第八章 高性能服务器程序框架
我们将服务器一般分为三个主要模块,I/O处理单元、逻辑单元及存储单元。常用的服务器模型有C/S模型和P2P模型,比较简单。我们来看一下网络编程中的I/O模型。首先我们要了解阻塞模型和非阻塞模型的区别,socket在创建时默认是阻塞的,可以在socket系统调用的第二个参数传递SOCK_NONBLOCK标志或者通过fcntl将其设置为非阻塞,针对阻塞I/O的系统调用可能因为无法立即完成而被系统挂起,直到等待的事件发生为止,而非阻塞I/O的系统调用则会立即返回,如果事件没有立即发生,和出错一样会返回-1,此时我们要通过errno来区分,通常来讲,accept、send和recv事件未发生errno被设置成EAGAIN或EWOULDBLOCK,对connect而言,errno则为EINPROGRESS。
而非阻塞I/O通常与其他I/O通知机制一起使用,如I/O复用和SIGIO信号。I/O是最常用的通知机制,应用程序通过I/O复用函数向内核注册一组事件,内核通过I/O复用函数将就绪的事件通知应用程序,常用的有select、poll和epoll,I/O复用函数本身也是阻塞的,其能提高效率的原因在于能同时监听多个I/O事件。我们来比较一下不同的I/O模型
|
I/O模型 |
读写操作和阻塞阶段 |
|
阻塞I/O |
程序阻塞于读写函数 |
|
I/O复用 |
程序阻塞于I/O复用系统调用,但可以监听多个I/O事件,读写本身非阻塞 |
|
SIGIO信号 |
信号触发读写就绪事件,用户程序执行读写操作,程序没有阻塞阶段。 |
|
异步I/O |
内核执行读写操作并触发读写完成事件,程序没有阻塞阶段。 |
服务器程序有两种高效的事件处理模式:通常使用同步I/O的Reactor和通常使用异步I/O的Proactor,但是我们也有用同步I/O实现Proactor的方法。
Reactor要求主线程只负责监听是否有事件发生,如果有就立即将该事件通知工作线程,除此之外不进行任何实质性工作,读写数据,接受新连接,以及处理客户请求都由工作线程完成。也就是说主线程只负责监听和分发事件。以epoll为例,使用同步I/O模型实现Reactor的工作流程是:1)主线程向epoll内核事件表中注册socket上的读就绪事件。2)主线程调用epoll_wait等待socket上有数据可读。3)当socket上有数据可读时,epoll_wait通知主线程,主线程则将socket可读事件放入请求队列。4)睡眠在请求队列上的某个工作线程被唤醒,从socket读取数据,并处理客户请求,然后向epoll内核事件表注册该socket上的写就绪事件。5)主线程调用epoll_wait等待socket可写。6)当socket可写时,epoll_wait通知主线程,主线程将可写事件放入请求队列。7)睡眠在请求队列上的某个工作线程被唤醒,它往socket上写入服务器处理客户请求的结果。
而Proactor不同,它将所有I/O操作都交给主线程和内核来做,工作线程仅仅负责业务逻辑,其使用aio_read等函数的工作流程如下:1)主线程调用aio_read向内核注册socket上的读完成事件,并告诉内核用户读缓冲区的位置,以及读操作完成时如何通知应用程序。2)主线程继续处理其他逻辑。3)当socket上的数据被读入用户缓冲区,内核向应用程序发送一个信号,以通知应用程序。4)应用程序预先定义好的信号处理函数选择一个工作线程处理客户请求,工作线程处理完客户请求后调用aio_write向内核注册写完成时间,并告诉内核用户缓冲区的位置以及如果通知应用程序。5)主线程继续处理其他逻辑。6)当用户缓冲区的数据被写入socket之后,内核将向应用程序发送一个信号,以通知应用程序。7)应用程序预先定义好的信号处理函数选择一个工作线程来做善后处理,比如是否关闭socket。
在这种模式下,主线程调用的epoll_wait只能监听socket上的连接请求,而不能检测连接socket上的读写事件,读写事件是由信号进行通知。
前面说到我们可以用同步I/O来模拟Proactor模式,具体工作流程如下:1)主线程向epoll内核事件表中注册socket上的读就绪事件。2)主线程调用epoll_wait等待socket上有数据可读。3)当socket上有数据可读时,epoll_wait通知主线程,主线程从socket循环队列读取数据直到没有更多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列。4)睡眠在请求队列上的某个工作线程被唤醒,它获得请求对象并处理客户请求,然后往epoll内核事件表中注册socket上的写就绪事件。5)主线程调用epoll_wait等待socket可写。6)当socket可写时,epoll_wait通知主线程,主线程向socket上写入服务器处理客户请求的结果。
我们编程时采用的并发模式主要是为了让程序“同时”执行多个任务,但如果程序是计算密集型,则并发编程并没有优势,反而会因为任务的切换使效率降低,如果程序是I/O密集型,由于I/O的速度远没有CPU的计算速度快,所以并发模式的CPU利用率会显著提高。服务器主要使用的两种并发编程模型是:半同步/半异步模式和领导者/追随者模式。
在半同步/半异步模式中,同步和异步的概念与I/O模型中的同步和异步不同,在I/O模型中,同步和异步主要区分的是内核向应用程序通知的是就绪事件还是完成事件,以及该由应用程序还是内核完成I/O读写。而在并发模式中,同步指的是程序完全按照代码序列的顺序执行,而异步是程序的执行需要由系统事件来驱动,比如中断、信号等。而按照同步方式执行的线程是同步线程,按异步方式执行的线程是异步线程,它们各有优缺点,所以我们采用半同步/半异步模式。其中,同步线程主要用于处理客户逻辑,异步线程用于处理I/O事件,异步线程监听到客户请求就将其封装成请求对象并插入请求队列,请求队列通知某个同步线程来读取或处理该对象。
