Python内建的字典就是用 hash table实现的。这里我们只是通过实现自己的hash table来加深对hash table 和hash functions的理解。
【 概念1: Mapping (映射)】
字典通过键(Key)来索引。一个key对应一个存储的value。任意不可变的数据类型均可作为key。
【 概念2:Hash Table (哈希表)】
Hash Table根据key直接访问在内存存储位置的数据结构,因而加快了查找速度 (O(1))。
下图是一个size为11的空的Hash Table, 每一个元素初始化为None:

【 概念3: Hash function (散列函数) 】
key对应的value存放在f(key)的存储位置上,这个对应关系f就叫做Hash Function:
构造Hash Function的方法有很多:
例如 (1) Remainder Method (除留余数法):
假设我们有一个空的Hash Table, 它的size (表长)为11, 现在我们要在Hash Table 中存放一系列整数key: 54, 26, 93, 17, 77, 31;则 remainder hash function 为 h(key)=key%11。
结果如下:
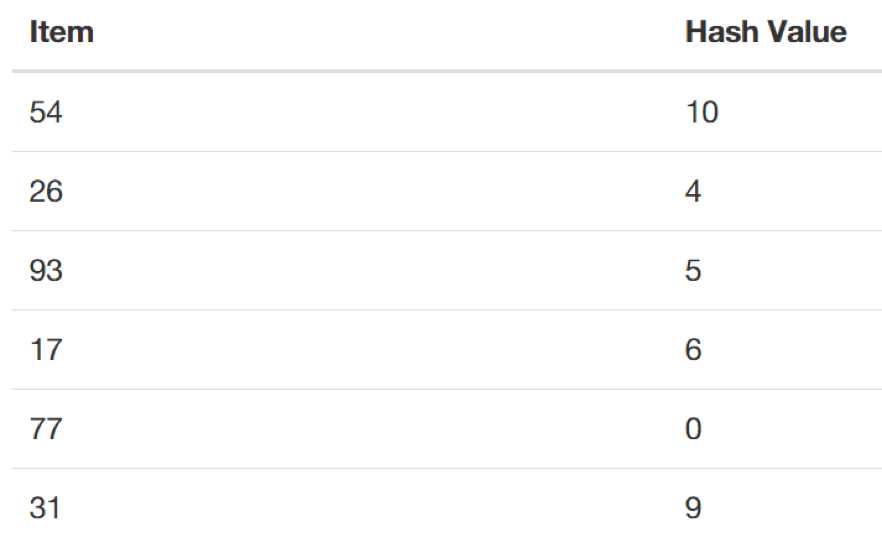
现在我们的hash table变成:

【概念4: load factor (载荷因子) 】λ=number_of_keys/table_size. 在上述例子中,我们存放了6个items, hash table的长度为11, 则其对应的载荷因子为6/11。
当我们想要查找一个key的时候,我们只需要利用hash function算出相应的存储位置(slot name) ,查看该位置是否存储了key。这一搜索操作时间复杂性为O(1)。
【概念5: collision or clash (冲突) 】:两个items可能对应同一个hash function地址,这种情况称为冲突。 例如当我们采用remainder hash function时, 44%11 和77%11都等于0。
这种情况下需要选另外的hash function, 或对冲突结果进行处理。
我们先来介绍其他几种hash function。我们希望能构建一个hash function,使得发生冲突的数量最小化,便于计算,并且在hash table中均匀分布:
(2)Folding Method (折叠法):
将关键字(key)分割成位数相同的几部分(最后一部分位数可能不同),然后将这几部分求和,最后再做除留余数法。
例如:我们的key是一个电话号码4365554601,两个数字为一组(43,65,55,46,01),将这些部分求和43+65+55+46+01=210,最后求余210%11=1。 因此这个电话号码在
hash table 中存储在slot 1。
(3)Mid-square Method (平方取中法):
将关键字取平方后,取其中间的几位数求余作为哈希地址。
例如: 我们的key是44, 首先取平方44^2=1936, 然后取中间的两位数字93,再取余数93%11=5即为其哈希地址。
对于非整数的key,例如string(字符串),我们可以利用其ordinal values来计算:
例如 字符串‘cat‘, ord(‘c‘)=99, ord(‘a‘)=97, ord(‘t‘)=116, 所以对应的哈希地址可以是(99+97+116)%11 =4
接下来,我们讨论【冲突处理】的方法:
(1) open addressing (开放定址法): 当发生冲突时,我们在hash table中查找下一个空的位置来存放发生冲突的key。这里介绍两种寻找的方式:
(i) Linear Probing (线性探测): 相当于逐个探测hash table,直到查找到一个空的slot,把key存放在该位置。例如,发生冲突的hash value是h, 后面查找的顺序为h+1, h+2, h+3...
为了防止聚集(clustering),可采用 skip slots的方法。
(ii) Quadratic Probing (平方探测): 即,发生冲突的hash value是h,则下一个查找的位置为h+1, 再后面的为h+4,h+9,h+16...
(2)chaining (链表法):将hash value相同的所有元素保存在一个链表中。但发生同一个位置链接的元素越多,搜索难度越大。链表的示意图如下:
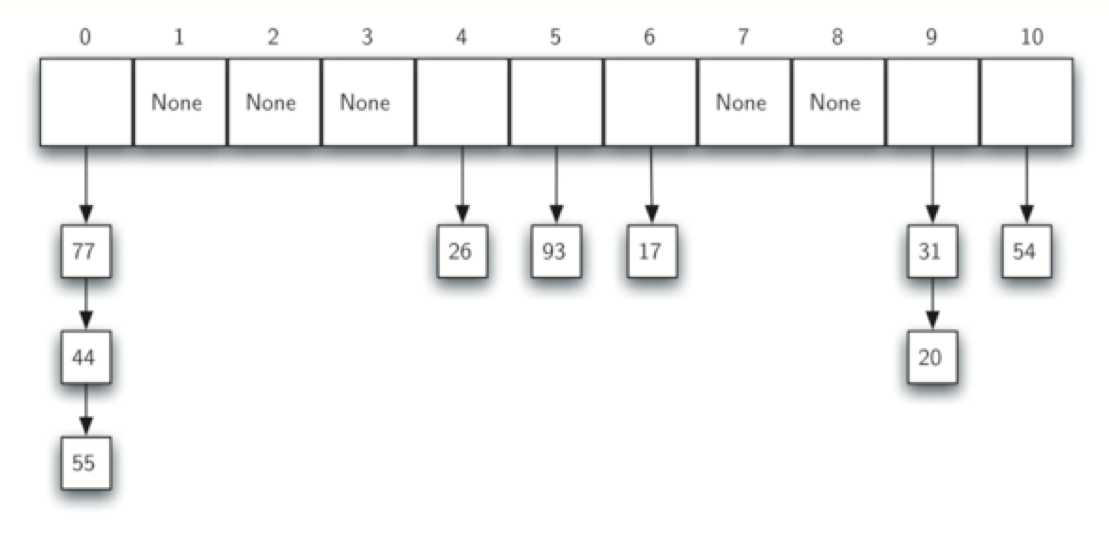
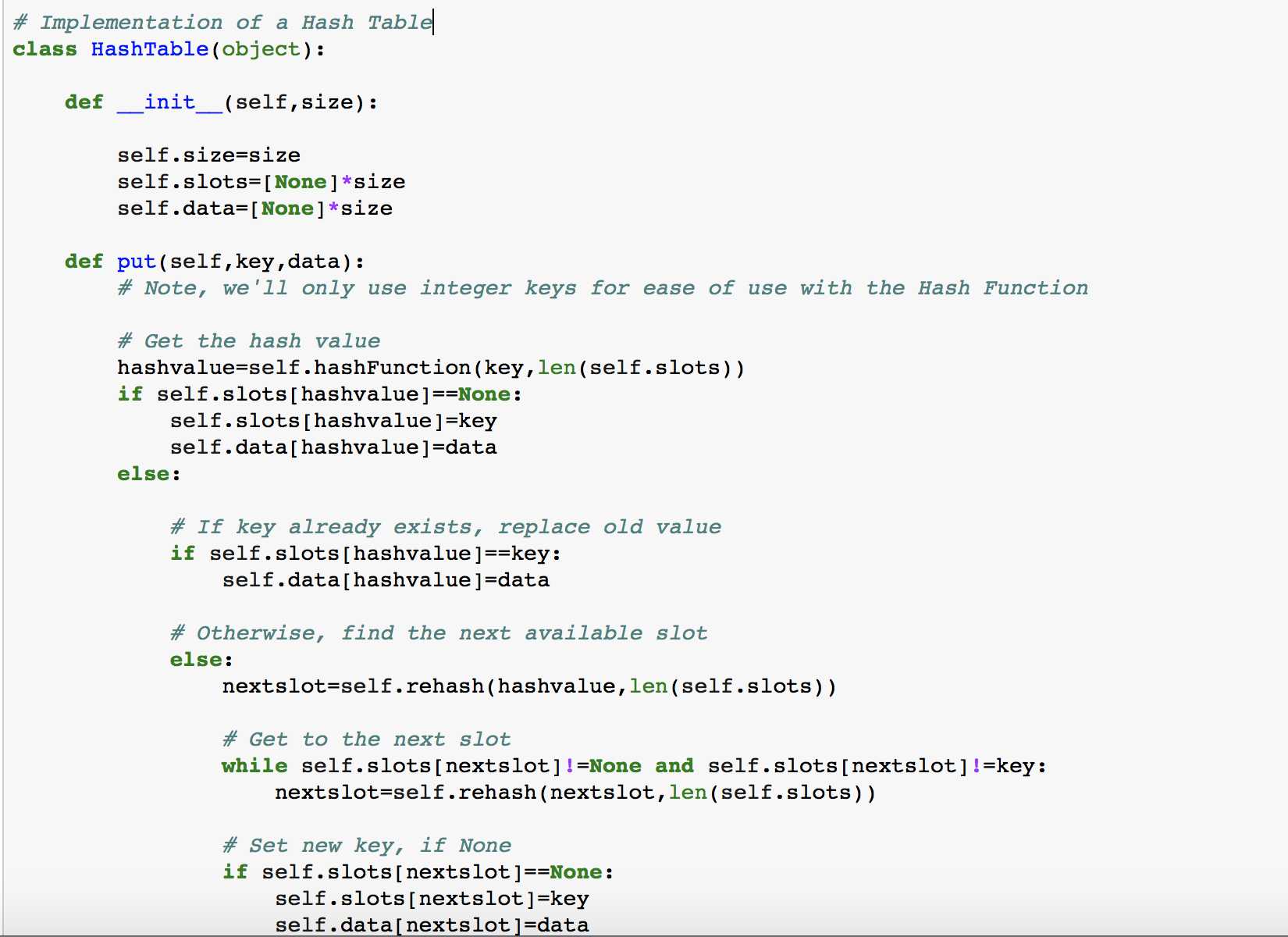
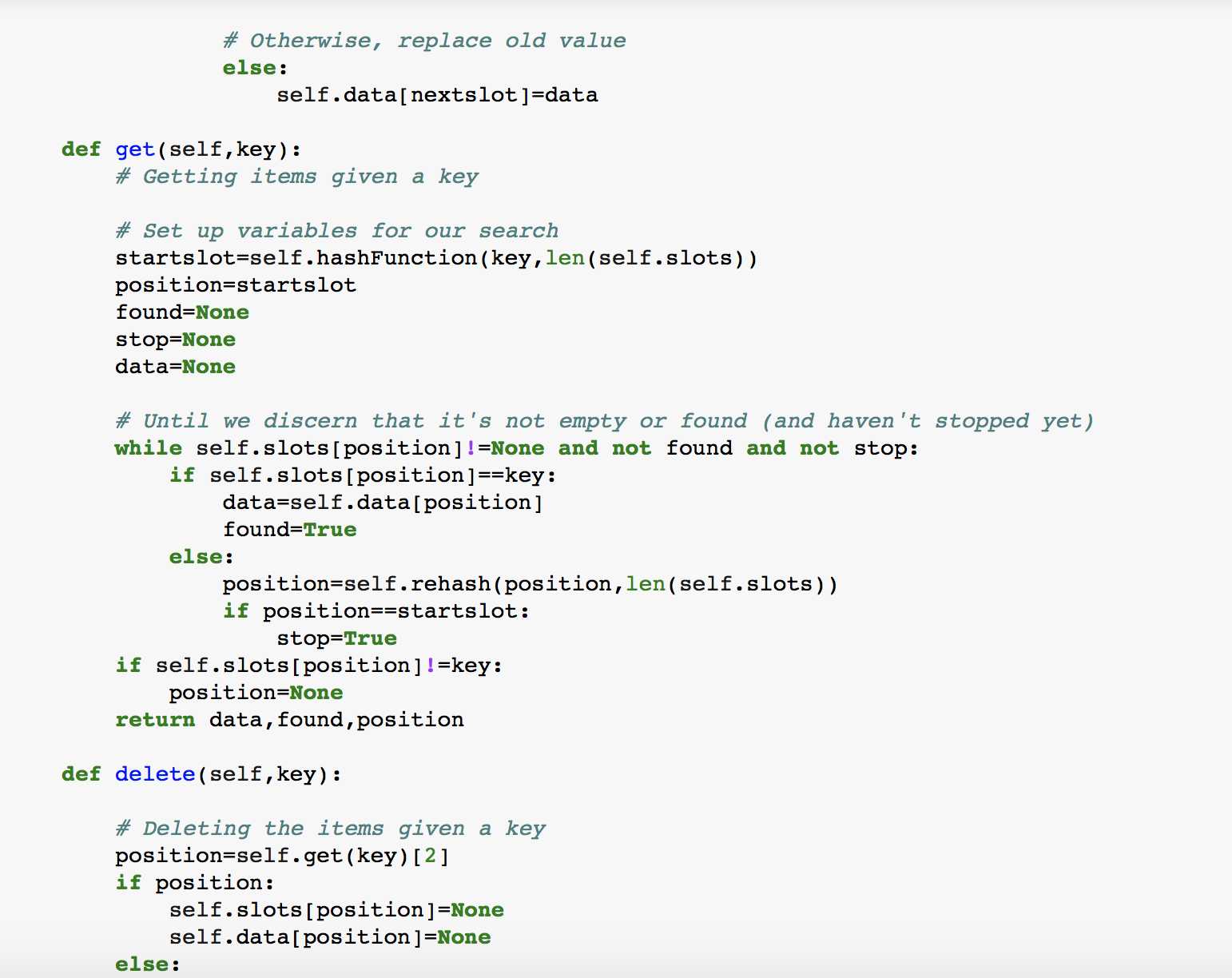
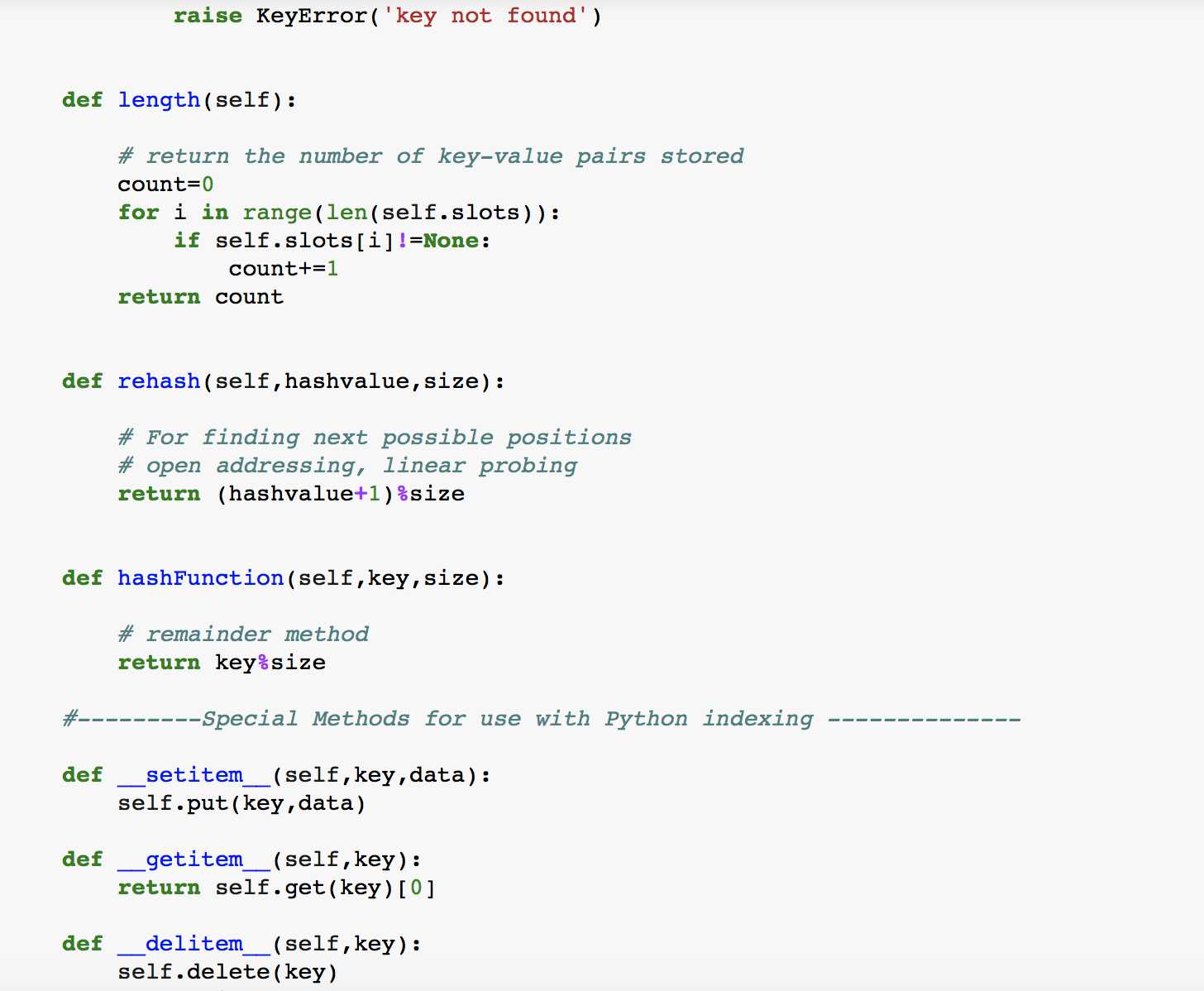
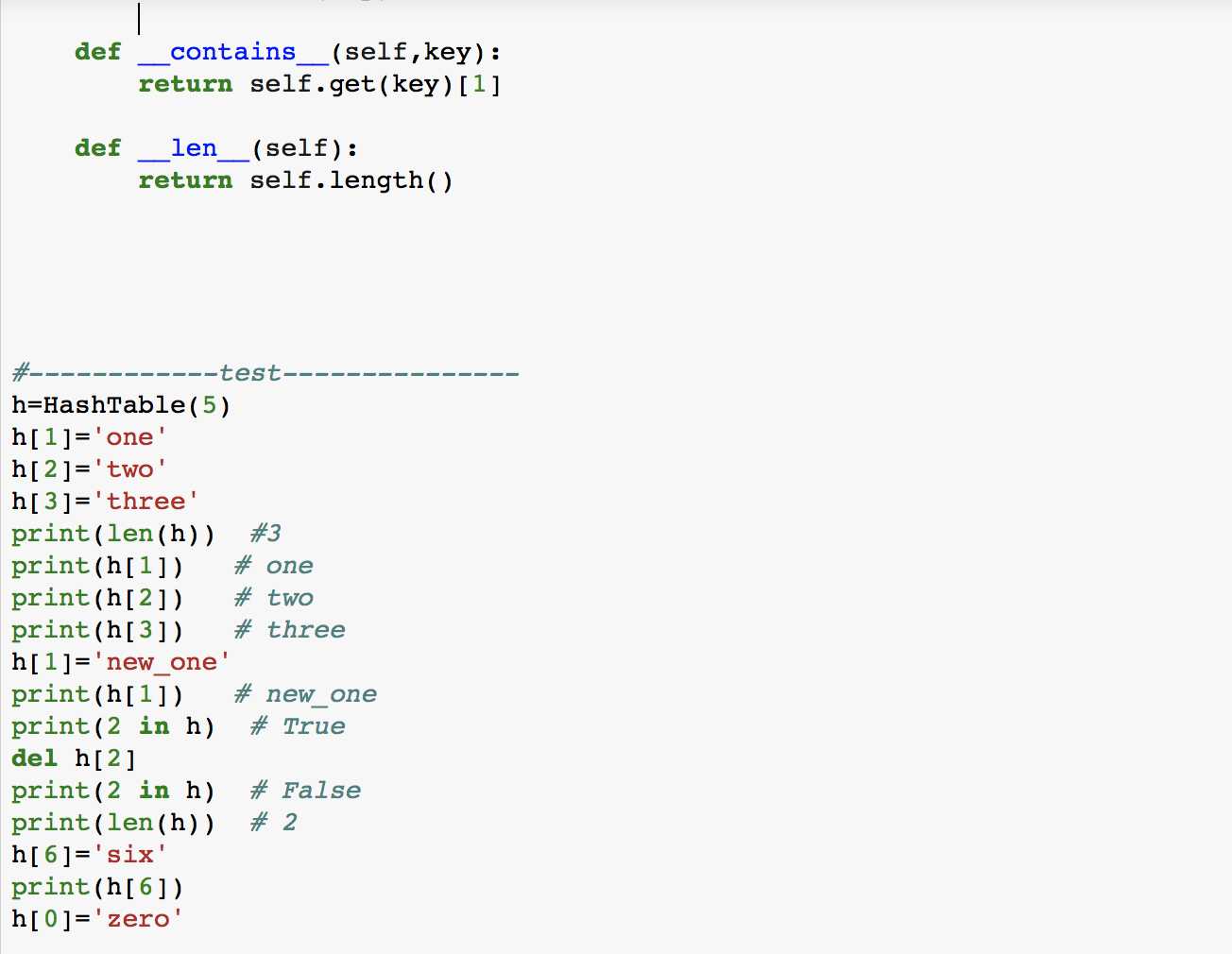
最后,我们来实现自己的Hash Table, 另其包含以下几种methods:
HashTable(size): 建立一个新的,空的映射。它返回一个空的映射集合,初始化表长为size
put(key,val):向表中添加一对新的key-value。如果表中已经存在这个key,则更新这个key对应的value。
get(key): 给定一个key,返回其对应的value。如果表中不存在这个key则返回None
del : 通过使用 del map[key] 删除对应的key-value。
len(): 返回表中存放的key-value对的数量
in: 使用key in map判断key是否在map中,在则返回True,不在则返回False