1、引言
Scrapy框架结构清晰,基于twisted的异步架构可以充分利用计算机资源,是做爬虫必备基础,本文将对Scrapy的安装作介绍。
2、安装lxml
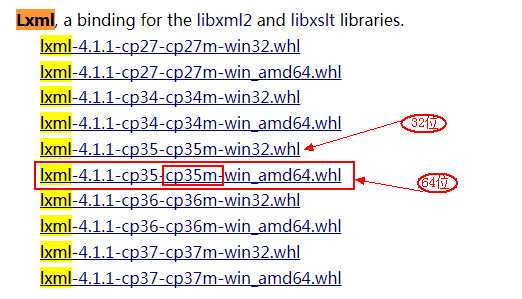
2.1 下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 选择对应python3.5的lxml库
2.2 如果pip的版本过低,先升级pip:
python -m pip install -U pip
2.3 安装lxml库(先将下载的库文件copy到python的安装目录,按住shift键并鼠标右击选择“在此处打开命令窗口”)
pip install lxml-4.1.1-cp35-cp35m-win_amd64.whl
看到出现successfully等字样说明按章成功。
3、 安装Twisted库
3.1 下载链接:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 选择对应python3.5的库文件
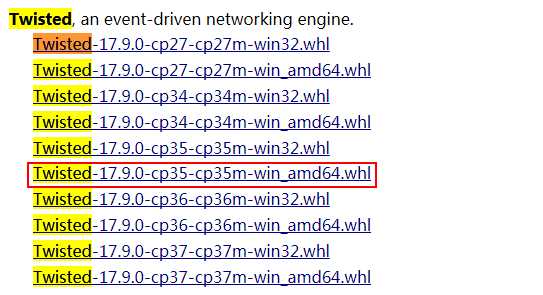
3.2 安装
pip install Twisted-17.9.0-cp35-cp35m-win_amd64.whl
看到出现successfully等字样说明按章成功。
4、安装Scrapy
twisted库安装成功后,安装scrapy就简单了,在命令提示符窗口直接输入命令:
pip install scrapy
看到出现successfully等字样说明按章成功。
5、Scrapy测试
5.1 新建项目
先新建一个Scrapy爬虫项目,选择python的工作目录(我的是:H:\PycharmProjects 然后安装Shift键并鼠标右键选择“在此处打开命令窗口”),然后输入命令:
scrapy startproject allister
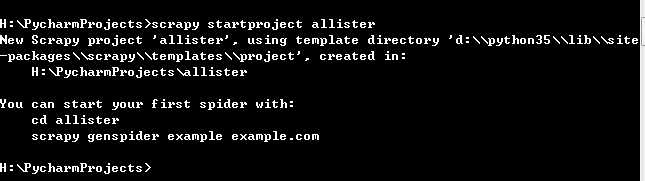
对应目录会生成目录allister文件夹,目录结构如下:
└── allister ├── allister │ ├── __init__.py │ ├── items.py │ ├── pipelines.py │ ├── settings.py │ └── spiders └── scrapy.cfg 简单介绍个文件的作用: # ----------------------------------------------- scrapy.cfg:项目的配置文件; allister/ : 项目的python模块,将会从这里引用代码 allister/items.py:项目的items文件 allister/pipelines.py:项目的pipelines文件 allister/settings.py :项目的设置文件 allister/spiders : 存储爬虫的目录
5.2 修改allister/items.py文件:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class AllisterItem(scrapy.Item):
name = scrapy.Field()
level = scrapy.Field()
info = scrapy.Field()
5.3 编写文件 AllisterSpider.py
# !/usr/bin/env python
# -*- coding: utf-8 -*-
# @File : ItcastSpider.py
# @Author: Allister.Liu
# @Date : 2018/1/18
# @Desc :
import scrapy
from allister.items import AllisterItem
class ItcastSpider(scrapy.Spider):
name = "ic2c"
allowed_domains = ["http://www.itcast.cn"]
start_urls = [
"http://www.itcast.cn/channel/teacher.shtml#ac"
]
def parse(self, response):
items = []
for site in response.xpath(‘//div[@class="li_txt"]‘):
item = AllisterItem()
t_name = site.xpath(‘h3/text()‘)
t_level = site.xpath(‘h4/text()‘)
t_desc = site.xpath(‘p/text()‘)
unicode_teacher_name = t_name.extract_first().strip()
unicode_teacher_level = t_level.extract_first().strip()
unicode_teacher_info = t_desc.extract_first().strip()
item["name"] = unicode_teacher_name
item["level"] = unicode_teacher_level
item["info"] = unicode_teacher_info
items.append(item)
return items
编写完成后复制至项目的 \allister\spiders目录下,cmd选择项目根目录输入以下命令:
scrapy crawl ic2c -o ic2c_infos.json -t json
抓取的数据将以json的格式存储在ic2c_infos.json文件中;
如果出现如下错误请看对应解决办法: