实习两个月,小记下自己目前的爬虫技巧
一、爬虫实际上是模仿我们平时登录网站的过程,通俗来讲就是给服务器发送请求,服务器接受请求并进行解析,并给出回应,在页面上就得到你想要的界面了。
二、用到的工具是python2.7以及谷歌浏览器。右键点击“检查”选项,Elements是页面内容,Network是请求内容
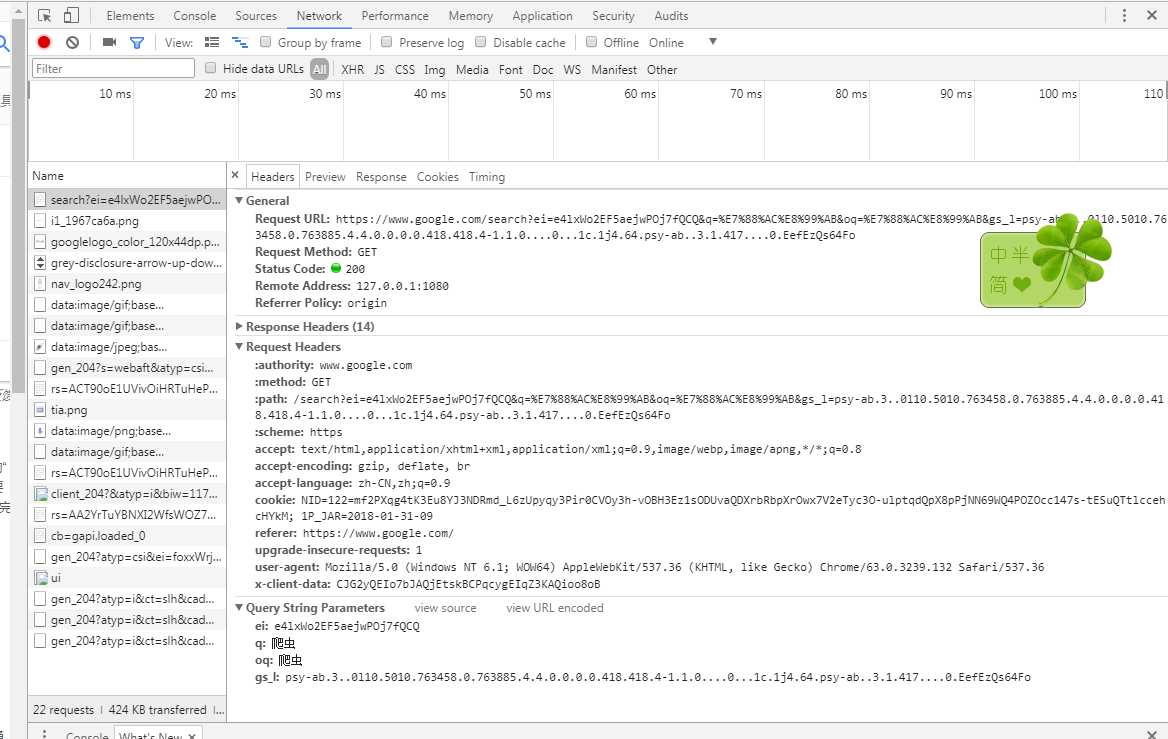
三、用到的是requests这个库,一般用到的是get和post方法,根据网站访问需求而定。传入的参数有url,headers,params,data。其中params和data都是传入的是字典形式的参数,其中params是get方法时,传参到url中用的,data是post方法传参所用的。
headers是请求头部,一般网站访问可能要带cookie,而这就在headers中。这些参数在程序中编写加测试看的有点烦躁,不够直观。在这里介绍下postman这个软件,非常好用。可以粘贴复制参数,进行挑选,能提高效率。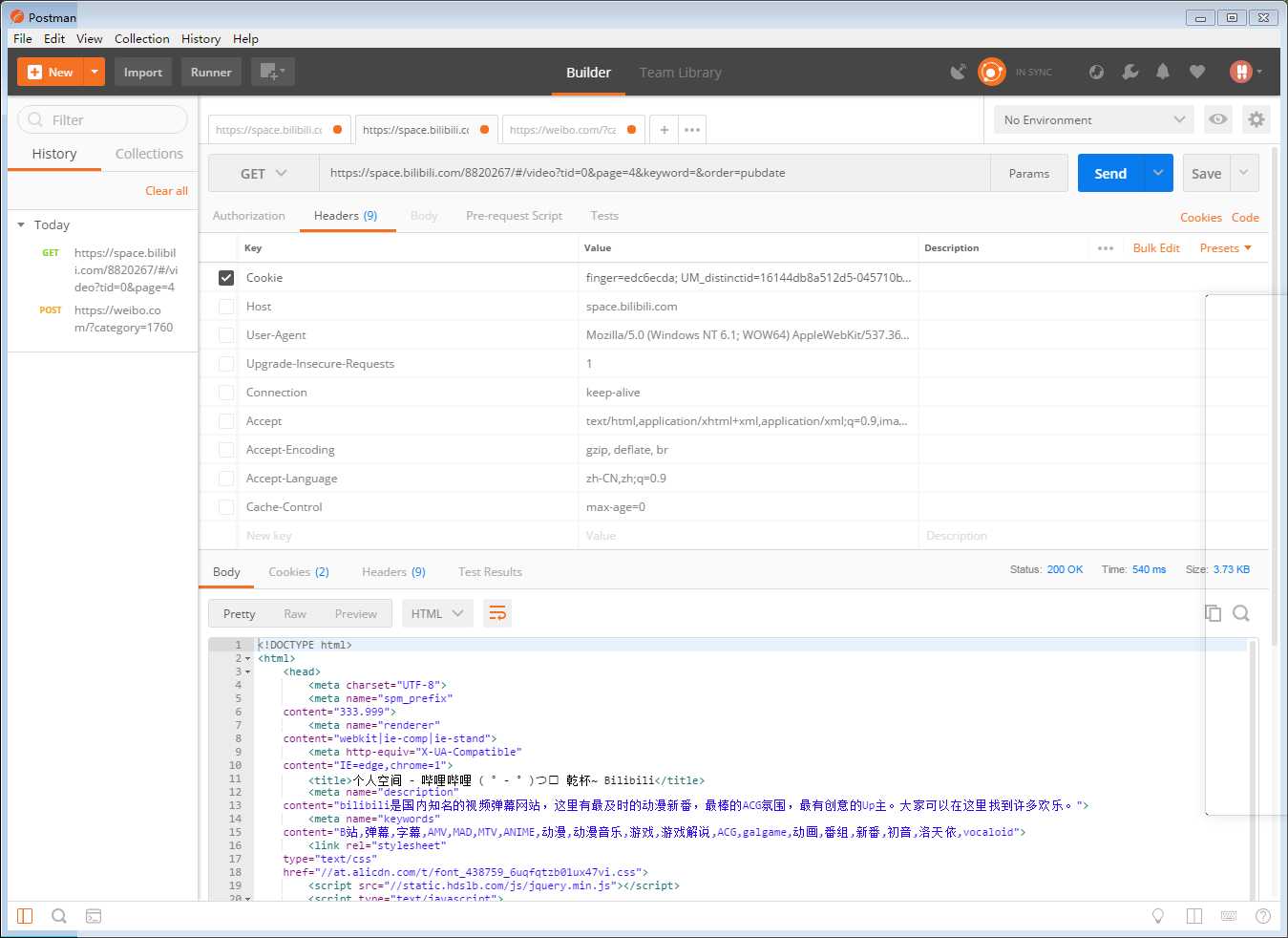
