Join节点
JOIN节点有以下三种:
T_NestLoopState,
T_MergeJoinState,
T_HashJoinState,连接类型节点对应于关系代数中的连接操作,PostgreSQL中定义了如下几种连接类型(以T1 JOIN T2 为例):
1)Inner Join:内连接,将T1的所有元组与T2中所有满足连接条件的元组进行连接操作。
2)Left Outer Join:左连接,在内连接的基础上,对于那些找不到可连接T2元组的T1元组,用一个空值元组与之连接。
3)Right Outer Join:右连接,在内连接的基础上,对于那些找不到可连接T1元组的T2元组,用一个空值元组与之连接。
4)Full Outer Join:全外连接,在内连接的基础上,对于那些找不到可连接T2元组的T1元组,以及那些找不到可连接T1元组的T2元组,都要用一个空值元组与之连接。
5)Semi Join:类似IN操作,当T1的一个元组在T2中能够找到一个满足连接条件的元组时,返回该T1元组,但并不与匹配的T2元组连接。
6)Anti Join:类型NOT IN操作,当T1的一个元组在T2中未找到满足连接条件的元组时,返回该T1元组与空元组的连接。
我们再看看postgres用户手册里是怎么说的:
条件连接:
T1 { [INNER] | { LEFT | RIGHT | FULL } [OUTER] } JOIN T2 ON boolean_expression
T1 { [INNER] | { LEFT | RIGHT | FULL } [OUTER] } JOIN T2 USING ( join column list )
T1 NATURAL { [INNER] | { LEFT | RIGHT | FULL } [OUTER] } JOIN T2这样看起来,只有头四种连接方式(INNER, LEFT JOIN, RIGHT JOIN, FULL JOIN)在SQL语句中显示使用了,后两种其实是作为postgres内部使用的,例如Semi Join,我之前说过对于SubqueryScan节点,有可能把ANY和EXIST子句转换为半连接。半连接就是Semi Join。
而对于你所指定的连接方式,PostgreSQL内部会见机行事,使用不同的连接操作。
这里,postgres实现了三种连接操作,分别是:嵌套循环连接(Nest Loop)、归并连接(Merge Join)和Hash连接(Hash Join)。
其中归并连接算法可以实现上述六种连接,而嵌套循环连接和Hash连接只能实现 Inner Join、Left Outer Join、Semi Join 和 AntiJoin四种连接。
如图6-52所示,连接节点有公共父类Join, Join继承了 Plan的所有属性,并扩展定义了 jointype用以存储连接的类型,joinqual用于存储连接的条件。
typedef struct Join
{
Plan plan;
JoinType jointype;
List *joinqual; /* JOIN quals (in addition to plan.qual) */
} Join;对应的执行状态节点JoinState中定义了jointype存储连接类型,joinqual存储连接条件初始化后的状态链表。
typedef struct JoinState
{
PlanState ps;
JoinType jointype;
List *joinqual; /* JOIN quals (in addition to ps.qual) */
} JoinState;1.NestLoop节点
NestLoop节点实现了嵌套循环连接方法,能够进行Inner Join、Left Outer Join、Semi Join和Anti Join四种连接方式。
举例如下:
postgres=# explain select a.*,b.* from test_dm a join test_dm2 b on a.id > b.id;
QUERY PLAN
--------------------------------------------------------------------------------
Nested Loop (cost=0.00..150000503303.17 rows=3333339000000 width=137)
Join Filter: (a.id > b.id)
-> Seq Scan on test_dm2 b (cost=0.00..223457.17 rows=10000017 width=69)
-> Materialize (cost=0.00..27346.00 rows=1000000 width=68)
-> Seq Scan on test_dm a (cost=0.00..22346.00 rows=1000000 width=68)
(5 行)typedef struct NestLoop
{
Join join;
List *nestParams; /* list of NestLoopParam nodes */
} NestLoop;NestLoop节点在Join节点的基础上扩展了nestParams字段,这个字段nestParams是一些执行器参数的列表,这些参数的用处是将外部子计划的当前行执行值传递到内部子计划中。目前主要的传递形式是Var型,这个数据结构的定义在:
src/include/nodes/primnodes.h
Var - expression node representing a variable (ie, a table column)下面是状态节点NestLoopState的定义。
typedef struct NestLoopState
{
JoinState js; /* its first field is NodeTag */
bool nl_NeedNewOuter; //true if need new outer tuple on next call
bool nl_MatchedOuter; //true if found a join match for current outer tuple
TupleTableSlot *nl_NullInnerTupleSlot; //prepared null tuple for left outer joins
} NestLoopState;NestLoop节点的初始化过程(ExecEndNestLoop函数)中初始化NestLoopState节点,构造表达式上下文这些自不必说,还会对节点中连接条件(joinqual字段)进行处理,转化为对应的状态节点JoinState中的joinqual链表。并且对于LEFT JOIN和ANTI JOIN会初始化一个nl_NullInnerTupleSlot。why?
