这次练习爬 传送门 这贴吧里的美食图片。
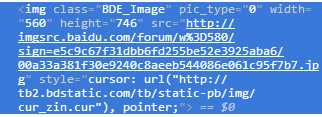
如果通过img标签和class属性的话,用BeautifulSoup能很简单的解决,但是这次用一下正则表达式,我这也是参考了该博主的博文:传送门
所有图片的src地址前面都是相同的,所以根据这个就可以筛选出我们想要的图片了。也就是在匹配时不用class属性的值,而是用正则表达式去匹配src的值。
1 from urllib import request 2 from bs4 import BeautifulSoup 3 import re 4 5 def get_page(url, tot_page): 6 url_list = [] 7 for i in range(1,tot_page): 8 new_url = re.sub((‘=(.*)‘),‘%s%s‘ %(‘=‘,i), url) 9 url_list.append(new_url) 10 return url_list 11 12 13 if __name__ == ‘__main__‘: 14 url = ‘http://tieba.baidu.com/p/4792769205?pn=1‘ 15 path = ‘D:\python\project\爬虫结果‘ 16 count = 0 17 url_list = get_page(url, 4) 18 for url in url_list: 19 print(url) 20 page = request.urlopen(url).read().decode() 21 soup = BeautifulSoup(page, ‘lxml‘) 22 regex = re.compile("http://imgsrc.baidu.com/forum/w%3D580/sign=.+\.jpg") 23 pic_list = soup.findAll(‘img‘, {‘src‘: regex}) 24 for pic in pic_list: 25 pic = pic[‘src‘] 26 request.urlretrieve(pic, ‘%s/%s.jpg‘ % (path, count)) 27 count += 1
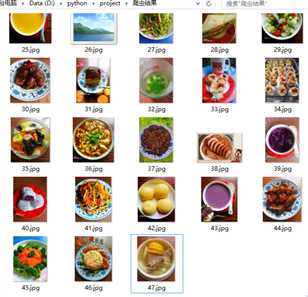
我就爬了3页的图片: