本文为实现分布式任务调度系统中用到的一些关键技术点分享——Consistent Hashing算法原理和Java实现,以及效果测试。
背景介绍
一致性Hashing在分布式系统中经常会被用到, 用于尽可能地降低节点变动带来的数据迁移开销。Consistent Hashing算法在1997年就在论文Consistenthashing and random trees中被提出。
先来简单理解下Hash是解决什么问题。假设一个分布式任务调度系统,执行任务的节点有n台机器,现有m个job在这n台机器上运行,这m个Job需要逐一映射到n个节点中一个,这时候可以选择一种简单的Hash算法来让m个Job可以均匀分布到n个节点中,比如 hash(Job)%n ,看上去很完美,但考虑如下两种情形:
- n个节点中有一个宕掉了,这时候节点数量变更为n-1,此时的映射公式变成 hash(Job)%(n-1)
- 由于Job数量增加,需要新增机器,此时的映射公式变成 hash(Job)%(n+1)
1、2两种情形可以看到,基本上所有的Job会被重新分配到跟节点变动前不同的节点上,意味着需要迁移几乎所有正在运行的Job,想想这样会给系统带来多大的复杂性和性能损耗。
另外还有一种情况,假设节点的硬件处理性能不完全一致,想让性能高的节点多被分配一些Job,这时候上述简单的Hash映射算法更是很难做到。
如何解决这种节点变动带来的大量数据迁移和数据不均匀分配问题呢?一致性哈希算法就很巧妙的解决了这些问题。
Consistent Hashing是一种Hashing算法,典型的特征是:在减少或者添加节点时,可以尽可能地保证已经存在Key映射关系不变,尽可能地减少Key的迁移。
Consistent Hashing算法原理,如何处理Job->Node映射过程
- 确定hashing值空间
给定值空间2^32,[0,2^32]是所有hash值的取值空间,形象地描述为如下一个环(ring):

2. 节点向值空间映射
将节点Node向这个值空间映射,取Node的Hash值,选取一个可以固定标识一个Node的属性值进行Hashing,假设以字符串形式输入,算法如下:
可以取Node标识的md5值,然后截取其中32位作为映射值。md5取值如下:
private byte[] md5(String value) { MessageDigest md5; try { md5 = MessageDigest.getInstance("MD5"); } catch (NoSuchAlgorithmException e) { throw new IllegalStateException(e.getMessage(), e); } md5.reset(); byte[] bytes; try { bytes = value.getBytes("UTF-8"); } catch (UnsupportedEncodingException e) { throw new IllegalStateException(e.getMessage(), e); } md5.update(bytes); return md5.digest(); }

![]()
因为映射值只需要32位即可,所以可以利用以下方式计算最终值(number取0即可):
private long hash(byte[] digest, int number) { return (((long) (digest[3 + number * 4] & 0xFF) << 24) | ((long) (digest[2 + number * 4] & 0xFF) << 16) | ((long) (digest[1 + number * 4] & 0xFF) << 8) | (digest[0 + number * 4] & 0xFF)) & 0xFFFFFFFFL; }
![]()
把n个节点Node通过以上方式取得hash值,映射到环形值空间如下:
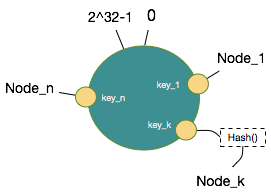
算法中,将以有序Map的形式在内存中缓存每个节点的Hash值对应的物理节点信息。缓存于这个内存变量中:private final TreeMap<Long, String> virtualNodes 。
3. 数据向值空间映射
数据Job取hash的方式跟节点Node的方式一模一样,可以使用上述md5->hash的方式同样将所有Job取得Hash映射到这个环中。
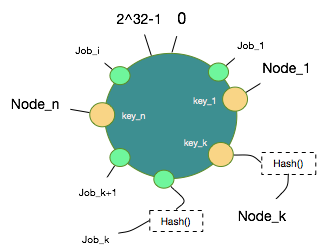
4. 数据和节点映射
当节点和数据都被映射到这个环上后,可以设定一个规则把哪些数据hash值放在哪些节点Node Hash值上了,规则就是,沿着顺时针方向,数据hash值向后找到第一个Node Hash值即认为该数据hash值对应的数据映射到该Node上。至此,这一个从数据到节点的映射关系就确定了。
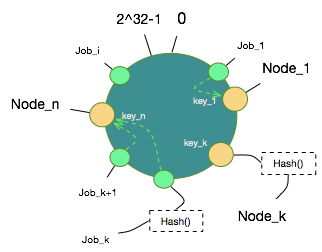
顺时针找下一个Node Hash值算法如下:
public String select(Trigger trigger) { String key = trigger.toString(); byte[] digest = md5(key); String node = sekectForKey(hash(digest, 0)); return node; } private String sekectForKey(long hash) { String node; Long key = hash; if (!virtualNodes.containsKey(key)) { SortedMap<Long, String> tailMap = virtualNodes.tailMap(key); if (tailMap.isEmpty()) { key = virtualNodes.firstKey(); } else { key = tailMap.firstKey(); } } node = virtualNodes.get(key); return node; }