因为对于T1 JOIN T2,当T1的一个元组在T2中未找到满足连接条件的元组时,这两种连接方式会返回该T1元组与空元组的连接,这个空元组就是由nl_NullInnerTupleSlot实现。
最后还将进行如下两个操作:
1)将nl_NeedNewOuter标记为true,表示需要获取左子节点元组。
2)将nl_MatchedOuter标记为false,表示没有找到与当前左子节点元组匹配的右子节点元组。
初始化就是这些。
接下来是NESTLOOP的执行过程(ExecNestLoop函数)。
循环嵌套连接的基本思想如下(以表R(左关系)与表S(右关系)连接为例):
FOR each tuple s in S DO
FOR each tuple r in R DO
IF r and s join to make a tuple t THEN
output t;为了迭代实现此方法,NestLoopState中定义了字段nl_NeedNewOuter和nl_MatchedOuter。当元组处于内层循环时,nl_NeedNewOuter为false,内层循环结束时nl_NeedNewOuter设置为true。为了能够处理Left Outer Join和Anti Join,需要知道内层循环是否找到了满足连接条件的内层元组,此信息由nl_MatchedOuter记录,当内层循环找到符合条件的元组时将其标记为true。
NestLoop执行过程主要是由ExecNestLoop函数来做。该函数主要是一个如上面提到的一个大循环。
该循环执行如下操作:
<1>如果nl_NeedNewOuter为true,则从左子节点获取元组,若获取的元组为NULL则返回空元组并结束执行过程。如果nLNeedNewOuter为false,则继续进行步骤2。
<2>从右子节点获取元组,若为NULL表明内层扫描完成,设置nl_NeedNewOuter为true,跳过步骤3继续循环。
<3>判断右子节点元组是否与当前左子节点元组符合连接条件,若符合则返回连接结果。
以上过程能够完成Inner Join的递归执行过程。但是为了支持其他几种连接则还需要如下两个特殊的处理:
1)当找到符合连接条件的元组后将nl_MatchedOuter标记为true。内层扫描完毕时,通过判断nl_MatchedOuter即可知道是否已经找到满足连接条件的元组,在处理Left Outer Join和Anti Join时需要进行与空元组(nl_NullInnerTupleSlot)的连接,然后将nLMatchedOuter设置为false。
2)当找到满足匹配条件的元组后,对于Semi JOIN和Anti JOIN方法需要设置nl_NeedNewOuter为true。区别在于Anti Join需要不满足连接条件才能返回,所以要跳过返回连接结果继续执行循环。
NestLoop节点的清理过程(ExecEndNestLoop函数)没有特殊处理,只需递归调用左右子节点的清理过程。
2.MergeJoin 节点
Mergejoin实现了对排序关系的归并连接算法,归并连接的输人都是已经排好序的。PostgreSQL中Mergejoin算法实现的伪代码如下:
Join {
get initial outer and inner tuples INITIALIZE
do forever {
while (outer != inner) { SKIP_TEST
if (outer < inner)
advance outer SKIPOUTER_ADVANCE
else
advance inner SKIPINNER_ADVANCE
}
mark inner position SKIP_TEST
do forever {
while (outer == inner) {
join tuples JOINTUPLES
advance inner position NEXTINNER
}
advance outer position NEXTOUTER
if (outer == mark) TESTOUTER
restore inner position to mark TESTOUTER
else
break // return to top of outer loop
}
}
}算法首先初始化左右子节点,然后执行以下操作(其中对于大小的比较都是指对连接属性值的比较):
1)扫描到第一个匹配的位置,如果左子节点(outer)较大,从右子节点(inner)中获取元组;如果右子节点较大,从左子节点中获取元组。
2)标记右子节点当前的位置。
3)循环执行左子节点==右子节点判断,若符合则连接元组,并获取下一条右子节点元组,否则退出循环执行步骤4。
4)获取下一条左子节点元组。
5)如果左子节点==标记处的右子节点(说明该条左子节点与上一条相等),需要将右子节点扫描位置回退到扫描位置,并返冋步骤3;否则跳转到步骤1。
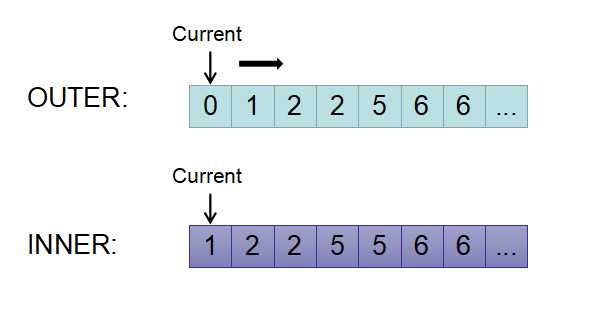
为了说明归并排序的连接算法,我们以Inner Join为例给出部分执行过程,两个current分别指向输人的当前元组,mark用于标记扫描的位置。
1)首先找到左右序列第一个匹配位置,下图中current(outer)=0小于Current(inner),因此outer的current向后移动。
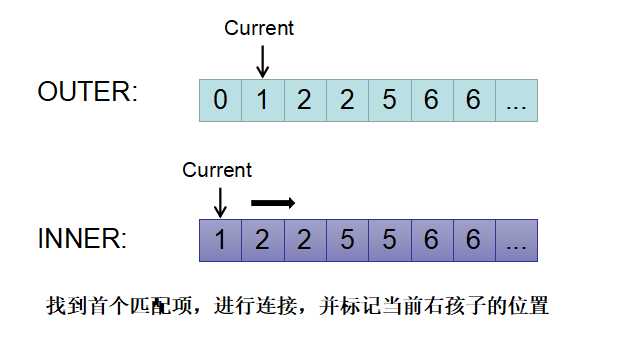
2)如图所示,当找到匹配项后,则进行连接,使用mark标记当前inner的扫描位置,并将inner的current向后移动。
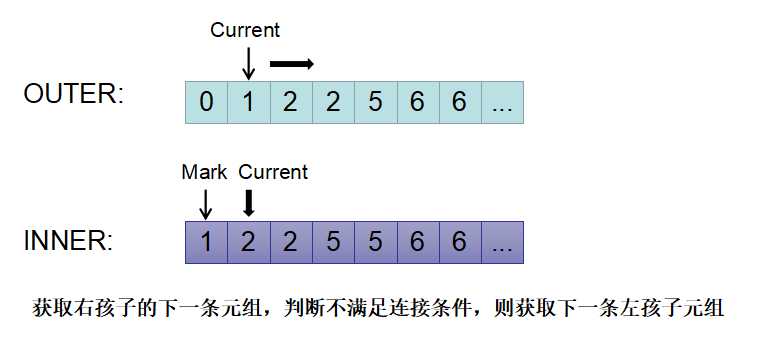
3)接着判断current(outer) = 1小于current(inner) =2,则将outer的current向后移动,并判断outer是否与mark相同(这是为了发现outer的current与前一个相同的情况)。
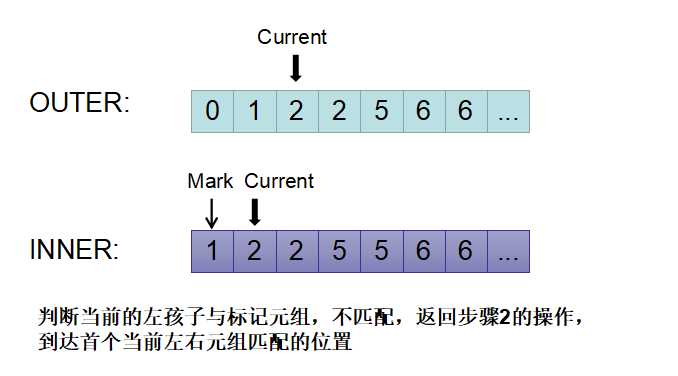
4)下图显示current(outer) =2不等于mark(inner) = 1,则继续扫描过程。
5)判断两个current是否相同,发现Currem(outer)=2等于current(inner)=2,则进行连接,同样标记inner的当前位置,并将inner的cuirent向后移动,如下图所示。其中的current(inner) = 2仍满足连接条件,因此连接完成后inner的current继续向后移动。
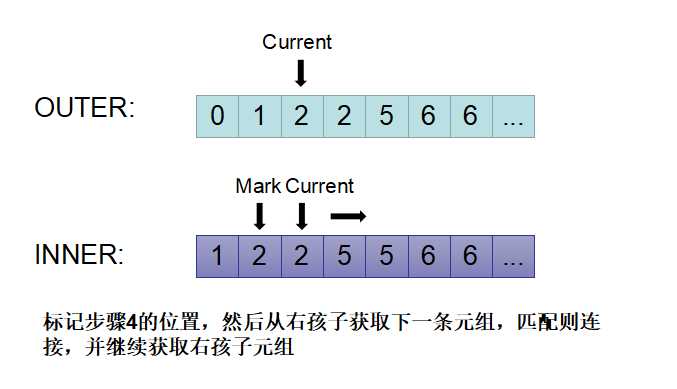
6)如下图所示,current(outer)=2 小于current(inner)=5,则将 outer的current指针向后移动。
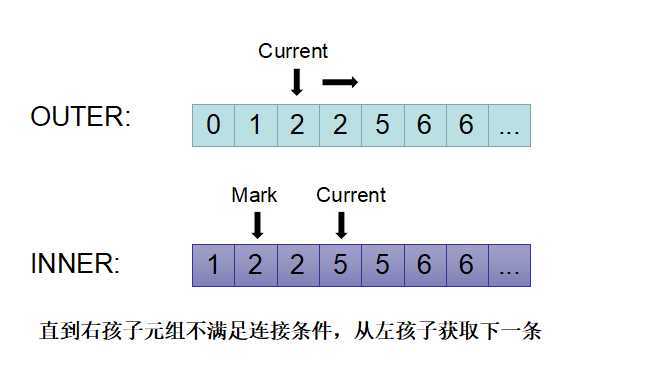
7)此时判断current(outer)和mark(inner)相等,则将inner的current指向mark的位置,重新获取inner的元组进行匹配,如下图所示。
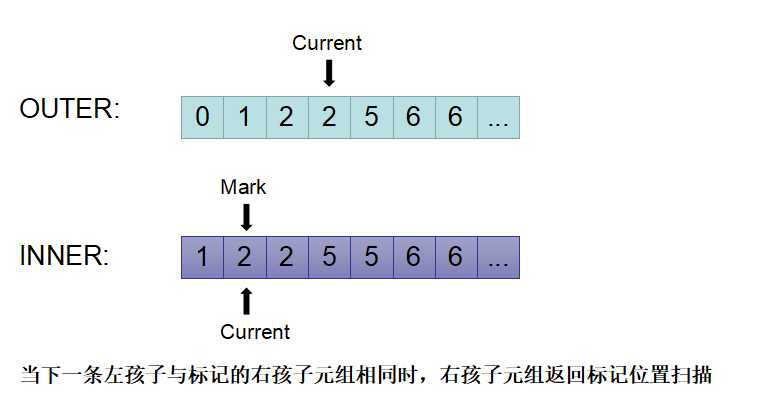
8)不断重复这样的匹配模式,直到inner或outer中的一方被扫描完毕,则表示连接完成。
MergeJoin节点的定义如下:
typedef struct MergeJoin
{
Join join;
List *mergeclauses; /* mergeclauses as expression trees */
