在慕课网学习并创建了一个简单的爬虫包,爬取百度百科相关词条信息
程序中会用到第三方解析包(BeautifulSoup4),Windows环境下安装命令:pip install BeautifulSoup4
1、新建包
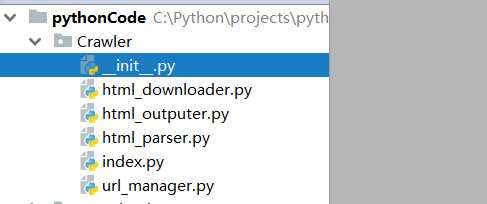
2、新建相关类文件,其中包含有:
index.py,包入口类文件;
url_manager.py,url管理器类文件,主要管理待爬url列表和已爬url列表,避免重复或循环爬取;
html_downloader.py,html内容下载器类文件,下载接收url内容到本地;
html_parser.py,html内容解析器类文件,解析url内容,取出需求数据;
html_outputer.py,爬取内容收集输出器类文件,主要收集各url中需求数据并输出;
3、贴(代码注释好详细的。。。)
index.py
# !/usr/bin/env python
# -*- coding: UTF-8 -*-
# addUser: Gao
# addTime: 2018-01-31 22:22
# description: 入口
from Crawler import url_manager, html_downloader, html_parser, html_outputer
class Index(object):
# 构造函数 初始化各管理器
def __init__(self):
# url管理器
self.urls = url_manager.UrlManager()
# html下载管理器
self.downloader = html_downloader.HtmlDownloader()
# html解析管理器
self.parser = html_parser.HtmlParser()
# 数据收集管理器
self.outputer = html_outputer.HtmlOutputer()
# 爬虫
def craw(self, url):
count = 1
# 将初始地址加入url管理器
self.urls.add_new_url(url)
# 判断是否存在新的url地址 存在时执行爬取程序
while self.urls.has_new_url():
try:
# 获取新的url地址
new_url = self.urls.get_new_url()
print ‘craw %d : %s‘ % (count, new_url)
# 获取url地址内容
html_cont = self.downloader.download(new_url)
# 解析url内容
news_url, new_data = self.parser.parse(new_url, html_cont)
# 将解析得到的url地址列表批量加入url管理器中
self.urls.add_new_urls(news_url)
# 收集数据
self.outputer.collect_data(new_data)
if count == 100:
break
count += 1
# 异常处理
except:
print ‘craw failed‘
# 输出收集的数据
self.outputer.output_html()
if __name__ == ‘__main__‘:
# 初始url地址
initial_url = ‘https://baike.baidu.com/item/%E5%94%90%E8%AF%97%E4%B8%89%E7%99%BE%E9%A6%96/18677‘
# 创建对象
Obj = Index()
# 调用爬虫
Obj.craw(initial_url)
url_manager.py
# !/usr/bin/env python
# -*- coding: UTF-8 -*-
# addUser: Gao
# addTime: 2018-01-31 22:22
# description: url管理器
class UrlManager(object):
# 构造函数 初始化url列表
def __init__(self):
# 待爬url列表
self.new_urls = set()
# 已爬url列表
self.old_urls = set()
# 添加单个url
def add_new_url(self, url):
# 判断url是否为空
if url is None:
return
# 判断url是否已存在或是否已爬
if url not in self.new_urls and url not in self.old_urls:
# 添加到待爬url列表
self.new_urls.add(url)
# 批量添加url
def add_new_urls(self, urls):
# 判断urls是否为空
if urls is None or len(urls)==0:
return
# 循环执行添加单个url
for url in urls:
self.add_new_url(url)
# 判断是否存在新的(未爬取)url
def has_new_url(self):
return len(self.new_urls) != 0
# 获取新的(未爬取)url
def get_new_url(self):
# 取出待爬url列表中的一个url
new_url = self.new_urls.pop()
# 将取出的url添加到已爬url列表中
self.old_urls.add(new_url)
# 返回取出的url
return new_url
html_downloader.py
