搜狗搜索可以直接搜索微信文章,本次就是利用搜狗搜搜出微信文章,获得详细的文章url来得到文章的信息.并把我们感兴趣的内容存入到mongodb中。
因为搜狗搜索微信文章的反爬虫比较强,经常封IP,所以要在封了IP之后切换IP,这里用到github上的一个开源类,当运行这个类时,就会动态的在redis中维护一个ip池,并通过flask映射到网页中,可以通过访问 localhost:5000/get/
来获取IP
这是搜狗微信搜索的页面,

构造搜索url .搜索时会传递的参数,通过firefox浏览器可以查到:
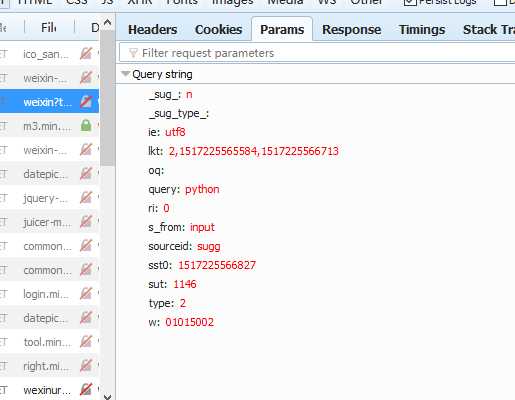
代码如下,
from urllib.parse import urlencode import requests from settings import * from requests.exceptions import ConnectionError from pyquery import PyQuery as pq import pymongo from lxml.etree import XMLSyntaxError class WeixinArticle(object): """ 通过搜狗搜索微信文章,爬取到文章的详细内容,并把我们感兴趣的内容存入到mongodb中 因为搜狗搜索微信文章的反爬虫比较强,经常封IP,所以要在封了IP之后切换IP,这里用到github上的一个开源类, 当运行这个类时,就会动态的redis中维护一个ip池,并通过flask映射到网页中,可以通过访问 localhost:5000/get/ 来获取IP, """ # 定义一个全局变量,这样在各个函数中均可以使用,就不用在传递这个变量 proxy = None def __init__(self): self.keyword = KEYWORD self.proxy_pool_url = PROXY_POOL_URL self.max_count = MAX_COUNT self.mongo_url = MONGO_URL self.mongo_db = MONGO_DB self.base_url = BASE_URL self.headers = HEADERS self.client = pymongo.MongoClient(self.mongo_url) self.db = self.client[self.mongo_db] def get_proxy(url): """获取我们所维护的IP""" try: response = requests.get(url) if response.status_code == 200: return response.text return None except ConnectionError: return self.get_proxy(url) def get_html(url, count=1): """ 通过传的url 获取搜狗微信文章页面信息, :param count: 表示最后递归的次数 :return: 页面的信息 """ if not url: return None if count >= self.max_count: print("try many count ") return None print(‘crowling url ‘, url) print(‘crowling count ‘, count) # 定义一个全局变量,这样在各个函数中均可以使用,就不用在传递这个变量 global proxy try: if proxy: # 如果有代理就用代理去访问 proxy = { "http": "http://" + proxy, } response = requests.get(url=url, allow_redirects=False, headers=self.headers, proxy=proxy) else: # 如果没有代理就不用代理去访问 response = requests.get(url=url, allow_redirects=False, headers=self.headers) if response.status_code == 200: return response.text elif response.status_code == 302: # 如果重定向了,说明我们的IP被ban了,此时就要更换代理 print("status code is 302 ") proxy = self.get_proxy(self.proxy_pool_url) if proxy: print("Useing proxy: ", proxy) return self.get_html(url) else: # 如果我们的代理都获取失败,那这次爬取就完全失败了,此时返回None print("Get proxy failed") return None else: print("Occur Error : ", response.status_code) except ConnectionError as e: #我们只是递归调用max_count 这么多次,防止无限递归 print("Error Occured ", e.args) count += 1 proxy = self.get_proxy(self.proxy_pool_url) return self.get_html(url, count) def get_index(keyword, page): """use urlencode to constract url""" data = { "query": keyword, "type": 2, # "s_from": "input", # "ie": "utf8", "page": page } queries = urlencode(data) url = self.base_url + queries # 为了让程序的的流程更直观,可以不在这里调用 get_html函数,在main函数中调用 # print(url) # html = get_html(url) # return html return url def