还是那句老话:十年河东,十年河西,莫欺骚年穷!~_~ 打错个字,应该是莫欺少年穷!
学历代表你的过去,能力代表你的现在,学习代表你的将来。
学无止境,精益求精。
自ASP.NET诞生以来,微软提供了不少控制并发的方法,在了解这些控制并发的方法前,我们先来简单介绍下并发!
并发:同一时间或者同一时刻多个访问者同时访问某一更新操作时,会产生并发!
针对并发的处理,又分为悲观并发处理和乐观并发处理
所谓悲观/乐观并发处理,可以这样理解:
悲观者认为:在程序的运行过程中,并发很容易发生滴,因此,悲观者提出了他们的处理模式:在我执行一个方法时,不允许其他访问者介入这个方法。(悲观者经常认为某件坏事会发生在自己身上)
乐观者认为:在程序的运行过程中,并发是很少发生滴,因此,乐观者提出了他们的处理模式:在我执行一个方法时,允许其他访问者介入这个方法。(乐观者经常认为某件坏事不会发生在自己身上)
那么在C#语言中,那些属于悲观者呢?
在C#中诸如:LOCK、Monitor、Interlocked 等锁定数据的方式,属于悲观并发处理范畴!数据一旦被锁定,其他访问者均无权访问。有兴趣的可以参考:锁、C#中Monitor和Lock以及区别
但是,悲观者处理并发的模式有一个通病,那就是可能会造成非常低下的执行效率。
在此:举个简单例子:
售票系统,小明去买票,要买北京到上海的D110次列车,如果采用悲观者处理并发的模式,那么售票员会将D110次列车的票锁定,然后再作出票操作。但是,在D110次列车车票被锁定期间,售票员去了趟厕所,或者喝了杯咖啡,其他窗口售票员是不能进行售票滴!如果采用这种处理方式的话,中国14亿人口都不用出行了,原因是买不到票 ~_~
因此:在处理数据库并发时,悲观锁还是要谨慎使用!具体还要看数据库并发量大不大,如果比较大,建议使用乐观者处理模式,如果比较小,可以适当采用悲观者处理模式!
OK。说了这么多,也就是做个铺垫,本节内容标题叫数据库并发的解决方案,我们最终还得返璞归真,从数据库并发的解决说起!
那么问题来了?
数据库并发的处理方式有哪些呢?
其实数据库的并发处理也是分为乐观锁和悲观锁,只不过是基于数据库层面而言的!关于数据库层面的并发处理大家可参考我的博客:乐观锁悲观锁应用
悲观锁:假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。[1]
乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。[1] 乐观锁不能解决脏读的问题。
最常用的处理多用户并发访问的方法是加锁。当一个用户锁住数据库中的某个对象时,其他用户就不能再访问该对象。加锁对并发访问的影响体现在锁的粒度上。比如,放在一个表上的锁限制对整个表的并发访问;放在数据页上的锁限制了对整个数据页的访问;放在行上的锁只限制对该行的并发访问。可见行锁粒度最小,并发访问最好,页锁粒度最大,并发访问性能就会越低。
悲观锁:假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。[1] 悲观锁假定其他用户企图访问或者改变你正在访问、更改的对象的概率是很高的,因此在悲观锁的环境中,在你开始改变此对象之前就将该对象锁住,并且直到你提交了所作的更改之后才释放锁。悲观的缺陷是不论是页锁还是行锁,加锁的时间可能会很长,这样可能会长时间的锁定一个对象,限制其他用户的访问,也就是说悲观锁的并发访问性不好。
乐观锁:假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。[1] 乐观锁不能解决脏读的问题。 乐观锁则认为其他用户企图改变你正在更改的对象的概率是很小的,因此乐观锁直到你准备提交所作的更改时才将对象锁住,当你读取以及改变该对象时并不加锁。可见乐观锁加锁的时间要比悲观锁短,乐观锁可以用较大的锁粒度获得较好的并发访问性能。但是如果第二个用户恰好在第一个用户提交更改之前读取了该对象,那么当他完成了自己的更改进行提交时,数据库就会发现该对象已经变化了,这样,第二个用户不得不重新读取该对象并作出更改。这说明在乐观锁环境中,会增加并发用户读取对象的次数。
本篇的主旨是讲解基于C#的数据库并发解决方案(通用版、EF版),因此我们要从C#方面入手,最好是结合一个小项目
项目已为大家准备好了,如下:
首先我们需要创建一个小型数据库:
 View Code
View Code创建的数据库很简单,三张表:商品表,库存表,日志表
有了数据库,我们就创建C#项目,本项目采用C# DataBaseFirst 模式,结构如下:
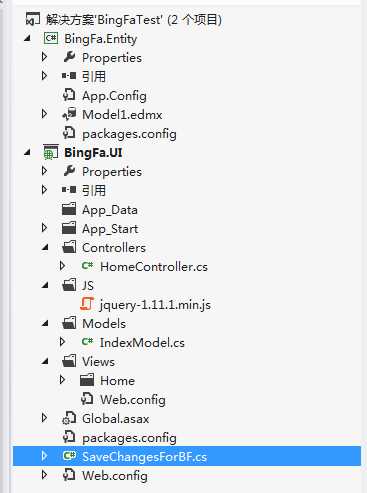
项目很简单,采用EF DataBaseFirst 模式很好构建。
项目构建好了,下面我们模拟并发的发生?
主要代码如下(减少库存、插入日志):

#region 未做并发处理
/// <summary>
/// 模仿一个减少库存操作 不加并发控制
/// </summary>
public void SubMitOrder_3()
{
int productId = 1;
using (BingFaTestEntities context = new BingFaTestEntities())
{
var InventoryLogDbSet = context.InventoryLog;
var InventoryDbSet = context.Inventory;//库存表
using (var Transaction = context.Database.BeginTransaction())
{
//减少库存操作
var Inventory_Mol = InventoryDbSet.Where(A => A.ProductId == productId).FirstOrDefault();//库存对象
Inventory_Mol.ProductCount = Inventory_Mol.ProductCount - 1;
int A4 = context.SaveChanges();
//插入日志
InventoryLog LogModel = new InventoryLog()
{
Title = "插入一条数据,用于计算是否发生并发",
};
InventoryLogDbSet.Add(LogModel);
context.SaveChanges();
//1.5 模拟耗时
Thread.Sleep(500); //消耗半秒钟
Transaction.Commit();
}
}
}
#endregion
此时我们 int productId=1 处加上断点,并运行程序(打开四个浏览器同时执行),如下:
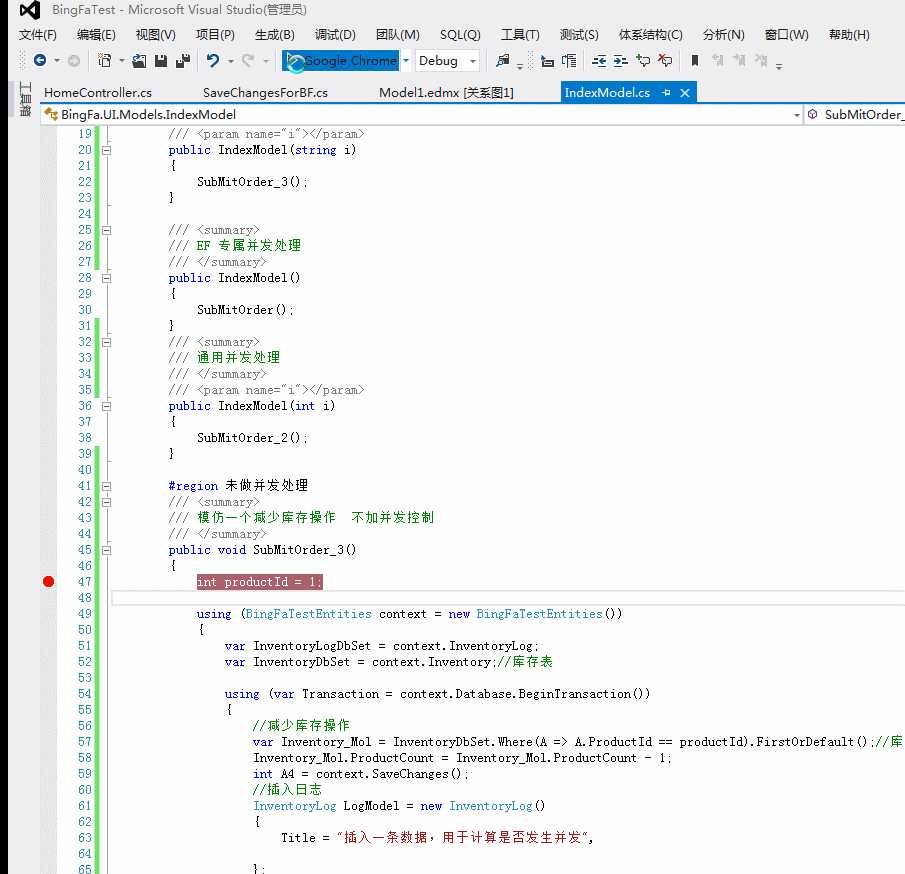
由上图可知,四个访问者同时访问这个未采用并发控制的方法,得到的结果如下:
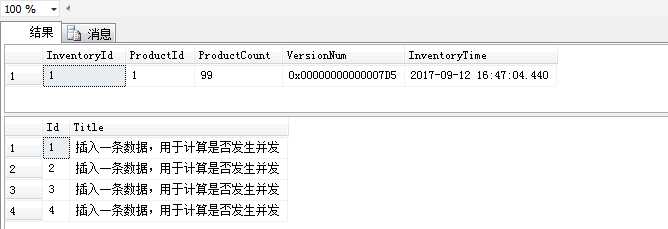
结果显示:日志生成四条数据,而库存量缺只减少1个。这个结果显然是不正确的,原因是因为发生了并发,其本质原因是脏读,误读,不可重读造成的。
那么,问题既然发生了,我们就想办法法解决,办法有两种,分别为:悲观锁方法、乐观锁方法。
悲观者方法:
悲观者方法(加了uodlock锁,锁定了更新操作,也就是说,一旦被锁定,其他访问者不允许访问此操作)类似这种方法,可以通过存储过程实现,在此不作解释了

乐观者方法(通用版/存储过程实现):
在上述数据库脚本中,有字段叫做:VersionNum,类型为:TimeStamp。
