前言
微软工程师的一个工程师曾经对性能调优有一个非常形象的比喻:剥洋葱 。我也非常认可,让我们来一层一层拨开外面它神秘的面纱。

六大因素
下面祭出的是我们在给客户分析数据库性能问题最常用的图。
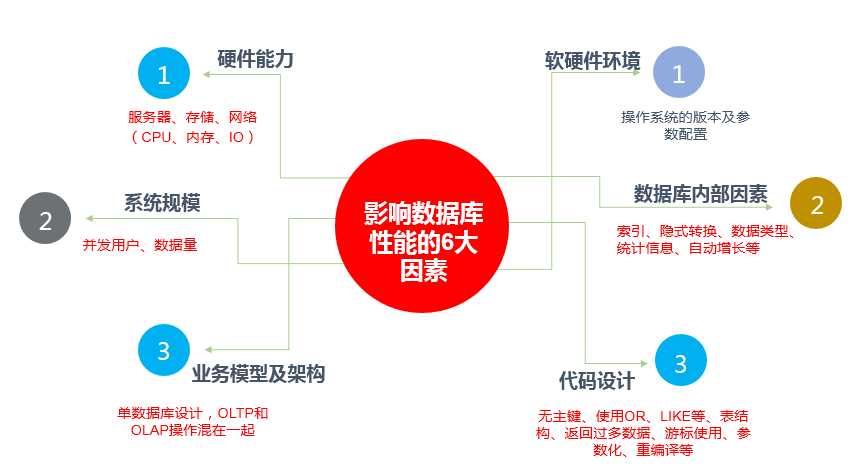
看完这个图,你是不是对性能调优有了个基本的概念了.通常来讲我们会依照下面的顺序来进行分析:
硬件能力
系统规模
数据库内部因素
软件环境
这4个的顺序可以有所调整或者交换,但是对于系统的性能优化一定要从全局出发。切勿一来就深入到某一个SQL语句的优化,因为可能你花费大量的
时间吧一个SQL从20s 优化到1s,但是整个系统的卡慢仍然存在。
最后才是
业务模型及架构
代码设计
实战案例
不废话了,开整开整,直接上干货。
时间:2018年1月某天
事件:某医院客户 下午4点 突然出现大面积的卡慢。整个系统出现严重问题,信息中心电话打爆,医院工程师手足无措。
万幸的是我们给数据库装了‘摄像头’,下面就从监控录像来看看发送了什么。然后加以解决
硬件能力
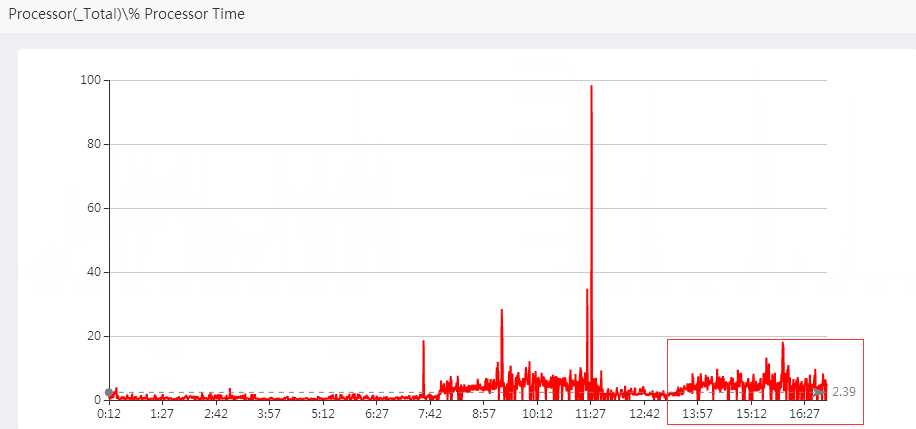
CPU
在问题发生时间段内CPU使用率在20%以下,正常。
Memory
从下面的图像显示,内存使用正常。
页生命周期
可用内存
IO
IO队列平均值很低,15.48 左右有个瞬时的高点,可留意这段时间有没有批量的写入。