# !/usr/bin/env python
# -*- coding: UTF-8 -*-
# addUser: Gao
# addTime: 2018-01-31 22:22
# description: html下载器
import urllib2
class HtmlDownloader(object):
# 下载url内容
def download(self, url):
# 判断url是否为空
if url is None:
return None
# 下载url内容
response = urllib2.urlopen(url)
# 判断url地址请求结果
if response.getcode() != 200:
return None
# 返回url加载内容
return response.read()
html_parser.py
# !/usr/bin/env python
# -*- coding: UTF-8 -*-
# addUser: Gao
# addTime: 2018-01-31 22:22
# description: html解析器
import re, urlparse
from bs4 import BeautifulSoup
class HtmlParser(object):
# 解析url的内容
def parse(self, url, html_cont):
# 参数为空判断
if url is None or html_cont is None:
return
# 创建解析对象
soup = BeautifulSoup(html_cont, ‘html.parser‘, from_encoding=‘utf-8‘)
# 获取新的待爬url列表
new_urls = self._get_new_urls(url, soup)
# 获取需求数据
new_data = self._get_new_data(url, soup)
# 返回url列表和数据
return new_urls, new_data
# 获取url内容中的词条url列表
def _get_new_urls(self, url, soup):
# 初始化url列表
new_urls = set()
# 获取页面所有词条a标签列表
links = soup.find_all(‘a‘, href=re.compile(r‘^/item/‘))
for link in links:
new_url = link[‘href‘] # 获取a标签中href属性值
full_url = urlparse.urljoin(url, new_url) # 拼接完整url地址
new_urls.add(full_url) # 将完整的url添加到url列表中
# 返回url列表
return new_urls
# 获取url内容中的需求数据
def _get_new_data(self, url, soup):
# 初始化数据词典
data = {}
title_node = soup.find(‘dd‘, class_=‘lemmaWgt-lemmaTitle-title‘).find(‘h1‘) # 获取标题标签
data[‘title‘] = title_node.get_text() # 获取标题文本
summary_node = soup.find(‘div‘, class_=‘lemma-summary‘) # 获取词条概要标签
data[‘summary‘] = summary_node.get_text() # 获取词条概要文本
data[‘url‘] = url # 词条对应url地址
# 返回数据
return data
html_outputer.py
# !/usr/bin/env python
# -*- coding: UTF-8 -*-
# addUser: Gao
# addTime: 2018-01-31 22:22
# description: html输出器
class HtmlOutputer(object):
# 构造函数 初始化收集的数据
def __init__(self):
self.Data = []
# 收集数据
def collect_data(self, data):
# 数据为空判断
if data is None:
return
# 添加数据到列表
self.Data.append(data)
# 输出收集的数据
def output_html(self):
# 打开文件
out_file = open(‘output.html‘, ‘w‘)
out_file.write(‘<html><body><table>‘)
for data in self.Data:
out_file.write(‘<tr>‘)
out_file.write(‘<td>%s</td>‘ % data[‘title‘].encode(‘utf-8‘))
out_file.write(‘<td>%s</td>‘ % data[‘url‘].encode(‘utf-8‘))
out_file.write(‘<td>%s</td>‘ % data[‘summary‘].encode(‘utf-8‘))
out_file.write(‘</tr>‘)
out_file.write(‘</table></body></html>‘)
# 关闭文件
out_file.close()
4、运行和调用
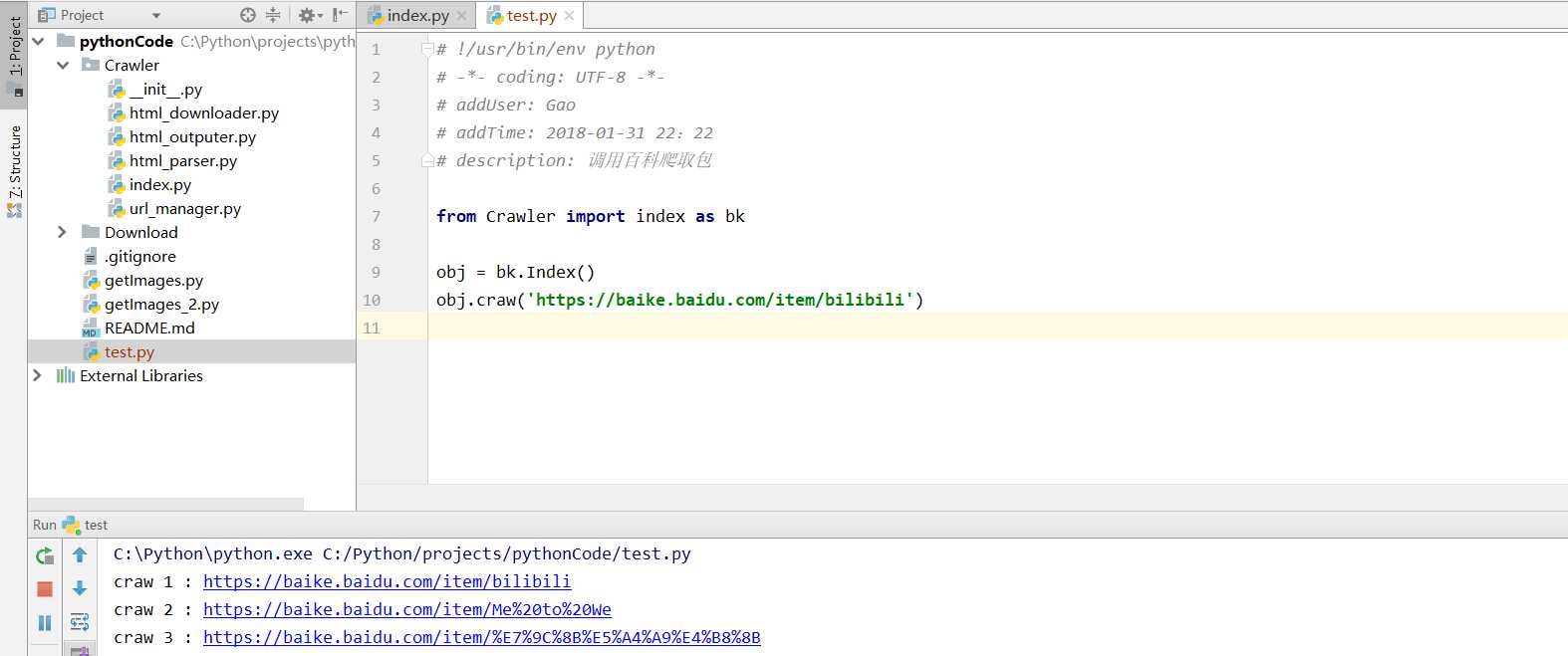
代码撸完了,肯定要看看它是否能使用啦
在包中,选择入口类文件(index.py),右击执行Run命令;
在包外,即调用该爬虫包,首先要引入该包入口类文件(index.py),再实例化对象,最后调用爬取方法,当然还得执行Run命令啦。