字段 VersionNum 大家可以理解为版本号,版本号的作用是一旦有访问者修改数据,版本号的值就会相应发生改变。当然,版本号的同步更改是和数据库相关的,在SQLserver中会随着数据的修改同步更新版本号,但是在MySQL里就不会随着数据的修改而更改。因此,如果你采用的是MYSQL数据库,就需要写一个触发器,如下:
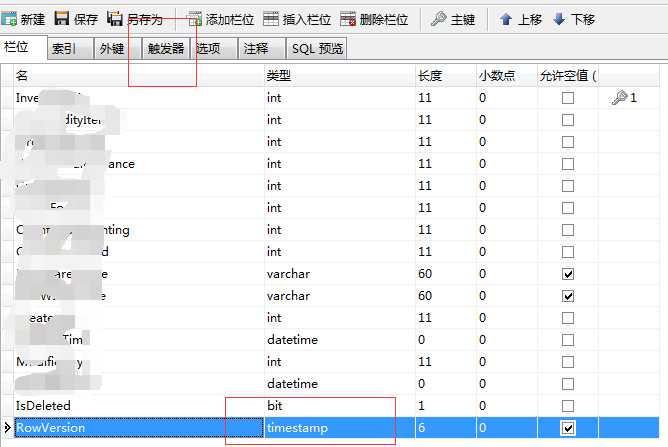

OK,了解了类型为Timestamp的字段,下面我们结合上述的小型数据库创建一个处理并发的存储过程,如下
create proc LockProc --乐观锁控制并发 ( @ProductId int, @IsSuccess bit=0 output ) as declare @count as int declare @flag as TimeStamp declare @rowcount As int begin tran select @count=ProductCount,@flag=VersionNum from Inventory where ProductId=@ProductId update Inventory set ProductCount=@count-1 where VersionNum=@flag and ProductId=@ProductId insert into InventoryLog values(‘插入一条数据,用于计算是否发生并发‘) set @rowcount=@@ROWCOUNT if @rowcount>0 set @IsSuccess=1 else set @IsSuccess=0 commit tran
这个存储过程很简单,执行两个操作:减少库存和插入一条数据。有一个输入参数:productId ,一个输出参数,IsSuccess。如果发生并发,IsSuccess的值为False,如果执行成功,IsSuccess值为True。
在这里,向大家说明一点:程序采用悲观锁,是串行的,采用乐观锁,是并行的。
也就是说:采用悲观锁,一次仅执行一个访问者的请求,待前一个访问者访问完成并释放锁时,下一个访问者会依次进入锁定的程序并执行,直到所有访问者执行结束。因此,悲观锁严格按照次序执行的模式能保证所有访问者执行成功。
采用乐观锁时,访问者是并行执行的,大家同时访问一个方法,只不过同一时刻只会有一个访问者操作成功,其他访问者执行失败。那么,针对这些执行失败的访问者怎么处理呢?直接返回失败信息是不合理的,用户体验不好,因此,需要定制一个规则,让执行失败的访问者重新执行之前的请求即可。
时间有限,就不多写了...因为并发的控制是在数据库端存储过程,所以,C#代码也很简单。如下:
View Code在此,需要说明如下:
当IsSuccess的值为False时,应该重复执行该方法,我定的规则是重复请求十次,这样就很好的解决了直接反馈给用户失败的消息。提高了用户体验。
下面着重说下EF框架如何避免数据库并发,在讲解之前,先允许我引用下别人博客中的几段话:
在软件开发过程中,并发控制是确保及时纠正由并发操作导致的错误的一种机制。从 ADO.NET 到 LINQ to SQL 再到如今的 ADO.NET Entity Framework,.NET 都为并发控制提供好良好的支持方案。
相对于数据库中的并发处理方式,Entity Framework 中的并发处理方式实现了不少的简化。
在System.Data.Metadata.Edm 命名空间中,存在ConcurencyMode 枚举,用于指定概念模型中的属性的并发选项。
ConcurencyMode 有两个成员:
| 成员名称 | 说明 |
| None | 在写入时从不验证此属性。 这是默认的并发模式。 |
| Fixed | 在写入时始终验证此属性。 |
当模型属性为默认值 None 时,系统不会对此模型属性进行检测,当同一个时间对此属性进行修改时,系统会以数据合并方式处理输入的属性值。
当模型属性为Fixed 时,系统会对此模型属性进行检测,当同一个时间对属性进行修改时,系统就会激发OptimisticConcurrencyException 异常。
开发人员可以为对象的每个属性定义不同的 ConcurencyMode 选项,选项可以在*.Edmx找看到:
Edmx文件用记事本打开如下:
View Code其实,在EF DataBaseFirst中,我们只需设置下类型为 TimeStamp 版本号的属性即可,如下:
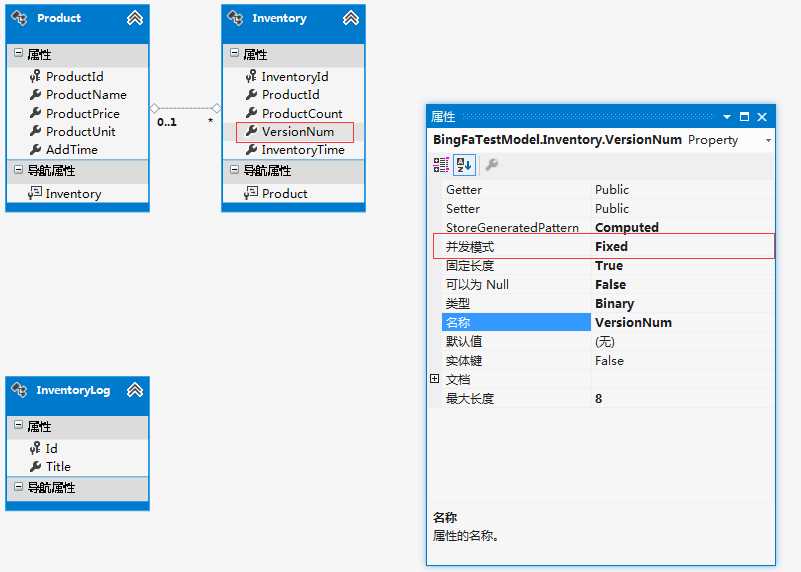
设置好了版本号属性后,你就可以进行并发测试了,当系统发生并发时,程序会抛出异常,而我们要做的就是要捕获这个异常,而后就是按照自己的规则,重复执行请求的方法,直至返回成功为止。
那么如何捕获并发异常呢?
在C#代码中需要使用异常类:DbUpdateConcurrencyException 来捕获,EF中具体用法如下:
public class SaveChangesForBF : BingFaTestEntities
{
public override int SaveChanges()
{
try
{
return base.SaveChanges();
}
catch (DbUpdateConcurrencyException ex)//(OptimisticConcurrencyException)
{
//并发保存错误
return -1;
}
}
}
设置好属性后,EF会帮我们自动检测并发并抛出异常,我们用上述方法捕获异常后,就可以执行我们重复执行的规则了,具体代码如下:
View Code至此,C#并发处理就讲解完了,是不是很简单呢?
项目源码地址:http://download.csdn.net/download/wolongbb/9977216
@陈卧龙的博客