特征:样本的属性。比如:西瓜的颜色、瓜蒂的形状、敲击的声音就是特征
标签:样本的类别。比如:好瓜”和“坏瓜”这两个判断就是标签
一、介绍
KNN分类算法,是理论比较成熟,最简单的机器学习算法之一,既可用于分类,又可应用于回归
核心思想:计算一个样本在特征空间中的k个最相邻的样本,k个样本大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
二、举例说明
如下图所示:
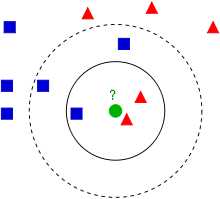
蓝方块和红三角均是已有分类数据,当前的任务是将绿色圆块进行分类判断,判断是属于蓝方块或者红三角。
如果K=3(实线圈),红三角占比2/3,则判断为红三角;
如果K=5(虚线圈),蓝方块占比3/5,则判断为蓝方块。
1. 距离一般使用欧氏距离或曼哈顿距离:

2. 算法执行过程:
1)计算测试样本与各个训练样本之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试样本的预测分类。
三、代码实现
1 #knn-k-最临近算法 2 #inX为待分类向量,dataSet为训练数据集 3 #labels为训练集对应分类,k最邻近算法 4 def classify0(inX, dataSet, labels, k): 5 dataSetSize = dataSet.shape[0]#获得dataSet的行数 6 7 diffMat = np.tile(inX, (dataSetSize,1)) - dataSet#对应的差值 8 sqDiffMat = diffMat**2 #差的平方 9 sqDistances = sqDiffMat.sum(axis=1) #差的平方的和 10 distances = sqDistances**0.5 #差的平方的和的平方根 11 #计算待分类向量与每一个训练数据集的欧氏距离 12 13 sortedDistIndicies = distances.argsort() #排序后,统计前面K个数据的分类情况 14 15 classCount={}#字典 16 for i in range(k): 17 voteIlabel = labels[sortedDistIndicies[i]]#labels得是字典才可以如此 18 classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 19 20 sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)#再次排序 21 22 return sortedClassCount[0][0]#第一个就是最多的类别
四、分析
1.优点:
1) 简单直观,不需要训练(惰性学习(lazy-learning)),也不需要拟合参数。
2.缺点:
1) k值的选取,对算法的结果,影响很大:如果
K值较小,只有与测试样本较近的训练样本才会对预测结果起作用,容易发生过拟合;如果 K 值较大,优点是可以减少学习的估计误差,缺点是学习的近似误差增大,因为与测试样本较远的训练样本也会对预测起作用,使预测发生错误。在实际应用中,K 值一般选择一个较小的数值,通常采用交叉验证的方法来选择最有的 K 值,K通常是不大于20的整数,上限是n的开方。随着训练样本数目趋向于无穷和 K=1 时,误差率不会超过贝叶斯误差率的2倍,如果K也趋向于无穷,则误差率趋向于贝叶斯误差率。
2) 不均匀的分类训练样本可能误差较大:样本不平衡时,如果一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的 K 个邻居中大容量类的样本占多数。
3) 计算量大:每一个测试样本都要遍历一遍训练样本计算距离。也就是说,KNN的时间复杂度为O(n),因此KNN一般适用于样本数较少的数据集。
4) 无法给出所有样本的基础结构信息,即具体确定样最准确的特征