![]()
Trigger是对Job一次触发任务的抽象,这里可忽略关注,重写了toString方法返回一个标记一个Job的唯一标志,计算Hash值,从节点Hash值中按规则寻找。 虚拟节点后续介绍。
算法表现
接下来就可以见识下一致性哈希基于这样的数据结构是如何发挥前文提到的优势的。
1. 节点减少时,看需要迁移的节点情况
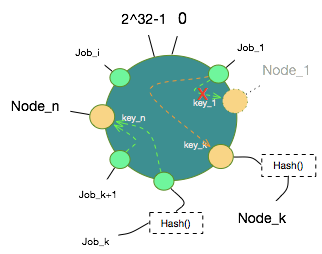
假设Node_1宕掉了,图中数据对象只有Job_1会被重新映射到Node_k,而其他Job_x扔保持原有映射关系不变。
2. 节点新增时
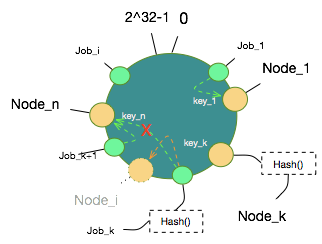
假设新增Node_i,图中数据对象只有Job_k会被重新映射到Node_i上,其他Job_x同样保持原有映射关系不变。
算法优化-虚拟节点
上述算法过程,会想到两个问题,第一,数据对象会不会分布不均匀,特别是新增节点或者减少节点时;第二,前文提到的如果想让部分节点多映射到一些数据对象,如何处理。虚拟节点这是解决这个问题。
将一个物理节点虚拟出一定数量的虚拟节点,分散到这个值空间上,需要尽可能地随机分散开。
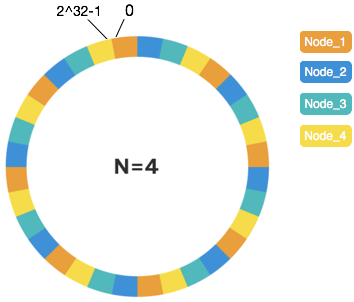
假设有4个物理节点Node,环上的每个色块代表一个虚拟节点涵盖的hash值区域,每种颜色代表一个物理节点。当物理节点较少时,虚拟节点数需要更高来确保更好的一致性表现。经测试,在物理节点为个位数时,虚拟节点可设置为160个,此时可带来较好的表现(后文会给出测试结果,160*n个总节点数情况下,如果发生一个节点变动,映射关系变化率基本为1/n,达到预期)。
具体做算法实现时,已知物理节点,虚拟节点数设置为160,可将这160*n的节点计算出Hash值,以Hash值为key,以物理节点标识为value,以有序Map的形式在内存中缓存,作为后续计算数据对象对应的物理节点时的查询数据。代码如下,virtualNodes中缓存着所有虚拟节点Hash值对应的物理节点信息。
public ConsistentHash(List<String> nodes) { this.virtualNodes = new TreeMap<>(); this.identityHashCode = identityHashCode(nodes); this.replicaNumber = 160; for (String node : nodes) { for (int i = 0; i < replicaNumber / 4; i++) { byte[] digest = md5(node.toString() + i); for (int h = 0; h < 4; h++) { long m = hash(digest, h); virtualNodes.put(m, node); } } } }
算法测试
以上详细介绍了一致性哈希(Consistent Hashing)的算法原理和实现过程,接下来给出一个测试结果:
以10个物理节点,160个虚拟节点,1000个数据对象做测试,10个物理节点时,这1000个数据对象映射结果如下:
减少一个节点前,path_7节点数据对象个数:113
减少一个节点前,path_0节点数据对象个数:84
减少一个节点前,path_6节点数据对象个数:97
减少一个节点前,path_8节点数据对象个数:122
减少一个节点前,path_3节点数据对象个数:102
减少一个节点前,path_2节点数据对象个数:99
减少一个节点前,path_4节点数据对象个数:98
减少一个节点前,path_9节点数据对象个数:102
减少一个节点前,path_1节点数据对象个数:99
减少一个节点前,path_5节点数据对象个数:84
减少一个物理节点path_9,此时9个物理节点,原有1000个数据对象映射情况如下:
减少一个节点后,path_7节点数据对象个数:132
减少一个节点后,path_6节点数据对象个数:107
减少一个节点后,path_0节点数据对象个数:117
减少一个节点后,path_8节点数据对象个数:134
减少一个节点后,path_3节点数据对象个数:104
减少一个节点后,path_4节点数据对象个数:104
减少一个节点后,path_2节点数据对象个数:115
减少一个节点后,path_5节点数据对象个数:89
减少一个节点后,path_1节点数据对象个数:98
先从数量上对比下每个物理节点上数据对象的个数变化:
减少一个节点后,path_7节点数据对象个数从113变为132
减少一个节点后,path_6节点数据对象个数从97变为107
减少一个节点后,path_0节点数据对象个数从84变为117
减少一个节点后,path_8节点数据对象个数从122变为134
减少一个节点后,path_3节点数据对象个数从102变为104
减少一个节点后,path_4节点数据对象个数从98变为104
减少一个节点后,path_2节点数据对象个数从99变为115
减少一个节点后,path_5节点数据对象个数从84变为89
减少一个节点后,path_1节点数据对象个数从99变为98
可以看到基本是均匀变化,现在逐个对比每个数据对象前后映射到的物理节点,发生变化的数据对象占比情况,统计如下:
数据对象迁移比率:0.9%
该结果基本体现出一致性哈希所能带来的最佳表现,尽可能地减少节点变动带来的数据迁移。
附Java完整代码
最后附上完整的算法代码,供大家参照。代码中数据对象是以Trigger抽象,可以调整成特定场景的,即可运行测试。
package com.cronx.core.common;
