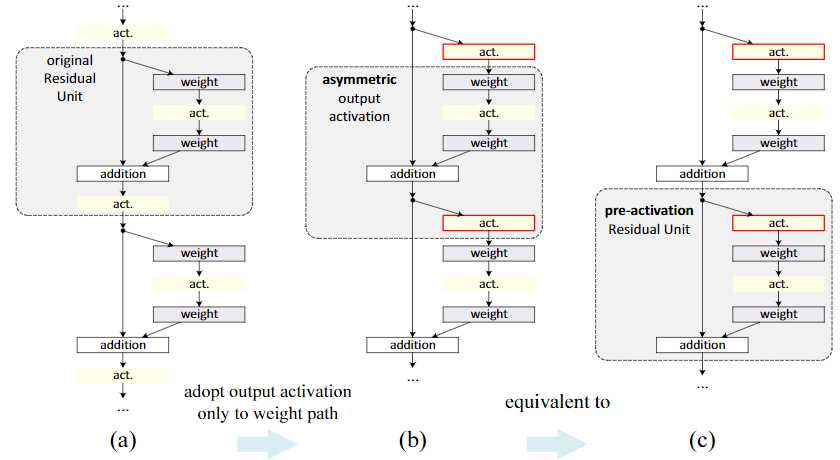
Appendix:

对于第一个residual结构的输入,因为前面是一个单独的conv层,我们需要对conv层的结果进行activation
对于最后一个residual结构,在addition之后要额外进行一个activation
以上为论文解读。接下来是代码实现。
代码实现
def resnet_v2_50:
block = ......
return resnet_v2(block)
def resnet_v2():
net = conv2d(64,6,stride=2, scope="conv1")
net = max_pool2d(net, [3,3] stride=2, scope="pool1")
net = stack_blocks_dense(blocks)
net = batch_norm(net, activation_fn=tf.nn.relu, scope="postnorm")
return net
def stack_blocks_dense(blocks):
for block in blocks:
if not last layer:
else: