公司有一套Web系统, 使用方反馈系统某些页面访问速度缓慢, 用户体验很差, 并且偶尔还会出现HTTP 502错误。
这是典型的服务器端IO阻塞引发的问题,通过对访问页面的程序逻辑进行跟踪,发现问题应该是出在某个SQL查询上。
在页面程序运行的某个步骤中,有这样一段SQL
select distinct(server) from user_record where type = ‘GD0001‘
user_record表中的数据大概有2000万条左右 , 字段type的值为GD0001的记录大概有500万,而这段SQL执行的结果大概有30多条。type字段上有索引,但是SQL语句的执行时间却要超过一分钟。
得到去重后server字段的值是导致页面访问缓慢的根本原因。
根据程序的要求, server字段的值需要实时求得,所以当初在设计程序的时候才会使用这段SQL去获得结果。数据量少的时候,不会出现问题,然而, 数据增长的速度超出当初的预期,于是就导致了性能问题的出现。
要解决这个问题不难,因为server字段值的范围相对是稳定的,可以想办法把值提取出来放到一个冗余的表里面,并且通过某种机制让这个新表的值与原表中server字段的值保持同步,查的时候查这个新表, 这样访问速度缓慢的问题也就迎刃而解了。
显然,使用这种方案解决问题需要不小的工作量。要使解决这个问题的成本最小化,最好的方法是优化这个查询,假如原本这个查询运行的时间是一分钟,那么能使运行这个查询的时间下降至一秒,问题也算解决。
这个目标看起来似乎难以实现,事实上却是可以做到的。
select distinct(server) from user_record where type = ‘GD0001‘
因为这段SQL语句的筛选条件type字段有索引,所以整个SQL语句的逻辑查询步骤大致如下
-
通过type索引筛选出符合要求记录的主键字段的标识
-
通过主键标识定位到表中记录的源数据
-
拿到字段的值进行distinct去重得到最终的结果。
上面的三个步骤中,最消耗性能的是第二步。因为索引和表的实际数据其实是分开放置的,大概的样子如下面这个图。图中长的最大的那个其实就是数据表,表中所有的数据都在上面,只是看起来不像一张“表”而已。
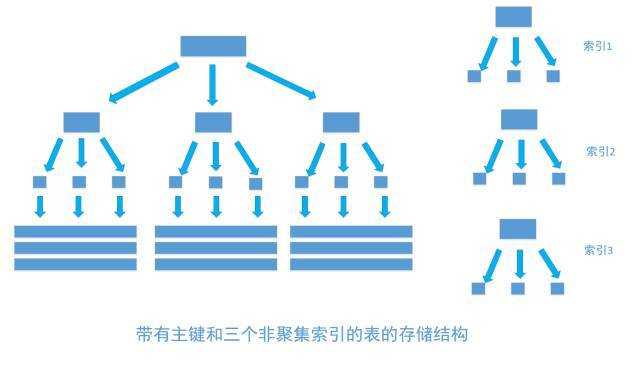
第二步是通过索引筛选出符合条件的记录的主键标识定位到实际数据,过程大概如下面这张图
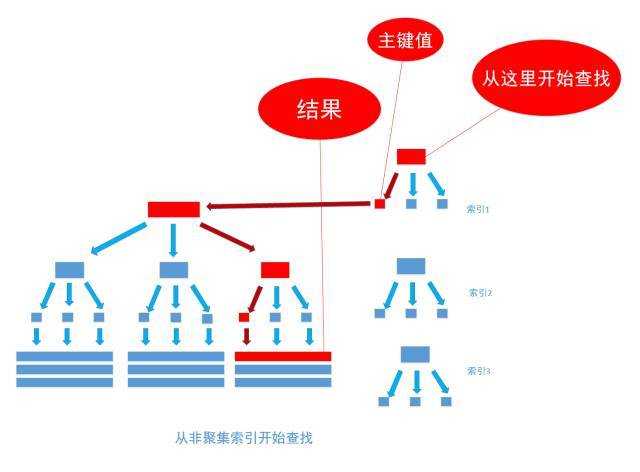
想象一下, 要优化的那段SQL,而type值为GD0001记录有500万条, 就算MySQL不会蠢到去查500万次才能得到结果,但也肯定不是轻轻松松就能完成的。 如果能优化掉这一步,整个查询的开销也就下去了。
select distinct(server) from user_record where type = ‘GD0001‘
对于这段SQL,我们的目标是并不是得到所有字段的值,仅仅server字段的值就足够了。
假如我们把server字段的值放在type字段的索引里,那么在第一步查索引的时候就能得到第二步的结果。执行过程如下图
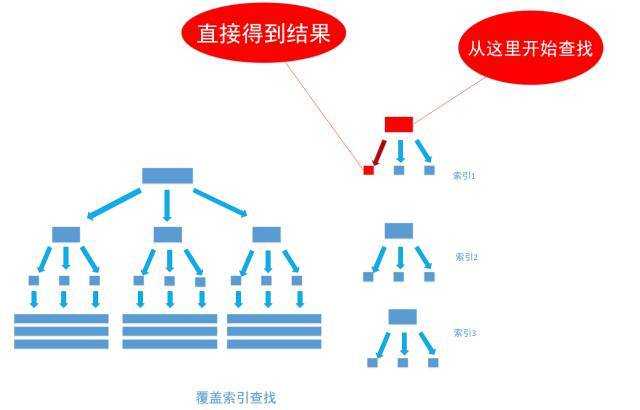
在关系数据库中,有一种索引称为覆盖索引,就是为了满足这种优化需求而设计的。
针对这段SQL语句优化的覆盖索引创建语句如下
create index index_type_server on user_record(type, server)
这个索引创建语句会将type和server两个字段的值组织在一个索引里面, 因此当
select distinct(server) from user_record where type = ‘GD0001‘
所有的查询步骤在索引中就能完成,而不用再去源数据表里提取数据,也就是在没建立这个索引时进行查询的第二步被消除了,因此查询的性能极大幅度的得到了提升。
在没建立覆盖索引前,查询的时间需要一分钟以上,在建立索引后,查询的时间下降到几百毫秒的级别。原本网页加载缓慢和偶尔报HTTP 502错误失去响应的问题也得到了解决。
让SQL语句合理的利用索引快速的得到查询结果是一门学问,值得深究。 合理利用索引,能让对程序性能的优化从代码层面转移到数据库层面, 让问题由最适合解决的工具和手段去解决,物尽其用,如此不但能减少代码复杂度,还能提高解决问题的效率。这是一个程序员必须要具备的一种技能。