import com.cronx.core.entity.Trigger;
import java.io.UnsupportedEncodingException;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.util.Collections;
import java.util.List;
import java.util.SortedMap;
import java.util.TreeMap;
/**
* Created by echov on 2018/1/9.
*/
public class ConsistentHash {
private final TreeMap<Long, String> virtualNodes;
private final int replicaNumber;
private final int identityHashCode;
private static ConsistentHash consistentHash;
public ConsistentHash(List<String> nodes) {
this.virtualNodes = new TreeMap<>();
this.identityHashCode = identityHashCode(nodes);
this.replicaNumber = 160;
for (String node : nodes) {
for (int i = 0; i < replicaNumber / 4; i++) {
byte[] digest = md5(node.toString() + i);
for (int h = 0; h < 4; h++) {
long m = hash(digest, h);
virtualNodes.put(m, node);
}
}
}
}
private static int identityHashCode(List<String> nodes){
Collections.sort(nodes);
StringBuilder sb = new StringBuilder();
for (String s: nodes
) {
sb.append(s);
}
return sb.toString().hashCode();
}
public static String select(Trigger trigger, List<String> nodes) {
int _identityHashCode = identityHashCode(nodes);
if (consistentHash == null || consistentHash.identityHashCode != _identityHashCode) {
synchronized (ConsistentHash.class) {
if (consistentHash == null || consistentHash.identityHashCode != _identityHashCode) {
consistentHash = new ConsistentHash(nodes);
}
}
}
return consistentHash.select(trigger);
}
public String select(Trigger trigger) {
String key = trigger.toString();
byte[] digest = md5(key);
String node = sekectForKey(hash(digest, 0));
return node;
}
private String sekectForKey(long hash) {
String node;
Long key = hash;
if (!virtualNodes.containsKey(key)) {
SortedMap<Long, String> tailMap = virtualNodes.tailMap(key);
if (tailMap.isEmpty()) {
key = virtualNodes.firstKey();
} else {
key = tailMap.firstKey();
}
}
node = virtualNodes.get(key);
return node;
}
private long hash(byte[] digest, int number) {
return (((long) (digest[3 + number * 4] & 0xFF) << 24)
| ((long) (digest[2 + number * 4] & 0xFF) << 16)
| ((long) (digest[1 + number * 4] & 0xFF) << 8)
| (digest[0 + number * 4] & 0xFF))
& 0xFFFFFFFFL;
}
private byte[] md5(String value) {
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new IllegalStateException(e.getMessage(), e);
}
md5.reset();
byte[] bytes;
try {
bytes = value.getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
throw new IllegalStateException(e.getMessage(), e);
}
md5.update(bytes);
return md5.digest();
}
}
转自:https://my.oschina.net/yaohonv/blog/1610096