参考:http://www.cnblogs.com/mikevictor07/p/4458736.html
一、简介
关于一致性哈希算法介绍有许多类似文章,需要把一些理论转为为自己的知识,所以有了这篇文章,本文部分实现也参照了原有的一些方法。该算法在分布缓存的主机选择中很常用,详见http://en.wikipedia.org/wiki/Consistent_hashing 。
二、算法诞生缘由
现在许多大型系统都离不开缓存(K/V)(由于高并发等因素照成的数据库压力(或磁盘IO等)超负荷,需要缓存缓解压力),为了获得良好的水平扩展性,缓存主机互相不通信(如Mencached),通过客户端计算Key而得到数据存放的主机节点,最简单的方式是取模,假如:
----------------------------------------------------------------
现在有3台缓存主机,现在有一个key 为 cks 的数据需要存储:
key = "cks"
hash(key) = 10
10 % 3 = 1 ---> 则代表选择第一台主机存储这个key和对应的value。
缺陷:
假如有一台主机宕机或增加一台主机(必须考虑的情况),取模的算法将导致大量的缓存失效(计算到其他没有缓存该数据的主机),数据库等突然承受巨大负荷,很大可能导致DB服务不可用等。
----------------------------------------------------------------
三、一致性哈希算法原理
该算法需要解决取模方法当增加主机或者宕机时带来的大量缓存抖动问题,要在生产环境中使用,算法需具备以下几个特点:
1. 平衡性 : 指缓存数据尽量平衡分布到所有缓存主机上,有效利用每台主机的空间。
2.
3. 负载均衡 : 每台缓存主机尽量平衡分担压力,即Key的分配比例在这些主机中应趋于平衡。
4.分散性:在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的hash算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
使用场景
现在我们假设有100台redis data服务器,一份数据101进来的时候,以散列公式hash(i)&100,计算所存放的服务器,假设hash(i) = i,那么数据被散列到标号为1的服务器,然后这个时候服务器新增了一台,然后散列公式为hash(i)%101,这个时候请求访问数据101的时候,被分配至0号服务器,但是其实这个时候数据是在1号服务器的。
所以这个时候大量的数据失效了(访问不到了)。
所以这个时候,我们假设是新增了服务器,如果是持久化存储的,我们可以让服务器集群对数据进行重新散列,进行数据迁移,然后进行恢复,但是这个时候就意味着每次增减服务器的时候,集群就需要大量的通信,进行数据迁移,这个开销是非常大的。如果只是缓存,那么缓存就都失效了。所以这个时候怎么办?
我们可以看到,关键问题在于,服务器数量变动的时候,要能够保证旧的数据能够按照老的算法,计算到数据所在的服务器,而新的数据能够按照新的散列算法,计算出数据所在的服务器。
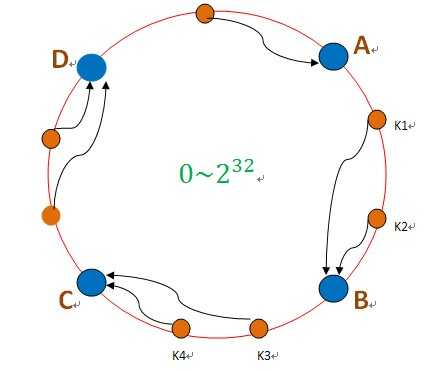
如上图,我们有ABCD四台服务器,这四台服务器被分配至0~232 的一个环上,比如0~230的存储在A服务器,230 +1~231 存储到B服务器上.....CD按照这样的进行均分。将我们的散列空间也划为0~232 ,然后数据进来后对232 取模,得到一个值K1,我们根据K1在环上所处的位置,得到所分配到的服务器,如图,K1被分配到B服务器。 这个时候,我们有一台服务器B失效了。
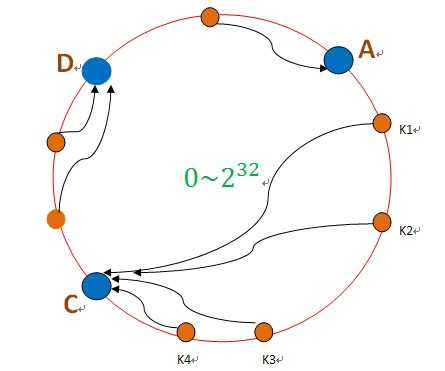
我们可以看到,如果是B失效了,那么如果有持久化存储的,需要做数据恢复,将B的数据迁移至C即可,对于原本散列在A和D的数据,不需要做任何改变。 同理,如果我们是新增了服务器,那么只需要对一台服务器的数据迁移一部分至新加的服务器即可。
一致性hash算法,减少了数据映射关系的变动,不会像hash(i)%N那样带来全局的变动
而且这样还有个好处,假设我们使用UID作为散列范围(即上面的232 ),那么假设有部分UID的访问很频繁,而且这部分UID集中在B服务器上,那么就造成了B的负载远远高于其他服务器。这就是热点数据的问题。这个时候我们可以向B所在的UID空间添加服务器,减少B的压力。
其实还有个更好的解决办法:虚拟节点。
上面说的情况是,使用真实的服务器作为节点散列在232 上。 我们假设,只有4台服务器(如上图),然后A上面有热点数据,结果A挂掉了,然后做数据恢复,A的数据迁移至B,然后B需要承受A+B的数据,也承受不住,也挂了。。。。然后继续CD都挂了。这就造成了
雪崩效应。
上面会造成雪崩效应的原因分析:
如果不存在热点数据的时候,每台机器的承受的压力是M/2(假设每台机器的最高负载能力为M),原本是不会有问题的,但是,这个时候A服务器由于有热点数据挂了,然后A的数据迁移至B,导致B所需要承受的压力变为M(还不考虑热点数据访问的压力),所以这个失败B是必挂的,然后C至少需要承受1.5M的压力。。。。然后大家一起挂。。。
所以我们通过上面可以看到,之所以会大家一起挂,原因在于如果一台机器挂了,那么它的压力全部被分配到一台机器上,导致雪崩。
如果我们A挂了以后,数据被平均分配到BCD上,每台机器多承受M/6的压力,然后大家就都不会挂啦(不考虑热点数据)。
这里引入虚拟节点,如图:
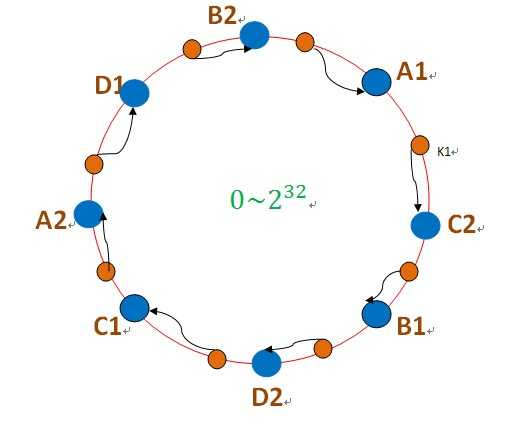
环上的空间被划分为8份,然后A存储A1和A2。。。
这个时候,如果A服务器挂了,访问压力会分配至C2和D1,也就是C和D服务器,而不是像前面,全部被分配到B上。