模块加载过程:
路径分析 -> 文件定位 -> 模块编译
Node对引入过的模块都会进行缓存,以减少二次引入时的开销。缓存的是编译和执行之后的对象。require时对缓存中的模块是第一优先级的
路径分析
模块标识符:require的参数,按书写形式可以分成以下几类:
- 核心模块:如http,fs,path
- 文件模块
- 路径模块
- 相对路径模块:.或..开始
- 绝对路径模块:/开始
- 非路径形式的模块
- 路径模块
核心模块
- 在Node.js源代码编译过程中就已经编译成二进制代码,加载速度超快;
- 优先级仅次于缓存,因此与核心模块同标识符的文件模块都不能加载成功。
路径形式的文件模块
- require时才会进行模块编译和执行;
- 会转换为真实路径,并且以真实路径作为索引,将编译执行后的对象放到缓存中。
非路径形式的文件模块
- 从当前模块开始,一直沿路径向上逐级递归,直到根目录,寻找node_modules目录进行文件定位;
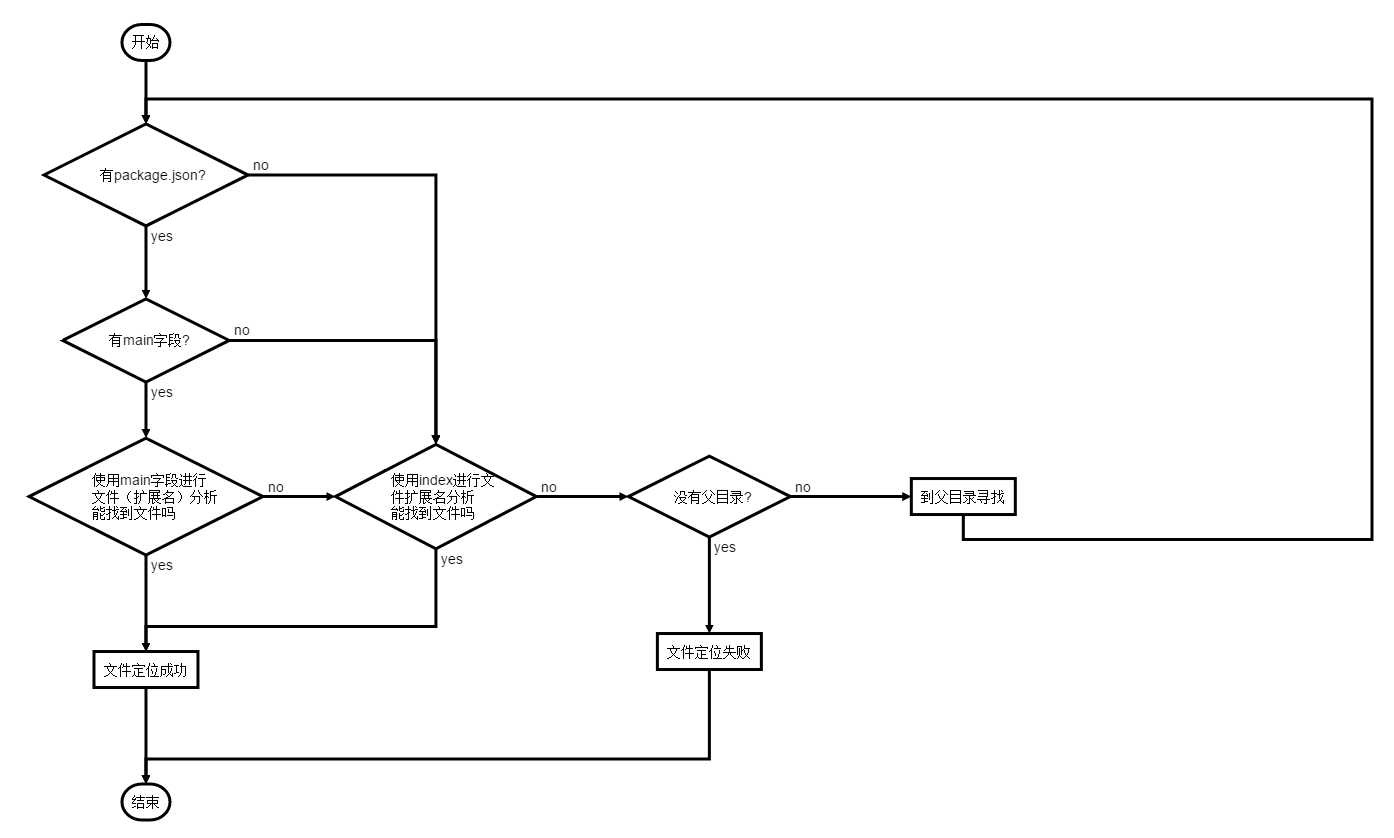
文件定位
分析标识符的过程中,先分析文件扩展名,没有查找到对应的文件,但是得到一个目录,就会将该目录当成一个包来处理。
文件扩展名分析
require时的标识符不需要包含文件扩展名,Node会按.js,.json,.node的次序同步定位。
判断文件是否存在是同步进行的,所以.json和.node在引入时加上扩展名会加快引入速度
目录分析和包
模块编译
文件模块在定位成功后,Node会新建一个Module对象,然后根据路径载入并编译。根据文件的扩展名不同,其载入的方法也不同。
//Module 对象
function Module(id,parent){
this.id = id;
this.exports = {};
this.parent = parent;
updateChildren(parent, this, false);
this.filename = null;
this.loaded = false;
this.children = [];
}可以通过require.extensions知道系统中已有的扩展方式。甚至可以使用require.extensions[‘.ext‘]的形式对.ext扩展名进行自定义加载方式,不过官方不鼓励,建议先编译成JavaScript文件。
.js 文件
通过fs模块同步读取文件后编译执行;
首先会将文件内容进行头尾包装:
(function(exports , require , module , __filename , __dirname){
**JavaScript content**
});这样做可以:
- 在该文件中引入
exports , require , module , __filename , __dirname变量; - 每个模块文件之间都进行了作用域隔离;
包装之后的模块就会交给vm.runInThisContext执行得到一个function(注意是function)。最后将module.exports,require,module以及在文件定位中得到的 __filename 和 __dirname作为参数传递给这个function执行。
所以嘛,在模块内对exports进行赋值:
exports = function(){};是改变了匿名函数的形参的引用,但是实参中无论是module还是module.exports都不能知道被赋值了。
.node
这是用C/C++编写的扩展文件,通过dlopen()方法加载最后编译生成的文件。
.json
通过fs模块同步读取文件后,用JSON.parse()解析返回结果,然后将它赋给模块对象的exports。
每一个编译成功的模块都会将其文件路径作为索引缓存在Module._cache对象上,以提高二次引入的性能。