四、接下来是解析得到的页面,有可能一开始出现乱码问题,可以看Element中的head中的“charset”编码方式是什么,得到页面内容后就直接decode("该方式")。解析的工具包有BeautifulSoup和Xpath,BeautifulSoup需要找到class类型以及下面的属性,Google的selector
可能在程序中得不出你想要的东西,需要自己手动去找关系,不过也比较简单。Xpath的话,调用代码是
from lxml impot etree
tree = etree.HTML(text)
#text为网页内容
k = tree.xpath("路径")
推荐google的xpath-helper插件。直接copy xpath内容,得到属性内容,在该语句后面添加/@该属性
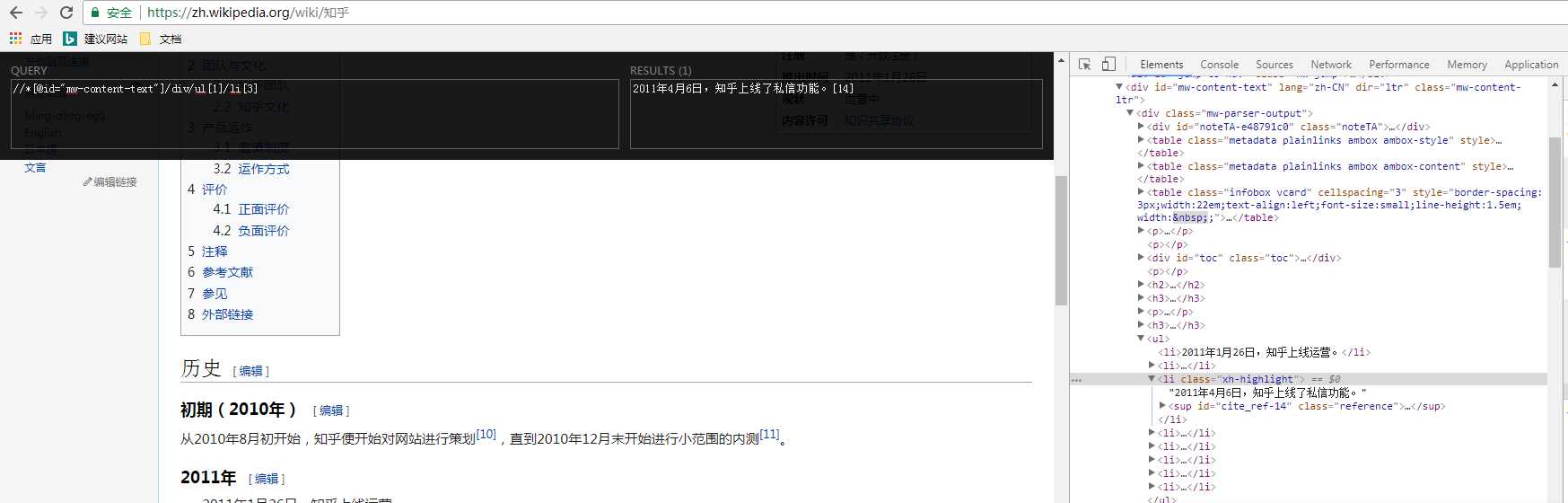
五、举个解析的小例子,爬下b站的视频链接。
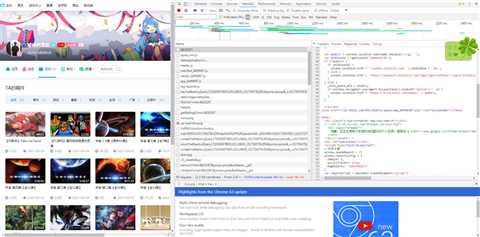
可以发现Reponse中并没有网站信息,网页源码中也没有网站信息。 我们点开带有页面信息的json链接,https://space.bilibili.com/ajax/member/getSubmitVideos?mid=8820267&pagesize=30&tid=0&page=2&keyword=&order=pubdate