parse_index_html(html): """解析get_html函数得到的html,即是通过关键字搜索的搜狗页面,解析这个页面得到微信文章的url""" if not html: """如果传进来的html是None,则直接返回""" print("the html is None") return None doc = pq(html) items = doc(".news-list li .txt-box h3 a").items() for item in items: article_url = item.attr("href") yield article_url def get_detail(url): """通过parse_index函数得到微信文章的url,利用requests去得到这个url的网页信息""" try: response = requests.get(url) if response.status_code == 200: return response.text return None except ConnectionError: return None def parse_detail(html): """解析通过get_detail函数得到微信文章url网页信息,得到我们想要的信息""" if not html: return None try: doc = pq(html) title = doc(‘#activity-name‘).text() content = doc(".rich_media_content p span").text() date = doc("#post-date").text() weichat_name = doc("#post-user").text() return { "title": title, "content": content, "date": date, "weichat_name": weichat_name, } except XMLSyntaxError: return None def save_to_mongo(data): """保存到mongodb 中,这里我们希望 title 不重复,所以用update 这种方式进行更新""" if self.db[‘articls‘].update({"title": data["title"]}, {"$set": data}, True): print("save to mongo ") else: print("save to mongo failed ", data["title"]) def main(): """ 爬虫的主要逻辑就在main函数中, 在所有的处理函数中都加了异常处理,和当传入的值是None时的处理,所以在main函数就不用再做处理 """ keyword = self.keyword for page in range(1, 5): url = self.get_index(keyword, page) html = self.get_html(url) article_url = self.parse_index_html(html) article_html = self.get_detail(article_url) article_data = self.parse_detail(article_html) self.save_to_mongo(article_data) def run(self): self.main() if __name__ == "__main__": weixin_article = WeixinArticle() weixin_article.run()
之后,把这们常用的配置写在settings.py,方便程序的修改。
KEYWORD="python" PROXY_POOL_URL="http://127.0.0.1:5000" MAX_COUNT=5 MONGO_URL="localhost" MONGO_DB="weixin" BASE_URL = "http://weixin.sogou.com/weixin?" HEADERS = { # "Accept": "* / *", # "Accept-Encoding": "gzip, deflate", # "Accept-Language": "zh-CN,zh;q=0.9", # "Connection": "keep-alive", "Cookie": "SUID=2FF0747C4990A000000005A45FE0C; SUID=59A4FF3C52110A000000005A45FE0D; weixinIndexVisited=1; SUV=00E75AA0AF9B99675A45FE104A7DA232; CXID=B3DDF3C9EA20CECCB4F94A077C74ED; ad=Xkllllllll0U1lllllVIKlBclllllNllll9lllll9qxlw@@@@@@@@@@@; ABTEST=0|1517209704|v1; SNUID=D8A7384B3C395FD9D44BC22C3DDE2172; JSESSIONID=aaa3zBm9sI7SGeZhCaCew; ppinf=5|1517210191|1518419791|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZToxODolRTYlODElODElRTYlODAlODJ8Y3J0OjEwOjE1MTcyMTAxOTF8cmVmbmljazoxODolRTYlODElODElRTYlODAlODJ8dXNlcmlkOjQ0Om85dDJsdUN1Rm5aVTlaNWYzMGpjNVRDUGN6NW9Ad2VpeGluLnNvaHUuY29tfA; pprdig=m", "Host": "account.sogou.com", "Referer": "http://weixin.sogou.com/weixin?query=python&s_from=input&type=2&page=10&ie=utf8", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36" }
项目目录结构如下:
关于怎么使用redis 维护一个代理池,见