字符串匹配是我们经常遇到的问题,常规来想我们首先想到的是暴力匹配
暴力匹配算法
暴力匹配的思路,假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置,则有:
- 如果当前字符匹配成功(即S[i] == P[j]),则i++,j++,继续匹配下一个字符;
- 如果失配(即S[i]! = P[j]),令i = i - (j - 1),j = 0。相当于每次匹配失败时,i 回溯,j 被置为0。
- 但是这种方法的复杂度是O(nm),显然不够好。
- kmp算法通过一个O(m)的预处理,使匹配的复杂度降为O(n+m)。
kmp算法(Knuth-Morris-Pratt算法)
为啥子又叫“”看毛片“”算法呢,因为学习kmp算法和看毛片差不多,都是初识时新鲜无比为它巧妙的思想所震惊,仔细研究后发现也就那么回事....过一段时间后又再学习时那种惊奇新鲜感又上来了.....哈哈
它以三个发明者命名,起头的那个K就是著名科学家Donald Knuth。
首先用一个简单易懂的例子来了解一下kmp的基本思想,该例子来自http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
1.

首先,字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。
2.

因为B与A不匹配,搜索词再往后移。
3.

就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。
4.

接着比较字符串和搜索词的下一个字符,还是相同。
5.

直到字符串有一个字符,与搜索词对应的字符不相同为止。
6.

这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把"搜索位置"移到已经比较过的位置,重比一遍。
7.

一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。KMP算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。
8.

怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了。
9.

已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查表可知,最后一个匹配字符B对应的"部分匹配值"为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位。
10.

因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2("AB"),对应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。
11.
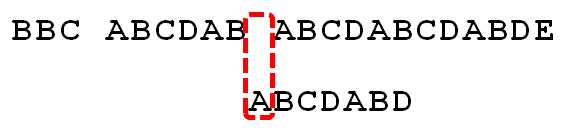
因为空格与A不匹配,继续后移一位。
12.

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。
13.

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。
14.

下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:"前缀"和"后缀"。 "前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。
15.

"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例,
- "A"的前缀和后缀都为空集,共有元素的长度为0;
- "AB"的前缀为[A],后缀为[B],共有元素的长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
16.