此时打开www.json.cn网站在线解析,可以看出字典中的aid跟平时我们看到的视频id很相似, 验证后确实如此,后续只需要循环得到aid,‘https://www.bilibili.com/video/av{0}/‘.format(aid) 就是视频网址了。附上几行小代码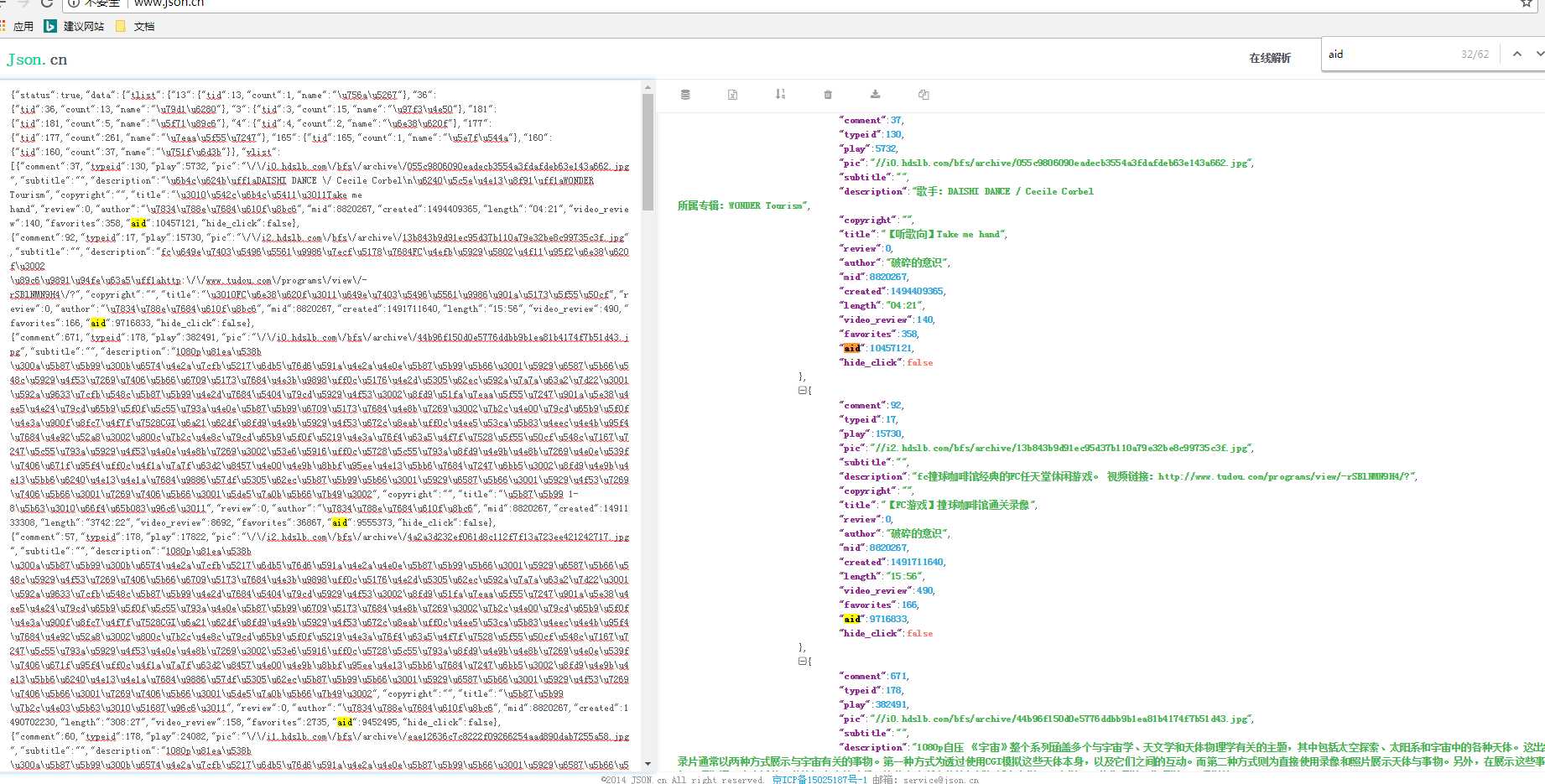
#encoding:utf-8
import sys
reload(sys)
sys.setdefaultencoding(‘utf-8‘)
import json
from http_requests import Response
url_1 = "https://www.bilibili.com/video/av{0}/"
class gethref():
def __init__(self):
self.sess = Response()
def run(self,url):
#url = "https://space.bilibili.com/ajax/member/getSubmitVideos?mid=8820267&pagesize=30&tid=0&page=2&keyword=&order=pubdate"
html = self.sess.get_response(method="get",url = url)
if not html:
html = self.sess.get_response(method="get", url=url)
text = html.content.decode(‘utf-8‘)
text = json.loads(text)
print text
k = text["data"]["vlist"]
for i in k:
id = i["aid"]
with open("bzhan_href.txt","a") as f:
f.writelines(url_1.format(id)+"\n")
app = gethref()
for i in range(1, 13):
url = "https://space.bilibili.com/ajax/member/getSubmitVideos?mid=8820267&pagesize=30&tid=0&page={0}&keyword=&order=pubdate".format(str(i))
app.run(url)
http_requests是用的代理程序,用request也是一样可以的。