/* these are arrays, but have the same length as the mergeclauses list: */
Oid *mergeFamilies; /* per-clause OIDs of btree opfamilies */
Oid *mergeCollations; /* per-clause OIDs of collations */
int *mergeStrategies; /* per-clause ordering (ASC or DESC) */
bool *mergeNullsFirst; /* per-clause nulls ordering */
} MergeJoin;该节点在join的基础上扩展定义了几个mergexxx字段。其中mergeclauses存储用于计算左右子节点元组是否匹配的表达式链表,mergeFamilies、mergeCollations、mergeStrategies、mergeNullsFirst均与表达式链表对应,表明其中每一个操作符的操作符类、执行的策略(ASC或DEC)以及空值排序策略。
在初始化过程中,会使用Mergejoin构造MergeJoinState结构:
typedef struct MergeJoinState
{
JoinState js; /* its first field is NodeTag */
int mj_NumClauses;
MergeJoinClause mj_Clauses; /* array of length mj_NumClauses */
int mj_JoinState;
bool mj_ExtraMarks;
bool mj_ConstFalseJoin;
bool mj_FillOuter;
bool mj_FillInner;
bool mj_MatchedOuter;
bool mj_MatchedInner;
TupleTableSlot *mj_OuterTupleSlot;
TupleTableSlot *mj_InnerTupleSlot;
TupleTableSlot *mj_MarkedTupleSlot;
TupleTableSlot *mj_NullOuterTupleSlot;
TupleTableSlot *mj_NullInnerTupleSlot;
ExprContext *mj_OuterEContext;
ExprContext *mj_InnerEContext;
} MergeJoinState;通过对于连接类型的判断来设置如下几个变量的值:
1)mj_FillOuter:为true表示不能忽略没有匹配项的左子节点元组,需要与空元组进行连接,在 LEFT JOIN、ANTI JOIN 和 FULL JOIN时为true。
2)mj_FillInner:为true表示不能忽略没有匹配项的右子节点元组,需要与空元组进行连接,在 RIGHT JOIN、FULL JOIN 时为 true。
3)mj_InnerTupleSlot:为右子节点元组生成的空元组,在mj_FillOuter为真时构造。
4)mj_OuterTupleSlot:为左子节点元组生成的空元组,在mj_FillInner为真时构造。
除此之外,需要将标记当前左(右)子节点元组是否找到能够连接的元组的变量mj_MatchedOuter(mj_MatchedInner)设置为 false,将存储左(右)子节点元组的字段mj_NullOuterTupleSlot(mj_InnerTupleSlot)设置为 NULL,并为mj_MarkedTupleSlot分配存储空间。
还剩一个hashjoin,我看了半天看不太懂,下篇再说吧~