转自:http://www.cnblogs.com/chay1227/archive/2013/03/17/2964020.html
转自:http://blog.csdn.net/allen879/article/details/40461227
转自:http://blog.itpub.net/28912557/viewspace-776770/
由于项目需要,将原来的系统升级需要用到Hbase技术,使用了之后发现,确实很不错。那么问题来了,为什么在这里要用Hbase,而不是以前的关系型数据库Oracle,他们各自有什么特点,应用场景有何不同?带着问题去学习效果会更好。
首先来看关系型数据库与NoSQL的对比:
关系型数据库把所有的数据都通过行和列的二元表现形式表示出来。
关系型数据库的优势:
1. 保持数据的一致性(事务处理)
2.由于以标准化为前提,数据更新的开销很小(相同的字段基本上都只有一处)
3. 可以进行Join等复杂查询
其中能够保持数据的一致性是关系型数据库的最大优势。
关系型数据库的不足:
不擅长的处理
1. 大量数据的写入处理
2. 为有数据更新的表做索引或表结构(schema)变更
3. 字段不固定时应用
4. 对简单查询需要快速返回结果的处理
--大量数据的写入处理
读写集中在一个数据库上让数据库不堪重负,大部分网站已使用主从复制技术实现读写分离,以提高读写性能和读库的可扩展性。
所以在进行大量数据操作时,会使用数据库主从模式。数据的写入由主数据库负责,数据的读入由从数据库负责,可以比较简单地通过增加从数据库来实现规模化,但是数据的写入却完全没有简单的方法来解决规模化问题。
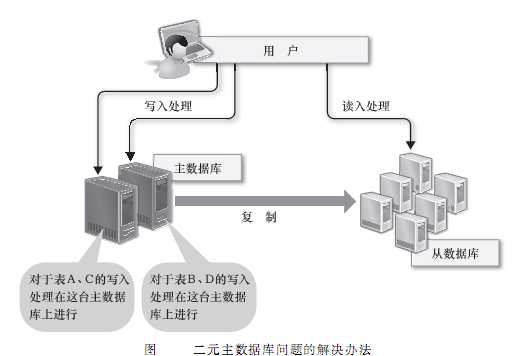
第一,要想将数据的写入规模化,可以考虑把主数据库从一台增加到两台,作为互相关联复制的二元主数据库使用,确实这样可以把每台主数据库的负荷减少一半,但是更新处理会发生冲突,可能会造成数据的不一致,为了避免这样的问题,需要把对每个表的请求分别分配给合适的主数据库来处理。
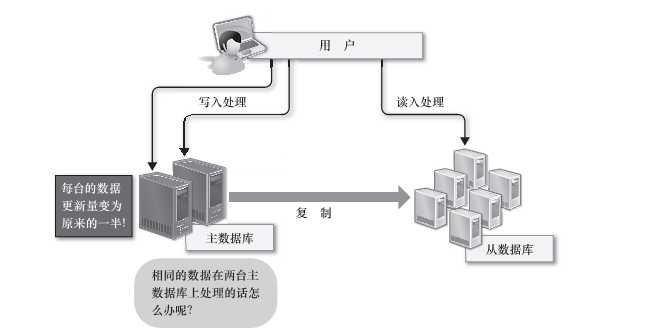
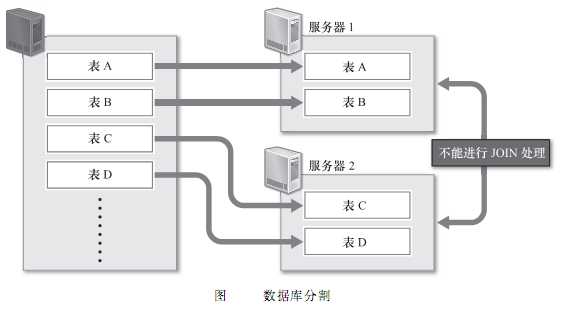
第二,可以考虑把数据库分割开来,分别放在不同的数据库服务器上,比如将不同的表放在不同的数据库服务器上,数据库分割可以减少每台数据库服务器上的数据量,以便减少硬盘IO的输入、输出处理,实现内存上的高速处理。但是由于分别存储字不同服务器上的表之间无法进行Join处理,数据库分割的时候就需要预先考虑这些问题,数据库分割之后,如果一定要进行Join处理,就必须要在程序中进行关联,这是非常困难的。
--为有数据更新的表做索引或表结构变更
在使用关系型数据库时,为了加快查询速度需要创建索引,为了增加必要的字段就一定要改变表结构,为了进行这些处理,需要对表进行共享锁定,这期间数据变更、更新、插入、删除等都是无法进行的。如果需要进行一些耗时操作,例如为数据量比较大的表创建索引或是变更其表结构,就需要特别注意,长时间内数据可能无法进行更新。