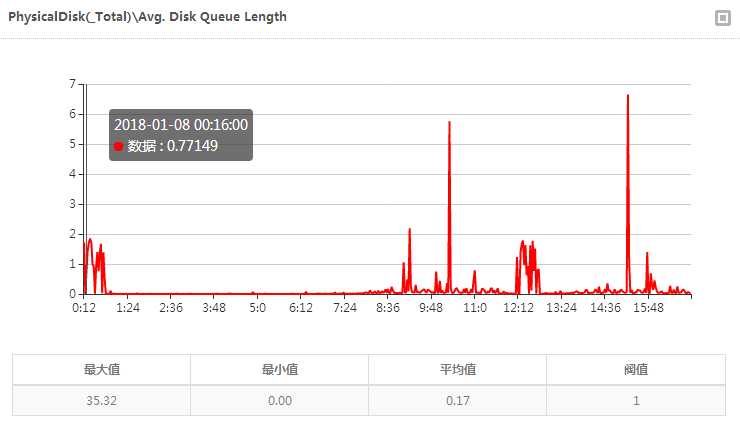
总的来看,硬件资源是足够的。
系统规模
问题发生时,每秒的批请求书并不是一个上升趋势,反而有所下降。这是因为系统的拥堵,等待 ,影响了系统的吞吐量。
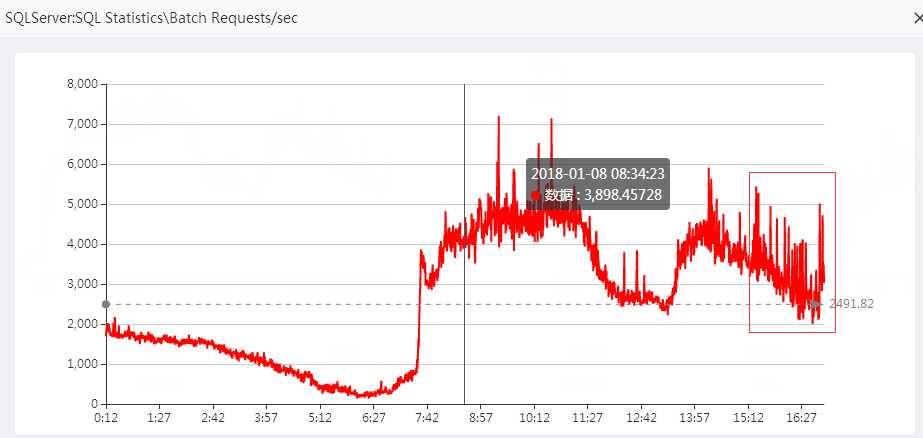
数据库内部因素
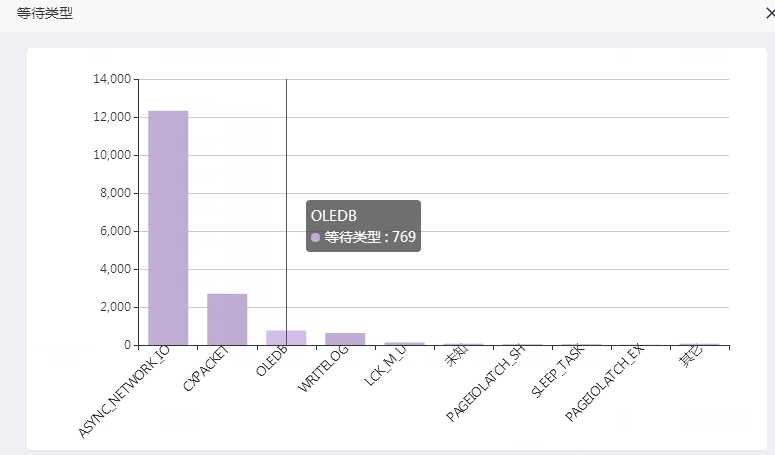
等待
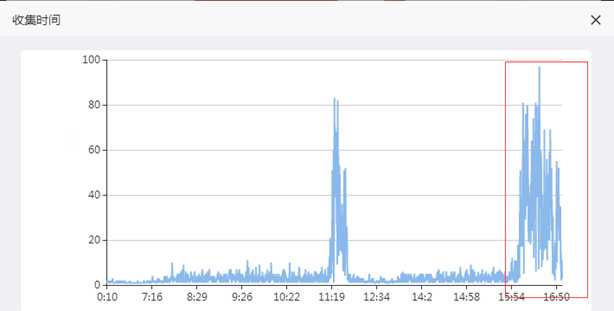
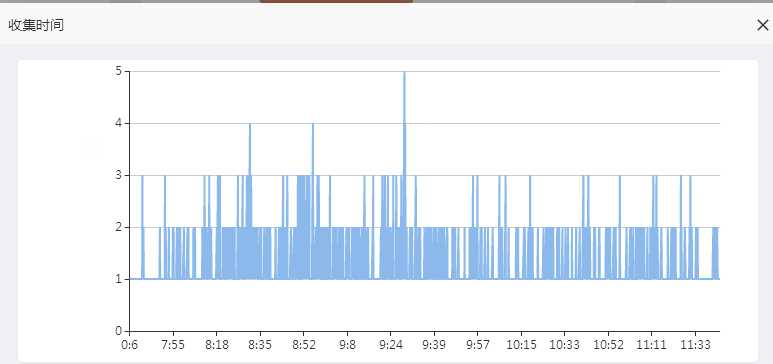
慢语句
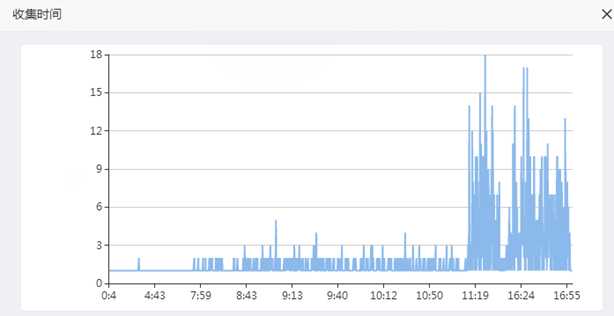
从会话和慢语句的趋势图可以看到,问题发生的时间和客户描述完全吻合,我们可以断定本身事故的确是慢在数据库。
什么导致的慢
检查者个时间段运行中的语句,可以发现下午15.58左右,数据库中开始出现越来越多的CMEMTHREAD等待。
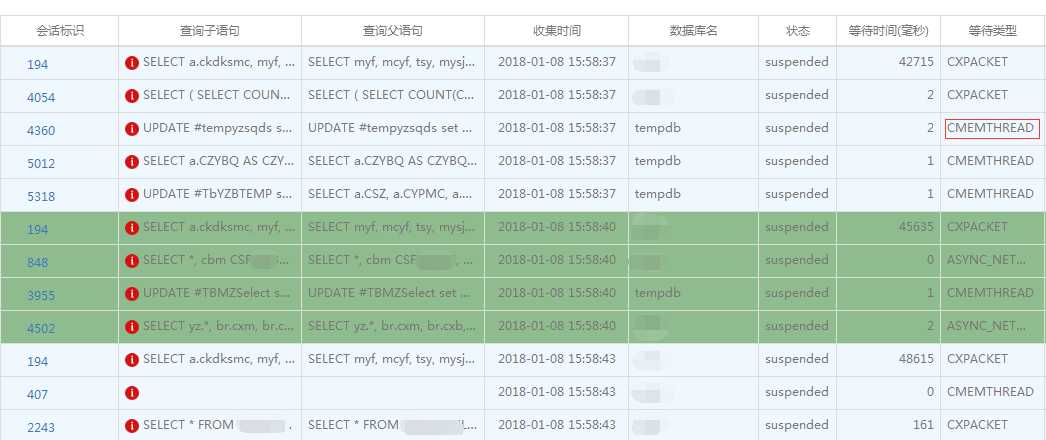
一直到1900页16.08分的时候,出现了最高达100个并发同时出现CMEMTHREAD等待
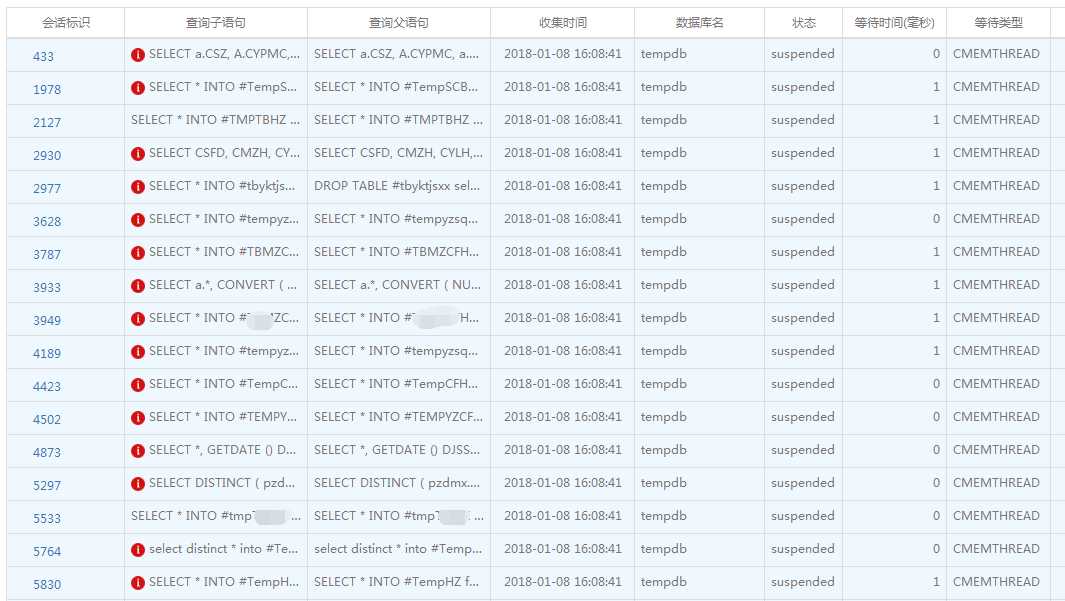
什么是CMEMTHREAD等待
微软官方的描述:在任务正在等待线程安全的内存对象时发生。 当多个任务尝试从同一个内存对象分配内存导致争用时,等待时间可能会增加。
这个描述很晦涩,感觉还是完全不知道等待类型是怎么回事,应该怎么处理这类问题。
实际上,从官方描述来看是内存争用的问题,但是实际上这个问题的关键在于多个任务的争用,实际上是并发的执行的问题。
场景
- 出现在数据库编译或重编译时,将即席执行计划ad hoc plans 插入到计划缓存中的时候
- NUMA架构下,内存对象是按照节点来分区的
内存对象有三种类型的(Global,Per Numa Node,Per CPU)。 SQL Server将允许对内存对象进行分段,以便只有同一节点或cpu上的线程具有相同的底层CMemObj,从而减少来自其他节点或cpu的线程交互,从而提高性能和可伸缩性。减少内存的并发争用
SELECT type, pages_in_bytes, CASE WHEN (0x20 = creation_options & 0x20) THEN ‘Global PMO. Cannot be partitioned by CPU/NUMA Node. TF 8048 not applicable.‘ WHEN (0x40 = creation_options & 0x40) THEN ‘Partitioned by CPU.TF 8048 not applicable.‘ WHEN (0x80 = creation_options & 0x80) THEN ‘Partitioned by Node. Use TF 8048 to further partition by CPU‘ ELSE ‘UNKNOWN‘ END from sys.dm_os_memory_objects order by pages_in_bytes desc
如果你发现,Partitioned by Node 的内存开销是排在前面的,可以使用TRACE FLAG 8048来减少CMEMTHREAD等待.

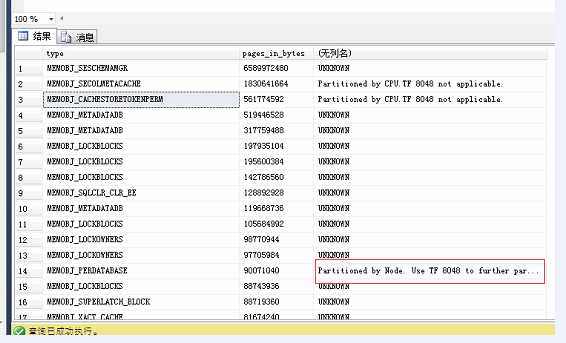
从图中可以看到,客户的 Partitioned by Node 是比较靠后的,排在14位。
3. 补丁
这类场景是最常见的。如果在系统中发现出现大量的CMEMTHREAD等待,优先考虑数据库是不是已经安装最新的补丁
2012 ,2014 当您执行许多特殊查询在 SQL Server 2012年或 SQL Server 2014 CMEMTHREAD 等待
软硬件环境
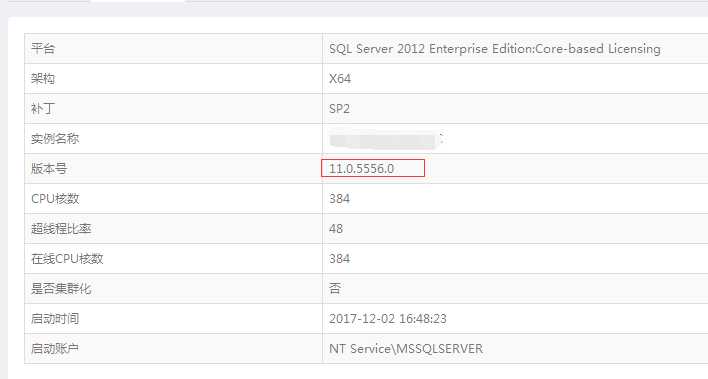
目前数据库的版本是 11.0.5556.0 而前面提到的补丁,安装后的版本是:11.0.5623.0
代码设计
是什么语句产生了等待
都是类似下面的语句,最高时,并发超过100.