半同步/半异步模式有几种变形,其中一种是半同步/半反应堆模式,其中,异步线程只有一个,就是主线程,其余工作线程都睡眠在请求队列上,以竞争方式获得任务接管权,所以只有空闲的工作线程才能处理新任务。而其缺点也很明显,首先请求队列是互斥资源,每次访问需要加锁,消耗了CPU时间;其次每个工作线程同一时间只能处理一个客户请求,当客户数量大时只能通过增加工作线程的方式解决问题,而工作线程的切换也将耗费大量CPU时间。
另外一种更为高效的半同步/半异步模式,每个工作线程都能处理多个客户连接,我们考虑一个问题,既然主线程可以用epoll来对多个文件描述符进行监听,那么工作线程呢?所以,每个工作线程都使用epoll_wait监听多个文件描述符,当主线程监听到连接请求,就向它和工作线程的管道中写数据,工作线程检测到管道有数据可读时,就分析是否是一个新客户连接,如果是就将其注册到自己的内核事件表中。
领导者/追随者模式是多个工作线程轮流获得事件源集合,轮流监听、分发并处理时间的一种模式,在这种模式下,没有主线程和工作线程的区分,就好像P2P模式一样,每个工作线程都可以负责监听事件源集合,也可以负责事务逻辑,而半同步/半异步就好像C/S模式一样,主线程是服务器,将工作派发给工作线程。领导者/追随者模式在同一时刻只有一个领导者进程,负责监听I/O事件,而其他进程为追随者,他们处在休眠状态等待成为新的领导者,如果当前领导者监听到了I/O事件,则首先要从线程池中推选出新的领导者线程,然后旧领导者线程去处理I/O事件,新领导者继续监听I/O事件,这样实现了并发。但是很明显,这样做的缺点就是没法像高效的半同步/半异步模式那样一个工作线程处理多个客户连接。领导者/追随者模式包含句柄集、线程集、事件处理器和具体事件处理器。
有限状态机是一种很好的高效编程方法,其概念比较简单,但建模较难,我们以一个HTTP请求的读取和分析程序来分析一下,在服务器读取HTTP请求时,如果没有利用有限状态机,就需要等读取到表示头部结束的空行才能对头部进行解析,但是用有限状态机之后可以一边接受数据一边进行分析,其效率更高。
1 /************************************************************************* 2 > File Name: 8-3.cpp 3 > Author: Torrance_ZHANG 4 > Mail: 597156711@qq.com 5 > Created Time: Sat 03 Feb 2018 01:49:52 AM PST 6 ************************************************************************/ 7 8 #include"head.h" 9 using namespace std; 10 #define BUFFER_SIZE 4096 11 12 //主状态机的两种状态,当前正在分析请求行和正在分析头部字段 13 enum CHECK_STATE{CHECK_STATE_REQUESTLINE = 0, CHECK_STATE_HEADER}; 14 //从状态机的三种可能状态,即行的读取状态:读取到一个完整的行、行出错和行数据暂且不完整 15 enum LINE_STATUS{LINE_OK = 0, LINE_BAD, LINE_OPEN}; 16 17 //服务器处理HTTP请求的结果:NO_REQUEST表示请求不完整,需要读取客户数据; 18 // GET_REQUEST表示获得了一个完整的客户请求; 19 // BAD_REQUEST表示客户请求有语法错误; 20 // FORBIDDEN_REQUEST表示客户对资源没有足够的访问权限 21 // INTERNAL_ERROR表示服务器内部错误; 22 // CLOSED_CONNECTION表示客户端已经关闭连接。 23 enum HTTP_CODE{NO_REQUEST, GET_REQUEST, BAD_REQUEST, FORBIDDEN_REQUEST, INTERNAL_ERROR, CLOSED_CONNECTION}; 24 25 static const char* szret[] = {"I get a correct result\n", "Something wrong\n"}; 26 27 //从状态机,用于解析一行内容 28 LINE_STATUS parse_line(char* buffer, int &checked_index, int &read_index) { 29 //checked_id_index指向buffer的正在分析的字节,read_index指向buffer中的最后一个字节的下一个字节 30 //即从0~checked_index是已分析完毕,checked_index~read_index-1待分析 31 char temp; 32 for(; checked_index < read_index; ++ checked_index) { 33 temp = buffer[checked_index]; 34 //如果当前是回车符,则说明可能读取到了一个完整行 35 //如果是‘\n‘,即换行符,也说明可能读取到了一个完整行 36 if(temp == ‘\r‘) { 37 //如果当前是本行最后一个字符,则说明不完整,需要更多数据 38 //如果下一个字符是‘\n‘则说明读取到了完整的行 39 //否则说明HTTP请求存在语法问题 40 if(checked_index + 1 == read_index) { 41 return LINE_OPEN; 