--字段不固定时的应用
如果字段不固定,利用关系型数据库也是比较困难的,有人会说,需要的时候加个字段就可以了,这样的方法也不是不可以,但在实际运用中每次都进行反复的表结构变更是非常痛苦的。你也可以预先设定大量的预备字段,但这样的话,时间一长很容易弄不清除字段和数据的对应状态,即哪个字段保存有哪些数据。
--对简单查询需要快速返回结果的处理 (这里的“简单”指的是没有复杂的查询条件)
这一点称不上是缺点,但不管怎样,关系型数据库并不擅长对简单的查询快速返回结果,因为关系型数据库是使用专门的sql语言进行数据读取的,它需要对sql与越南进行解析,同时还有对表的锁定和解锁等这样的额外开销,这里并不是说关系型数据库的速度太慢,而只是想告诉大家若希望对简单查询进行高速处理,则没有必要非使用关系型数据库不可。
---------------------------
NoSQL数据库
关系型数据库应用广泛,能进行事务处理和表连接等复杂查询。相对地,NoSQL数据库只应用在特定领域,基本上不进行复杂的处理,但它恰恰弥补了之前所列举的关系型数据库的不足之处。
优点:
易于数据的分散
各个数据之间存在关联是关系型数据库得名的主要原因,为了进行join处理,关系型数据库不得不把数据存储在同一个服务器内,这不利于数据的分散,这也是关系型数据库并不擅长大数据量的写入处理的原因。相反NoSQL数据库原本就不支持Join处理,各个数据都是独立设计的,很容易把数据分散在多个服务器上,故减少了每个服务器上的数据量,即使要处理大量数据的写入,也变得更加容易,数据的读入操作当然也同样容易。
典型的NoSQL数据库
临时性键值存储(memcached、Redis)、永久性键值存储(ROMA、Redis)、面向文档的数据库(MongoDB、CouchDB)、面向列的数据库(Cassandra、HBase)
一、 键值存储
它的数据是以键值的形式存储的,虽然它的速度非常快,但基本上只能通过键的完全一致查询获取数据,根据数据的保存方式可以分为临时性、永久性和两者兼具 三种。
(1)临时性
所谓临时性就是数据有可能丢失,memcached把所有数据都保存在内存中,这样保存和读取的速度非常快,但是当memcached停止时,数据就不存在了。由于数据保存在内存中,所以无法操作超出内存容量的数据,旧数据会丢失。总结来说:
。在内存中保存数据
。可以进行非常快速的保存和读取处理
。数据有可能丢失
(2)永久性
所谓永久性就是数据不会丢失,这里的键值存储是把数据保存在硬盘上,与临时性比起来,由于必然要发生对硬盘的IO操作,所以性能上还是有差距的,但数据不会丢失是它最大的优势。总结来说:
。在硬盘上保存数据
。可以进行非常快速的保存和读取处理(但无法与memcached相比)
。数据不会丢失
(3) 两者兼备
Redis属于这种类型。Redis有些特殊,临时性和永久性兼具。Redis首先把数据保存在内存中,在满足特定条件(默认是 15分钟一次以上,5分钟内10个以上,1分钟内10000个以上的键发生变更)的时候将数据写入到硬盘中,这样既确保了内存中数据的处理速度,又可以通过写入硬盘来保证数据的永久性,这种类型的数据库特别适合处理数组类型的数据。总结来说:
。同时在内存和硬盘上保存数据
。可以进行非常快速的保存和读取处理
。保存在硬盘上的数据不会消失(可以恢复)
。适合于处理数组类型的数据
二、面向文档的数据库
MongoDB、CouchDB属于这种类型,它们属于NoSQL数据库,但与键值存储相异。
(1)不定义表结构
即使不定义表结构,也可以像定义了表结构一样使用,还省去了变更表结构的麻烦。
(2)可以使用复杂的查询条件
跟键值存储不同的是,面向文档的数据库可以通过复杂的查询条件来获取数据,虽然不具备事务处理和Join这些关系型数据库所具有的处理能力,但初次以外的其他处理基本上都能实现。
三、 面向列的数据库
Cassandra、HBae、HyperTable属于这种类型,由于近年来数据量出现爆发性增长,这种类型的NoSQL数据库尤其引入注目。
普通的关系型数据库都是以行为单位来存储数据的,擅长以行为单位的读入处理,比如特定条件数据的获取。因此,关系型数据库也被成为面向行的数据库。相反,面向列的数据库是以列为单位来存储数据的,擅长以列为单位读入数据。
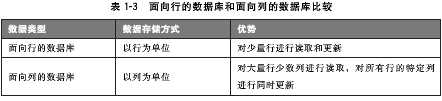
面向列的数据库具有搞扩展性,即使数据增加也不会降低相应的处理速度(特别是写入速度),所以它主要应用于需要处理大量数据的情况。另外,把它作为批处理程序的存储器来对大量数据进行更新也是非常有用的。但由于面向列的数据库跟现行数据库存储的思维方式有很大不同,故应用起来十分困难。
总结:关系型数据库与NoSQL数据库并非对立而是互补的关系,即通常情况下使用关系型数据库,在适合使用NoSQL的时候使用NoSQL数据库,让NoSQL数据库对关系型数据库的不足进行弥补。
1 主要区别
1.1、Hbase适合大量插入同时又有读的情况
1.2、 Hbase的瓶颈是硬盘传输速度,Oracle的瓶颈是硬盘寻道时间。
Hbase本质上只有一种操作,就是插入,其更新操作是插入一个带有新的时间戳的行,而删除是插入一个带有插入标记的行。其主要操作是收集内存中一批数据,然后批量的写入硬盘,所以其写入的速度主要取决于硬盘传输的速度。Oracle则不同,因为他经常要随机读写,这样硬盘磁头需要不断的寻找数据所在,所以瓶颈在于硬盘寻道时间。
1.3、Hbase很适合寻找按照时间排序top n的场景
1.4、索引不同造成行为的差异。
1.5、Oracle 既可以做OLTP又可以做OLAP,但在某种极端的情况下(负荷十分之大),就不适合了。
2 Hbase的局限:
1、只能做简单的Key value查询,复杂的sql统计做不到。
2、只能在row key上做快速查询。
3 传统数据库的行式存储

在数据分析的场景里面,我们经常是以某个列作为查询条件,返回的结果经常也只是某些列,不是全部的列。行式数据库在这种情况下的I/O性能会很差,以Oracle为例,Oracle会有一个很大的数据文件,在这个数据文件中,划分了很多block,然后在每个block中放入行,行是一行一行放进去,挤在一起,然后把block塞满,当然也会预留一些空间,用于将来update。这种结构的缺点是:当我们读某个列的时候,比如我们只需要读红色标记的列的时候,不能只读这部分数据,我必须把整个block读取到内存中,然后再把这些列的数据取出来,换句话说,我为了读表中某些列的数据,我必须把整个列的行读完,才可以读到这些列。如果这些列的数据很少,比如1T的数据中只占了100M, 为了读100M数据却要读取1TB的数据到内存中去,则显然是不划算。
3.1 B+索引
Oracle中采用的数据访问技术主要是B数索引:


从树的跟节点出发,可以找到叶子节点,其记录了key值对应的那行的位置。
对B树的操作:
B树插入——分裂节点
B数删除——合并节点
4 列式存储

同一个列的数据会挤在一起,比如挤在block里,当我需要读某个列的时候,值需要把相关的文件或块读到内存中去,整个列就会被读出来,这样I/O会少很多。
同一个列的数据的格式比较类似,这样可以做大幅度的压缩。这样节省了存储空间,也节省了I/O,因为数据被压缩了,这样读的数据量随之也少了。
行式数据库适合OLTP,反倒列式数据库不适合OLTP。
4.1 BigTable的LSM(Log Struct Merge)索引

在Hbase中日志即数据,数据就是日志,他们是一体化的。为什么这么说了,因为Hbase的更新时插入一行,删除也是插入一行,然后打上删除标记,则不就是日志吗?
在Hbase中,有Memory Store,还有Store File,其实每个Memory Store和每个Store File就是对每个列族附加上一个B+树(有点像Oracle的索引组织表,数据和索引是一体化的), 也就是图的下面是列族,上面是B+树,当进行数据的查询时,首先会在内存中memory store的B+树中查找,如果找不到,再到Store File中去找。
如果找的行的数据分散在好几个列族中,那怎么把行的数据找全呢?那就需要找好几个B+树,这样效率就比较低了。所以尽量让每次insert的一行的列族都是稀疏的,只在某一个列族上有值,其他列族没有值,
一,索引不同造成行为的差异
Hbase只能建立一个主键索引,而且之后的数据查询也只能基于该索引进行简单的key-value查询;
但是Oracle可以建立任意索引,也可以按照任意列进行数据查询。
二,Hbase适合大量插入同时又有读的情况,读一般为key-value查询
大数据、高并发正合Hbase的胃口
三,Hbase的瓶颈是硬盘传输速度,Oracle的瓶颈是硬盘寻道时间
Hbase都是大量往硬盘上写数据(没有delete、update,都是insert),即使是读数据,也是优先MemStore,所以硬盘传输速度成为其瓶颈;
而Oracle由于具有随机访问特性(select、update等),所以硬盘寻道时间成为其瓶颈,而寻道时间主要由转速决定。
四,Hbase很适合寻找按照时间排序top n的场景
因为Hbase的数据都具有时间戳(Hbase默认就有时间戳)
行式存储示意图:
行式存储:
数据存放在数据文件内
数据文件的基本组成单位:块/页(一行接一行存在block中,当然block不会填满,预留空间进行行的操作,譬如:update)
块内结构:块头、数据区
为了select橘红色的列,行式数据库会把整个block加在到内存,然后筛选出所需列。
而对于Hbase而言,由于数据存储特性,数据以列族为单位进行存储,一个文件块存储的都是同一个列族的数据),
这样,查询会比行式数据库优化很多。
另外,由于在Hbase中,同一个列里面数据格式比较接近,或者长度相近,从而可以对数据进行大幅度的压缩,
结果就是节省了硬盘空间,也减少了IO