python字符串包括str 和 unicode,可以通过type(s)确定是str还是unicode
str可以继续细分为各种编码例如utf-8/GBK等
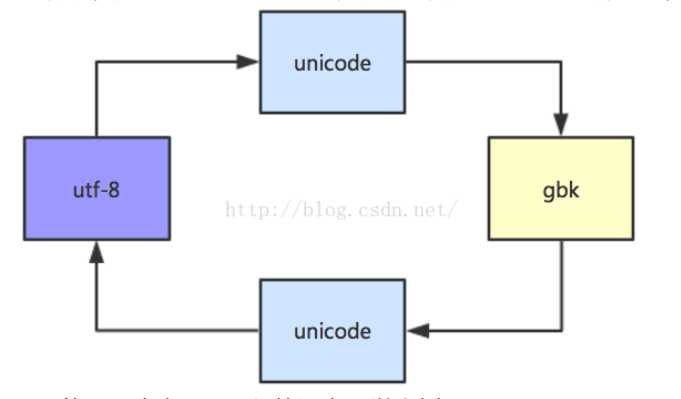
python内部则都通过unicode处理,如下图:
如果是str,可以继续通过chardet.detect(s)确定编码类型
结合type(s),和chardet.detect(s),实验str字符串结果如下:
#coding:utf-8
1)s1 = ‘人生‘ # s1是str,类型是utf-8
2)s1 = ‘人生‘.encode(‘gbk‘) # 报错,原因是python实际执行了s = ‘中文‘.decode(‘asc-ii‘).encode(‘gbk‘),而ascii不支持中文
3)s1 = ‘人生‘.decode(‘utf-8‘).encode(‘utf-8‘) # s1是str,类型是utf-8,转换过程是utf-8、unicode、utf-8
4)s1 = ‘人生‘.decode(‘utf-8‘).encode(‘gbk‘) # s1是str,类型是gbk,转换过程是utf-8、unicode、gbk
5)s1 = u‘人生‘ # s1是unicode
6)s1 = ‘人生‘.decode(‘utf-8‘) # s1是unicode
7)s1 = unicode(‘人生‘ , ‘utf-8‘) # s1是unicode,内部先转成str(‘utf-8‘),再转成unicode,后面的‘utf-8‘改成‘gbk‘也行,如果不写则是通过defaultencoding转换
#coding:utf-8
1)s1 = ‘人生‘ # s1是str,类型是utf-8
2)s1 = ‘人生‘.encode(‘gbk‘) # 报错,原因是python实际执行了s = ‘中文‘.decode(‘asc-ii‘).encode(‘gbk‘),而ascii不支持中文
3)s1 = ‘人生‘.decode(‘utf-8‘).encode(‘utf-8‘) # s1是str,类型是utf-8,转换过程是utf-8、unicode、utf-8
4)s1 = ‘人生‘.decode(‘utf-8‘).encode(‘gbk‘) # s1是str,类型是gbk,转换过程是utf-8、unicode、gbk
5)s1 = u‘人生‘ # s1是unicode
6)s1 = ‘人生‘.decode(‘utf-8‘) # s1是unicode
7)s1 = unicode(‘人生‘ , ‘utf-8‘) # s1是unicode,内部先转成str(‘utf-8‘),再转成unicode,后面的‘utf-8‘改成‘gbk‘也行,如果不写则是通过defaultencoding转换
另外,1和3在pycharm正常打印中文,但是在windows环境下乱码,原因是windows是gbk编码,同理4正好相反,pycharm乱码但是windows正常。5、6、7在两个环境下都能正常打印中文,原因是python unicode会自动转换成环境的编码