"部分匹配"的实质是,有时候,字符串头部和尾部会有重复。比如,"ABCDAB"之中有两个"AB",那么它的"部分匹配值"就是2("AB"的长度)。搜索词移动的时候,第一个"AB"向后移动4位(字符串长度-部分匹配值),就可以来到第二个"AB"的位置。
通过这个例子我们应该可以大概了解到kmp的主要思想了,接下来来进一步实现一下:
如何构造前缀数组?
见下面的例子:该例子来自http://kenby.iteye.com/blog/1025599
#########000xxxx000###### 文本T
|<---- s ---->|000xxxx000~~~ 模式P
#########000xxxx000###### 文本T
|<-------- s+7-------->| 000xxxx000~~~ 模式P
注意到红色部分的字符,即模式P的前10个字符,有一个特点:它的开始3个字符和末尾
3个字符是一样的,又已知文本T也存在红色部分的字符,我们把位移移动 10-3 = 7个位置,让模式P的开始3个字符对准文本
T红色部分的末尾3个字符,那么它们的前3个字符必然可以匹配。
上面的例子是文本T和模式P匹配了前面10个字符的情况下发生的,而且我们观察到模式P的前缀P10中,它的开始3个字符和末尾3个字符是一样的。如果对于模式P的所有前缀P1,P2...Pm,都能求出它们首尾有多少个字符是一样的,当然相同的字
符数越多越好,那么就可以按照上面的方法,进行跳跃式的匹配。
Pi表示模式P的前i个字符组成的前缀, next[i] = j表示Pi中的开始j个字符和末尾j个字符是一样的,而且对于前缀Pi来说,这样
的j是最大值。next[i] = j的另外一个定义是:有一个含有j个字符的串,它既是Pi的真前缀,又是Pi的真后缀
规定:
next[1] = next[0] = 0
next[i]就是前缀数组,下面通过1个例子来看如何构造前缀数组。
例子1:cacca有5个前缀,求出其对应的next数组。
前缀2为ca,显然首尾没有相同的字符,next[2] = 0
前缀3为cac,显然首尾有共同的字符c,故next[3] = 1
前缀4为cacc,首尾有共同的字符c,故next[4] = 1
前缀5为cacca,首尾有共同的字符ca,故next[5] = 2
如果仔细观察,可以发现构造next[i]的时候,可以利用next[i-1]的结果。假设模式已求得next[10] = 3,如下图所示:
000#xxx000 前缀P10
000 末尾3个字符
根据前缀函数的定义:next[10] = 3意味着末尾3个字符和P10的前3个字符是一样的,为求next[11],可以直接比较第4个字符和第11个字符,
如下图所示:蓝色和绿色的#号所示,如果它们相等,则next[11] = next[10]+1 = 4,这是因为next[10] = 3,保证了前缀P11和末尾4个字符的前3个字符是一样的.
000#xxx000# 前缀P11
000# 末尾4个字符
所以只需验证第4个字符和第11个字符。但如果这两个字符不想等呢?那就继续迭代,利用next[next[10] = next[3]的值来求next[11]。
代码如下:
1 int *GetNext(char *str) 2 { 3 int n; 4 n = strlen(str); 5 6 int *pNext = NULL; 7 pNext = (int*)malloc(sizeof(int)*n); 8 9 pNext[0] = 0; 10 11 int i = 1; 12 int j = i-1; 13 while(i < n) 14 { 15 if(str[i] == str[pNext[j]])//next[10] = 3意味着末尾3个字符和P10的前3个字符是一样的 16 //为求next[11],可以直接比较第4个字符和第11个字符 17 //注意next数组含义 18 { 19 pNext[i] = pNext[j]+1; 20 i++; 21 j = i-1; 22 } 23 else if(pNext[j] == 0) 24 { 25 pNext[i] = 0; 26 i++; 27 j = i-1; 28 } 29 else 30 { 31 j = pNext[j]-1; 32 } 33 } 34 return pNext; 35 }
匹配过程:
1 int KMP(char *src,char *match) 2 { 3 if(src == NULL || match == NULL)return -1; 4 5 //获得next数组 6 int *pNext = NULL; 7 pNext = GetNext(match); 8 9 //匹配 10 int i; 11 int j; 12 i = 0; 13 j = 0; 14 15 while(i < strlen(src) && j < strlen(match)) 16 { 17 //二者相等 一起向后移动 18 if(src[i] == match[j]) 19 { 20 i++; 21 j++; 22 } 23 else 24 { 25 //不相等 且匹配串已经走到头的位置 26 if(j == 0) 27 { 28 //主串向后移动 29 i++; 30 } 31 else 32 { 33 //跳转 34 j = pNext[j-1]; 35 } 36 } 37 } 38 39 //匹配串走到末尾 查找成功 40 if(j == strlen(match)) 41 { 42 43 return i - j; 44 } 45 return -1; 46 }
完整代码:
1 #include<stdio.h> 2 #include<stdlib.h> 3 #include<string.h> 4 //求next数组 5 int *GetNext(char *str) 6 { 7 int n; 8 n = strlen(str); 9 10 int *pNext = NULL; 11 pNext = (int*)malloc(sizeof(int)*n); 12 13 pNext[0] = 0; 14 15 int i = 1; 16 int j = i-1; 17 while(i < n) 18 { 19 if(str[i] == str[pNext[j]])//next[10] = 3意味着末尾3个字符和P10的前3个字符是一样的 20 //为求next[11],可以直接比较第4个字符和第11个字符 21 //注意next 22 { 23 pNext[i] = pNext[j]+1; 24 i++; 25 j = i-1; 26 } 27 else if(pNext[j] == 0) 28 { 29 pNext[i] = 0; 30 i++; 31 j = i-1; 32 } 33 else 34 { 35 j = pNext[j]-1; 36 } 37 } 38 return pNext; 39 } 40 int KMP(char *src,char *match) 41 { 42 if(src == NULL || match == NULL)return -1; 43 44 //获得next数组 45 int *pNext = NULL; 46 pNext = GetNext(match); 47 48 //匹配 49 int i; 50 int j; 51 i = 0; 52 j = 0; 53 54 while(i < strlen(src) && j < strlen(match)) 55 { 56 //二者相等 一起向后移动 57 if(src[i] == match[j]) 58 { 59 i++; 60 j++; 61 } 62 else 63 { 64 //不相等 且匹配串已经走到头的位置 65 if(j == 0) 66 { 67 //主串向后移动 68 i++; 69 } 70 else 71 { 72 //跳转 73 j = pNext[j-1]; 74 } 75 } 76 } 77 78 //匹配串走到末尾 查找成功 79 if(j == strlen(match)) 80 { 81 82 return i - j; 83 } 84 return -1; 85 } 86 87 int main() 88 { 89 int n; 90 n = KMP("abcabcdabcabceabcabcdabcabcadshfoiewr","abcabcdabcdsnhfrewroiabca"); 91 printf("%d\n",n); 92 return 0; 93 }
参考资料:
http://kenby.iteye.com/blog/1025599