1:字符串
JS中的任何数据类型都可以当作对象来看。所以string既是基本数据类型,又是对象。
2:声明字符串
基本数据类型:var sStr = ‘字符串’;
对象的方法:var oStr = new String(‘字符串’);


//统计每个字符出现的次数,结果显示 a 2、b 1、c 2、d1,去掉重复的字符,使结果显示 abcdfgj。
//var定义的变量赋值字符串以对象[]的方式访问单个字符IE8以上支持
var str="abcdafgcj";
var arr={};
var newstr="";
for (var i = 0; i < str.length; i++) {
if (arr[str[i]]) {
arr[str[i]]++;
}
else {
arr[str[i]]=1;
}
}
for(newarr in arr){
newstr+=newarr+":"+arr[newarr]+"、";
}
document.write(newstr)
//以string.charAt方式获取字符串对应位置的值兼容低版本浏览器
var str="abcdafgcj";
var arr={};
var newstr="";
for (var i = 0; i < str.length; i++) {
var code=str.charAt(i);
if (arr[code]) {
arr[code]++;
}
else {
arr[code]=1;
}
}
for(newarr in arr){
newstr+=newarr+":"+arr[newarr]+"、";
}
document.write(newstr)
3:字符串属性
1.length: 计算字符串的长度(不区分中英文)。
2.constructor:对象的构造函数。
4:字符串方法
| 序号 | 方法名 | 作用 |
| 1 | myStr.charAt(num) | 返回在指定位置的字符 |
| 2 | myStr.charCodeAt(num) | 返回指定位置的字符的Unicode(是字符编码的一种模式)编码。 |
| 3 | String.fromCharCode() | String的意思就是不能用自己定义的字符串名字来调用,例如定义一个变量字符串 var str="";只能用String来定义调用。接受一个或多个指定的Unicode值,然后返回一个或多个字符串。(把unicode编码转换为字符串)。 |
| 4 | myStr.indexOf() | 返回某个指定的字符串,在字符串中首次出现的位置。如果要检索的字符串值没有出现,则该方法返回 -1。第二个参数指定开始查找的起始位置。 |
| 5 | myStr.lastIndexOf() | 返回一个指定的字符串值最后出现的位置,如果要检索的字符串值没有出现,则该方法返回 -1。第二个参数指定开始查找的起始位置,只能指定正数。 |
| 6 | myStr.match() | 在字符串中检索指定的值,返回的值是数组。如果匹配不到返回null。配合正则来用。 |
| 7 | myStr.search() | 返回出现的位置,查找不到返回-1。配合正则来用。 |
| 8 | myStr.replace(“需替换的字符串”,“替换后的字符串”) | 将字符串中的一些字符替换为另外一些字符。配合正则使用。 |
| 9 | myStr.slice(start,end) | 从指定的开始位置,到结束位置(不包括结束位置)的所有字符串。如果不指定结束位置,则从指定的开始位置,取到结尾。注意的是,myStr.slice() 与 myArr.slice() 相似。 |
| 10 | myStr.substring(start,end) | 从指定的开始位置,到结束位置(不包括)的所有字符串。如果不指定结束位置,则从指定的开始位置,取到结尾。 |
| 11 | substr(start,length) |
从指定的位置开始取指定长度的字符串。如果没有指定长度,从指定开始的位置取到结尾。 ECMAscript 没有对该方法进行标准化,因此反对使用它。 如果substr的start指定为负数,则该参数声明从字符串的尾部开始算起的位置。也就是说,-1 指字符串中最后一个字符,-2 指倒数第二个字符,以此类推。 slice(start,end) vs substring(start,end) :slice参数可以是负数,如果是负数,从-1开始指的是字符串结尾。substring参数是负数的时候,会自动转换为0。 |
| 12 | split("分割位置",[指定的长度]) | 将一个字符串分割成数组。 |
| 13 | toLowerCase() | 用于把字符串转换为小写。 |
| 14 | toUpperCase() | 将字符串转换为大写。 |
5:ASCII码和字符集
ASCII:American Standard Code for Information Interchange,美国信息交换标准代码。
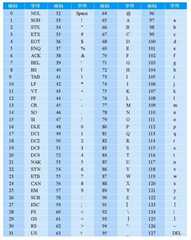
Unicode编码:
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。 Unicode目前普遍采用的是UCS-2,它用两个字节来编码一个字符。
如汉字"经"的编码是0x7ECF,注意字符码一般用十六进制来 表示,为了与十进制区分,十六进制以0x开头,0x7ECF转换成十进制 就是32463,UCS-2用两个字节来编码字符,两个字节就是16位二进制, 2的16次方等于65536,所以UCS-2最多能编码65536个字符。
GBK编码:
GBK全称《汉字内码扩展规范》(GBK即“国标”、“扩展”汉语拼音的第一个字母,英文名称:Chinese Internal Code Specification)。GBK 向下与GB2312编码兼容,向上支持 ISO 10646.1国际标准,是前者向后者过渡过程中的一个承上启下的产物。
UTF-8编码:
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。 UTF-8用1到4个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。