Deep Q-Network和Q-Learning怎么长得这么像,难道它们有关系?
没错,Deep Q-Network其实是Q-Learning融合了神经网络的一种方法
这次我们以打飞机的一个例子来讲解Deep Q-Network,什么打飞机?嘻嘻,我们接着看
简要
Deep Q-Network简称DQN
神经网络有什么作用呢,在Q-Learning中我们使用Q表来记录经验的,通过神经网络我们就不需要Q表了,当我们把状态和动作输入到神经网络中时,经过神经网络的分析等到action,在环境复杂的下我们的机器可能无法承受不住如此庞大的Q表把,所有就需要神经网络这个好帮手了

是不是发现了相似之处,它其实只是在Q-Learning的基础的加了一些小东西,
- 记忆库 (用于重复学习)
- 神经网络计算 Q 值
- 暂时冻结
q_target参数 (切断相关性)
DQN的核心部分就是记忆库,它会记录下所有经历过的步骤,然后反复的进行学习
游戏开始
首先我们先搭建环境,在gym的环境下我们创建一个打飞机的游戏
env=gym.make(‘BeamRider-ram-v0‘)
重磅出击了,接下来是我们的核心部分,DQN的实现
首先我们初始化DQN的参数
def __init__(self): self.ALPHA=0.001 self.GAMMA=0.95 self.ESPLION=1.0 self.ESPLION_DECAY=0.99 self.ESPLION_MIN=0.0001 self.action_size=env.action_space.n self.state_size=env.observation_space.shape[0] self.model=self._build_model() self.memory=deque(maxlen=5000)
童鞋们是不是发现多了两个参数,model和memory,model就是我们的神经网络模型,而memroy没错就是我们的记忆库
我们创建一个简单的神经网络模型,不过这个神经网络模型是空的,用于我们的演示,在这里我用的是kears
def _build_model(self): model=Sequential() model.add(Dense(24, input_dim=self.state_size, activation=‘relu‘)) model.add(Dense(24,activation=‘relu‘)) model.add(Dense(self.action_size,activation=‘linear‘)) model.compile(loss=‘mse‘,optimizer=Adam(lr=self.ALPHA)) return model
经过神经网络我们得到我们下一步的动作
def choose_action(self,obervation): if np.random.uniform()<self.ESPLION: return env.action_space.sample()
#经过神经网络得到action action=self.model.predict(obervation) return np.argmax(action[0])
开始向记忆库中添加我们的经历
def update_memory(self,obervation,action,reward,obervation_,done): self.memory.append((obervation,action,reward,obervation_,done))
这次的训练有所不同,我们是在记忆库中获取一些经验然后进行学习
def learn(self): if len(self.memory)<batch_size: return minibach=random.sample(self.memory,batch_size) for state,action,reward,next_state,done in minibach: target=reward if not done: target=reward+self.GAMMA*np.amax(self.model.predict(next_state)[0]) target_f=self.model.predict(state) target_f[0][action]=target self.model.fit(state,target_f,epochs=1,verbose=0) if self.ESPLION>self.ESPLION_MIN: self.ESPLION*=self.ESPLION_DECAY
为了有一个以后有一个良好的分数,我们不仅要看眼前还要有长远的眼光,这里和Q-learning,Sarsa一样,我在上方用红色标记出来了
我们发现多了两个参数,ESPLION_MIN,ESPLION_DACAY,这个是做什么用的呢,为了让我们的程序不在一直探索我们设置了这两个参数,ESPLION_DECAY用来减少我们的ESPLION值,ESPLION_MIN用来规定我们最少探测的次数,当低于这个后我们遍不再进行DECAY
我们运行这个程序
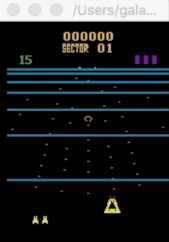
刚开始时我们的战斗机一直阵亡, 渐渐的它学会了击落敌方飞机
经过一段时间的战斗后,战斗机也就越来越厉害了

Double DQN
DQN还有很多变种,其中一种是Double DQN
因为Q-learning中存在Qmax,正是因为Qmax的存在而导致overestimate(过估计),如果DQN发现经过神经网络输出后Q值特被的大,这就是overestimate
这是原本的DQN中的Q实现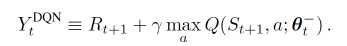
这是Double DQN中的Q实现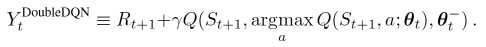
这样我们用Q估计来的动作放在Q实现中来预测出我们要选择的动作这样来防止overestimate
所有在初始化参数时,我们再添加一个具有相同结构的神经网络模型
在使用DQN时我们发现并不是很稳定,使用DDQN时则相对稳定些
game over
以下是所有的代码,小伙伴们可以试一下
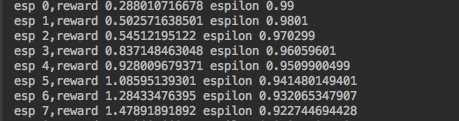
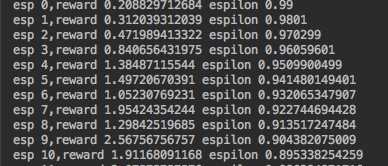
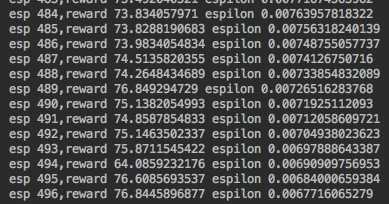
#coding:utf-8 from keras.models import Sequential from keras.layers import Dense from keras.optimizers import Adam from keras.utils import plot_model import numpy as np import gym import random from collections import deque from keras.callbacks import Callback import matplotlib.pyplot as plt batch_size=32 losses=[] class LossHistory(Callback): def on_batch_end(self, batch, logs=None): losses.append(logs.get(‘loss‘)) class Agent(object): def __init__(self): self.ALPHA=0.001 self.GAMMA=0.95 self.ESPLION=1.0 self.ESPLION_DECAY=0.99 self.ESPLION_MIN=0.001 self.action_size=env.action_space.n self.state_size=env.observation_space.shape[0] self.memory=deque(maxlen=5000) self.model=self._build_model() def _build_model(self): model=Sequential() model.add(Dense(24, input_dim=self.state_size, activation=‘relu‘)) model.add(Dense(24,activation=‘relu‘)) model.add(Dense(self.action_size,activation=‘linear‘)) model.compile(loss=‘mse‘,optimizer=Adam(lr=self.ALPHA)) return model def choose_action(self,obervation): if np.random.uniform()<self.ESPLION: return env.action_space.sample() action=self.model.predict(obervation) return np.argmax(action[0]) def update_memory(self,obervation,action,reward,obervation_,done): self.memory.append((obervation,action,reward,obervation_,done)) def plot_model(self): plot_model(self.model, to_file=‘./save_graph/model.png‘) class DDQNAgent(Agent): def __init__(self): super(DDQNAgent,self).__init__() self.target_model=self._build_model() self.update_target_model() def update_target_model(self): self.target_model.set_weights(self.model.get_weights()) def learn(self): if len(self.memory)<batch_size: return minibach=random.sample(self.memory,batch_size) for state,action,reward,next_state,done in minibach: target=self.model.predict(state) if done: target[0][action]=reward else: old_model=self.model.predict(next_state)[0] new_model=self.target_model.predict(next_state)[0] target[0][action]=reward+self.GAMMA*new_model[np.argmax(old_model)] self.model.fit(state,target,epochs=1,verbose=0) if self.ESPLION>self.ESPLION_MIN: self.ESPLION*=self.ESPLION_DECAY class DQNAgent(Agent): def learn(self): if len(self.memory)<batch_size: return minibach=random.sample(self.memory,batch_size) for state,action,reward,next_state,done in minibach: target=reward if not done: target=reward+self.GAMMA*np.amax(self.model.predict(next_state)[0]) target_f=self.model.predict(state) target_f[0][action]=target self.model.fit(state,target_f,epochs=1,verbose=0) if self.ESPLION>self.ESPLION_MIN: self.ESPLION*=self.ESPLION_DECAY history_loss=LossHistory() env=gym.make(‘BeamRider-ram-v0‘) # agent=DQNAgent() agent=DDQNAgent() totcal=0 for e in range(50001): obervation=env.reset() obervation=np.reshape(obervation,[1,agent.state_size]) done=False index=0 while not done: # env.render() action=agent.choose_action(obervation) obervation_,reward,done,info=env.step(action) obervation_= np.reshape(obervation_, [1, agent.state_size]) reward=-10 if done else reward agent.update_memory(obervation,action,reward,obervation_,done) obervation=obervation_ index+=1 totcal+=reward if done: agent.update_target_model() # if len(losses)!=0: # plt.plot(range(len(losses)),losses) # plt.savefig(‘./save_graph/loss.png‘) if e%50==0: agent.model.save(‘./AirRaid_model.h5‘) agent.learn() agent.plot_model() print ‘esp {},reward {} espilon {}‘.format(e,totcal/index,agent.ESPLION)
本篇文章意在带领小伙伴们进入强化学习的殿堂 ^_^