SELECT * INTO #Tmp from TB where 1=2
特点如下:
1.语句简单 开销都小于5不会产生并行
2.都采用了select into #temptable的形式
就像上面分析的一样,CMEMTHREAD等待是一个并发问题,而不是一个内存问题。在其他方案行不通的时候,我们可以通过调整此类语句的写法,减少CMEMTHREAD等待.
业务模型及架构
目前系统是单机运行的状态,这其实是很少见的。存在少量OLAP 和OLTP业务混合的情况。后续我们会给客户规划 读写分离 或者负载均衡的解决方案。在
解决方案
安装最新的补丁
至少需要安装前面发的解决等待问题的FIX。建议是直接安装到目前为止最新的2012 SP4补丁。
修改参数
optimize for ad hoc workloads 从0修改为1 。针对将即席执行计划ad hoc plans 插入到计划缓存中的时候 场景,减少ad hoc 查询占用的内存。
增加TEMPDB数据文件的个数
select * into #temptable 会产生大量的闩锁争用,防止在CMEMTHREAD 等待消除后,出现大量的pagelatch 闩锁争用。我经历过很多案例,解决了前面的一个拥堵之后,
后面有产生了新的等待,导致性能更差了。请记住,优化是一个长期的,循序渐进的过程。
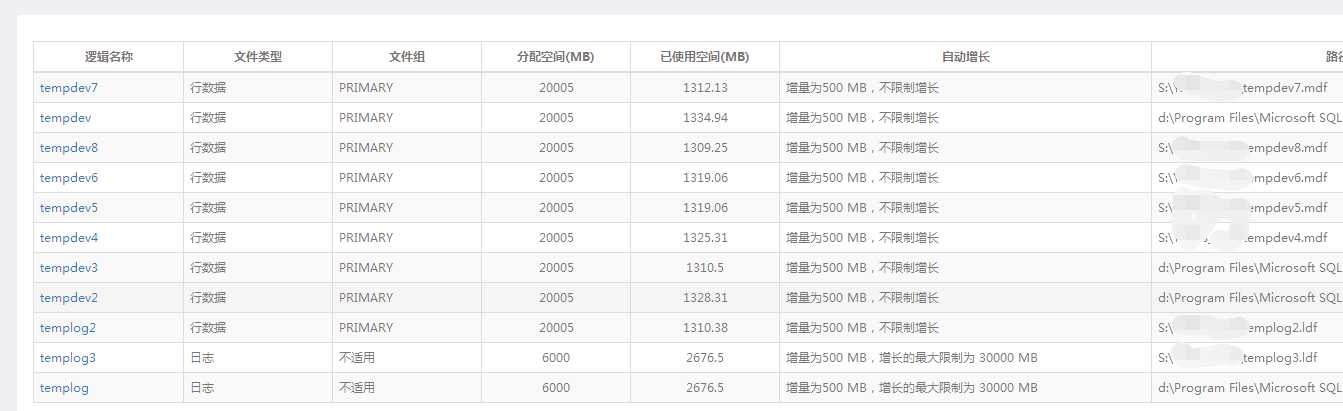
迁移TEMPDB数据文件的位置
目前部分tempdb文件放在S,一般分放在D盘。建议都迁移到S盘(存储上面),增加tempdb的响应速度。如果可能的话,使用SSD来最大化tempdb的性能,将会是不错的选择。
优化程序的代码
修改代码通常都是放在最后面的,因为要牵涉的情况比较多。前面的手段80%的情况下,都可以解决问题。剩下的20%,我们需要,检查程序中的逻辑,看看这些的语句都是什么业务产生的。什么条件会触发这类业务.对应下面类似的语句都使用存储过程,或者参数化后的方式,减少编译和重编译的次数。另外此类语句都会并发创建临时表,可能通过调整tempdb的设置,加快此类语句的执行速度,减少同一时间此类语句的并发数量。
优化效果
经过前面的几个优化手段,第二天开始,没有再出现过一次CMEMTHREAD的等待。
等待
慢语句
总结
通过这篇文件你应该已经完全学会了数据库性能调优的思想。他告诉了我们出现问题时,怎么动手一步一步的排查问题,就像剥洋葱一样一层一层的剥开。
参考
微软官方博客对这类等待的原理和如何调试How It Works: CMemThread and Debugging Them
SQL Server 2016 对这里问题进行了进一步的优化,详细参考 SQL 2016 – It Just Runs Faster: Dynamic Memory Object (CMemThread) Partitioning