sql语句优化:
1: sql语句的时间花在哪儿?
答: 等待时间 , 执行时间.
等待时间:看是不是被锁住了,那就不是语句层面了是服务端层面了,看连接数内存。
执行时间:到底取出多少行,一次性取出1万行那是你的sql语句写的失败,二是扫描多少行,扫描多少行需要技术来分析,通过explain来分析。
可以重构查询和切分查询。
2: sql语句的执行时间,又花在哪儿了?
答:a: 查 ----> 沿着索引查,甚至全表扫描b: 取 ----> 查到行后,把数据取出来(sending data)
3: sql语句的优化思路?
答: 不查, 通过业务逻辑来计算,
比如论坛的注册会员数,我们可以根据前3个月统计的每天注册数, 用程序来估算.
少查, 尽量精准数据,少取行. 我们观察新闻网站,评论内容等,一般一次性取列表 10-30条左右。必须要查,尽量走在索引上查询行.
取时, 取尽量少的列.
比如 select * from tableA, 就取出所有列, 不建议.
比如 select * from tableA,tableB, 取出A,B表的所有列.
4: 如果定量分析查的多少行,和是否沿着索引查?
答: 用explain来分析
explain的列分析
id: 代表select 语句的编号, 如果是连接查询,表之间是平等关系, select 编号都是1,从1开始. 如果某select中有子查询,则编号递增.
mysql> explain select goods_id,goods_name from goods where goods_id in (sele
ct goods_id from goods where cat_id=4) \G
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: goods
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 31
Extra: Using where
*************************** 2. row ***************************
id: 2
select_type: DEPENDENT SUBQUERY
table: goods
type: unique_subquery
possible_keys: PRIMARY,cat_id
key: PRIMARY
key_len: 3
ref: func
rows: 1
Extra: Using where
2 rows in set (0.00 sec)
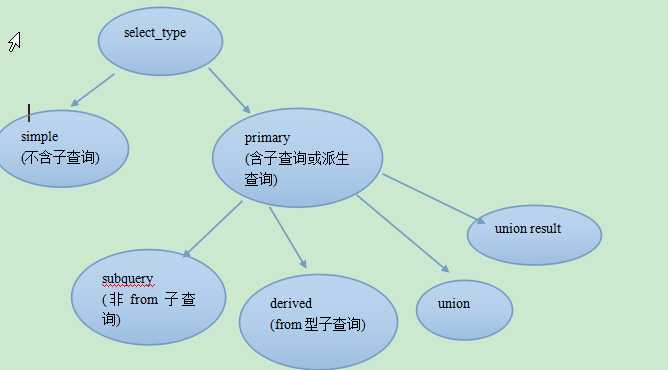
table: 查询针对的表
有可能是:
实际的表名 如select * from t1;
表的别名 如 select * from t2 as tmp;
derived 如from型子查询时
null 直接计算得结果,不用走表
possible_key: 可能用到的索引,注意: 系统估计可能用的几个索引,但最终,只能用1个.
key : 最终用的索引.
key_len: 使用的索引的最大长度,越短速度越快
type列: 是指查询的方式, 非常重要,是分析”查数据过程”的重要依据可能的值
all: 说明语句写的失败。意味着从表的第1行,往后,逐行做全表扫描.,运气不好扫描到最后一行.
index: 比all性能稍好一点,
通俗的说: all 扫描所有的数据行,index 扫描所有的索引节点。一个是到磁盘上扫描所有行,一个是到index索引文件上扫描所有行。但是扫描的行数还是过多也不是很好。希望走索引是对的,但是也不是希望全部扫一遍。
2种情况可能出现:
1:索引覆盖的查询情况下, 能利用上索引,但是又必须全索引扫描.
mysql> explain select goods_id from goods where goods_id=1 or goods_id+1>20
\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: goods
type: index
possible_keys: PRIMARY
key: PRIMARY
key_len: 3
ref: NULL
rows: 31
Extra: Using where; Using index
1 row in set (0.00 sec)
2: 是利用索引来进行排序,但取出所有的节点
select goods_id from goods order by goods_id desc;
分析: 没有加where条件, 就得取所有索引节点,同时,又没有回行,只取索引节点.
再排序,经过所有索引节点.
mysql> explain select goods_id from goods order by goods_id asc\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: goods
type: index
possible_keys: NULL
key: PRIMARY
key_len: 3
ref: NULL
rows: 31
Extra: Using index
1 row in set (0.00 sec)
range: 意思是查询时,能根据索引做范围的扫描,这样比index又好点。
mysql> explain select goods_id,goods_name,shop_price from goods where goods
id >25 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: goods
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 3
ref: NULL
rows: 8
Extra: Using where
1 row in set (0.00 sec)
ref 意思是指 通过索引列,可以直接引用到某些数据行,比renge又好点。
mysql> explain select goods_id,goods_name from goods where cat_id=4 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: goods
type: ref
possible_keys: cat_id
key: cat_id
key_len: 2
ref: const
rows: 3
Extra:
1 row in set (0.00 sec)
在这个例子中,通过cat_id索引 指向N行goods数据,来查得结果.
eq_ref 是指,通过索引列,直接引用某1行数据,效率更高。
常见于连接查询中
mysql> explain select goods_id,shop_price from goods innert join ecs_catego
y using(cat_id) where goods_id> 25 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: innert
type: range
possible_keys: PRIMARY,cat_id
key: PRIMARY
key_len: 3
ref: NULL
rows: 8
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: ecs_category
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: shop.innert.cat_id
rows: 1
Extra: Using index
2 rows in set (0.00 sec)
const, system, null 这3个分别指查询优化到常量级别, 甚至不需要查找时间.这个效率最高。
一般按照主键来查询时,易出现const,system或者直接查询某个表达式,不经过表时, 出现NULL
mysql> explain select goods_id,goods_name,click_count from goods where
_id=4 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: goods
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 3
ref: const
rows: 1
Extra:
1 row in set (0.00 sec)
mysql> explain select max(goods_id) from goods \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: NULL
type: NULL # myisam表的max,min,count在表中优化过,不需要\真正查找,为NULL,mysql有一个sheame表缓存了这些信息,都不需要查表
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
Extra: Select tables optimized away
1 row in set (0.00 sec)
ref列 :指连接查询时, 表之间的字段引用关系.
mysql> explain select goods_id,cat_name,goods_name from goods inner join ec
_category using(cat_id) where ecs_category.cat_name=‘‘ \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: goods
type: ALL
possible_keys: cat_id
key: NULL
key_len: NULL
ref: NULL
rows: 31
Extra:
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: ecs_category
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: shop. goods.cat_id
rows: 1
Extra: Using where
2 rows in set (0.00 sec)
rows : 是指估计要扫描多少行.
extra:
index: 是指用到了索引覆盖,效率非常高
using where 是指光靠索引定位不了,还得where判断一下
using temporary 是指用上了临时表, group by 与order by 不同列时,或group by ,order by 别的表的列.
using filesort : 文件排序(文件可能在磁盘,也可能在内存),
select sum(shop_price) from goods group by cat_id(这句话,用到了临时表和文件排序)