42 } 43 else if(buffer[checked_index + 1] == ‘\n‘) { 44 buffer[checked_index ++] = ‘\0‘; 45 buffer[checked_index ++] = ‘\0‘; 46 return LINE_OK; 47 } 48 else return LINE_BAD; 49 } 50 else if(temp == ‘\n‘) { 51 if((checked_index > 1) && (buffer[checked_index - 1] == ‘\r‘)) { 52 buffer[checked_index - 1] = ‘\0‘; 53 buffer[checked_index ++] = ‘\0‘; 54 return LINE_OK; 55 } 56 return LINE_BAD; 57 } 58 } 59 //如果到最后也没有发现‘\r‘字符,则返回LINE_OPEN表示需要读取更多数据分析 60 return LINE_OPEN; 61 } 62 63 //分析请求行 64 HTTP_CODE parse_requestline(char* temp, CHECK_STATE& checkstate) { 65 //如果请求行中没有空格和‘\t‘字符则说明HTTP请求有问题 66 //strpbrk返回前面缓冲区第一个在后面字符集合中的字符位置 67 char* url = strpbrk(temp, " \t"); 68 if(!url) return BAD_REQUEST; 69 *url ++ = ‘\0‘; 70 71 //strcasecmp与strcmp的区别就是不区分大小写 72 char* method = temp; 73 if(strcasecmp(method, "GET") == 0) printf("The request method is GET\n"); 74 else return BAD_REQUEST; 75 76 //strspn函数统计缓冲区前面多少个连续字符在字符集合中 77 url += strspn(url, "\t"); 78 char *version = strpbrk(url, " \t"); 79 if(!version) return BAD_REQUEST; 80 81 *version ++ = ‘\0‘; 82 version += strspn(version, " \t"); 83 84 //strchr函数返回缓冲区里第一个后面字符的位置 85 if(strcasecmp(version, "HTTP/1.1") != 0) { 86 url += 7; 87 url = strchr(url, ‘/‘); 88 } 89 90 if(!url || url[0] != ‘/‘) return BAD_REQUEST; 91 printf("The request URL is: %s\n", url); 92 checkstate = CHECK_STATE_HEADER; 93 return NO_REQUEST; 94 } 95 96 //分析头部 97 HTTP_CODE parse_headers(char* temp) { 98 //遇到空行说明得到了一个正确的HTTP请求 99 if(temp[0] == ‘\0‘) return GET_REQUEST; 100 else if(strncasecmp(temp, "Host:", 5) == 0) { 101 temp += 5; 102 temp += strspn(temp, " \t"); 103 printf("The request host is: %s\n", temp); 104 } 105 else printf("I can not handle this header\n"); 106 return NO_REQUEST; 107 } 108 109 //分析HTTP请求的入口函数 110 HTTP_CODE parse_content(char* buffer, int& checked_index, CHECK_STATE& checkstate, int& read_index, int &start_line) { 111 LINE_STATUS linestatus = LINE_OK; 112 HTTP_CODE retcode = NO_REQUEST; 113 while((linestatus = parse_line(buffer, checked_index, read_index)) == LINE_OK) { 114 char* temp = buffer + start_line; 115 start_line = checked_index; 116 switch(checkstate) { 117 case CHECK_STATE_REQUESTLINE: { 118 retcode = parse_requestline(temp, checkstate); 119 if(retcode == BAD_REQUEST) return BAD_REQUEST; 120 break; 121 } 122 case CHECK_STATE_HEADER: { 123 retcode = parse_headers(temp); 124 if(retcode == BAD_REQUEST) return BAD_REQUEST; 125 else if(retcode == GET_REQUEST) return GET_REQUEST; 126 break; 127 } 128 default: { 129 return INTERNAL_ERROR; 130 } 131 } 132 } 133 if(linestatus == LINE_OPEN) return NO_REQUEST; 134 else return BAD_REQUEST; 135 } 136 137 int main(int argc, char** argv) { 138 if(argc <= 2) { 139 printf("usage: %s ip_address port_number\n", basename(argv[0])); 140 return 1; 141 } 142 const char* ip = argv[1]; 143 int port = atoi(argv[2]); 144 struct sockaddr_in address; 145 bzero(&address, sizeof(address)); 146 address.sin_family = AF_INET; 147 address.sin_port = htons(port); 148 inet_pton(AF_INET, ip, &address.sin_addr); 149 150 int listenfd = socket(AF_INET, SOCK_STREAM, 0); 151 assert(listenfd >= 0); 152 153 int reuse = 1; 154 int ret = setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof(reuse)); 155 156 ret = bind(listenfd, (struct sockaddr*)&address, sizeof(address)); 157 assert(ret != -1); 158 159 ret = listen(listenfd, 5); 160 assert(ret != -1); 161 162 struct sockaddr_in client_address; 163 socklen_t client_addrlength = sizeof(client_address); 164 int fd = accept(listenfd, (struct sockaddr*)&client_address, &client_addrlength); 165 if(fd < 0) printf("errno is: %d\n", errno); 166 else { 167 char buffer[BUFFER_SIZE]; 168 memset(buffer, 0, sizeof(buffer)); 169 //下面的变量分别代表已经接收的字符数、已经读取了多少字节、已经分析完了多少字节、行在buffer中的起始位置 170 int data_read = 0; 171 int read_index = 0; 172 int checked_index = 0; 173 int start_line = 0; 174 CHECK_STATE checkstate = CHECK_STATE_REQUESTLINE; 175 while(1) { 176 data_read = recv(fd, buffer + read_index, BUFFER_SIZE - read_index, 0); 177 if(data_read == -1) { 178 printf("reading failed\n"); 179 break; 180 } 181 else if(data_read == 0) { 182 printf("remote client has closed the connection\n"); 183 break; 184 } 185 read_index += data_read; 186 HTTP_CODE result = parse_content(buffer, checked_index, checkstate, read_index, start_line); 187 if(result == NO_REQUEST) continue; 188 else if(result == GET_REQUEST) { 189 send(fd, szret[0], strlen(szret[0]), 0); 190 break; 191 } 192 else { 193 send(fd, szret[1], strlen(szret[1]), 0); 194 break; 195 } 196 } 197 close(fd); 198 } 199 close(listenfd); 200 return 0; 201 }
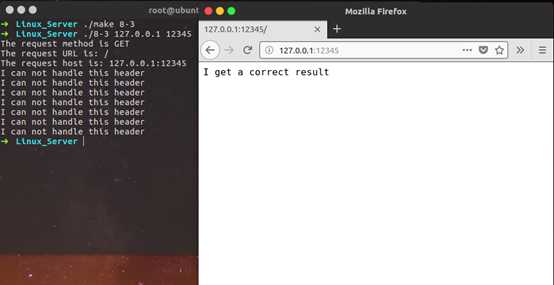
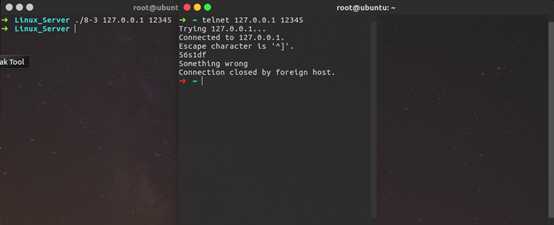
我们模拟了正确的请求报文和错误的请求报文两种情况,发现其正常工作。分析一下发现,这里面存在着两个有限状态机,分别是主状态机和从状态机,从状态机就是一个parse_line函数,负责从buffer中解析出一个行,其初始状态为LINE_OK,原始驱动力来源于buffer中新到达的数据,而当从状态机读取到了一个完成的行,就需要将这个行交给主状态机处理,主状态机中根据当前状态调用不同的函数对报文进行解析,从而实现状态转移。
关于如何提高服务器的性能,还有其他三种方法:首先使用池的概念,由于临时申请进程或线程等资源的CPU消耗比较大,所以我们事先申请好资源,如果不够再临时申请;其次就是复制数据的过程中,尽量使用零拷贝函数,也尽量少进行数据复制;最后就是减少上下文切换和锁的使用。