用input()输入的字符串是8385报文比如:\x30\x30\x30\x30。。。,但是输入后,代码把8583报文字符串中多加了一个\,类似\\x30。
但是我把input()代码注释掉,把8583报文在变量中写死,就没有这个问题,我想应该是编码问题造成的。
input输入和变量固定,难道还有什么不一样吗?
代码如下:
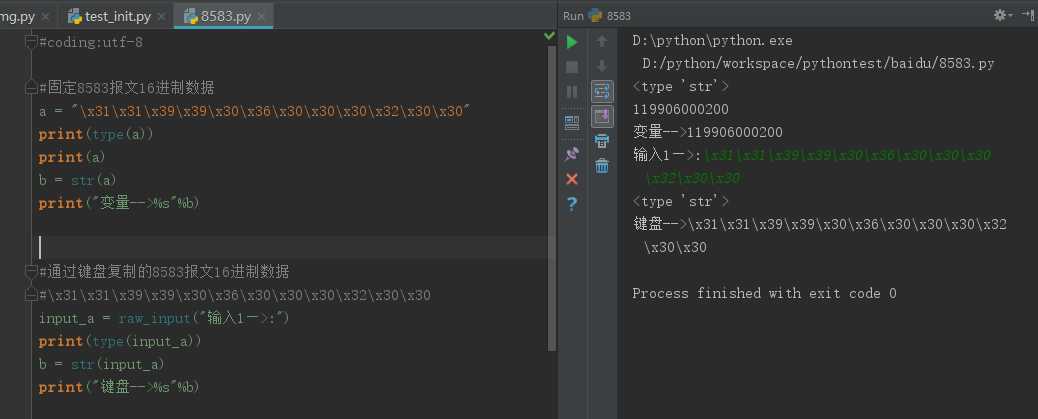
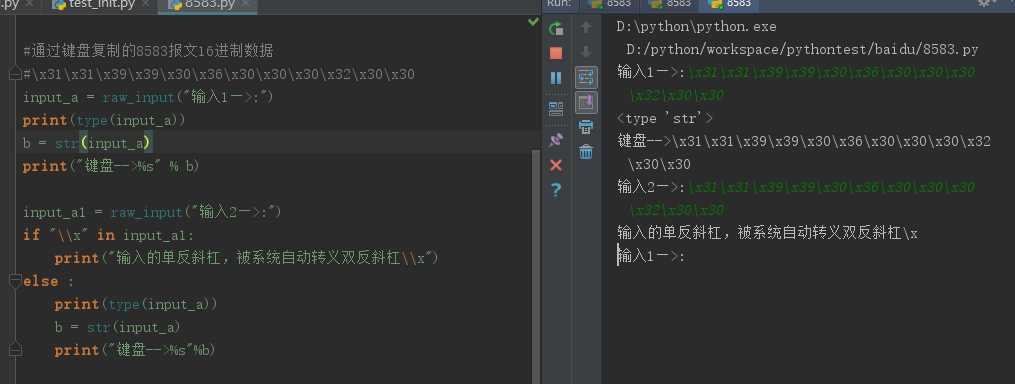
输入的单反斜杠,被系统自动转义双反斜杠\\x,代码中增加了依据判断:
1 if "\\x" in input_a1:
在input()键盘输入时,增加decode("unicode_escape")解决了问题。
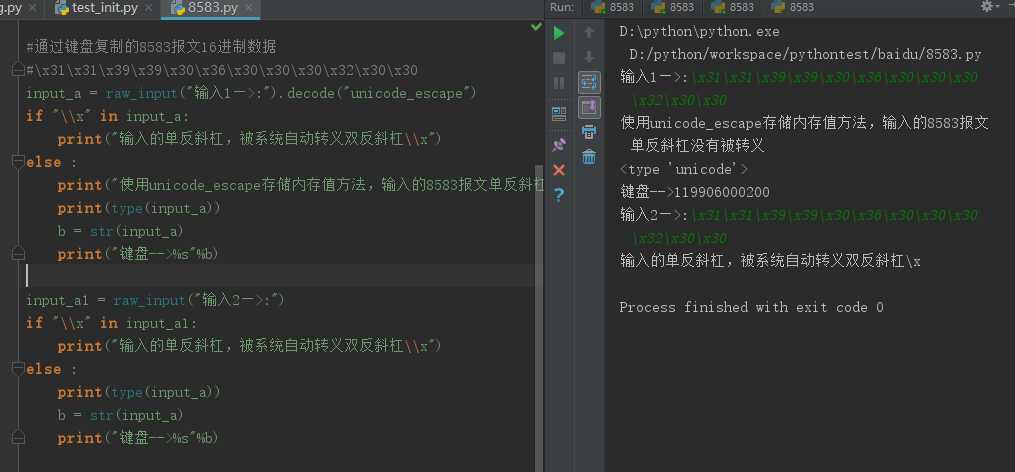
代码如下:
1 #coding:utf-8 2 3 #固定8583报文16进制数据 4 a = "\x31\x31\x39\x39\x30\x36\x30\x30\x30\x32\x30\x30" 5 print(type(a)) 6 print(a) 7 b = str(a) 8 print("变量-->%s"%b) 9 10 11 #通过键盘复制的8583报文16进制数据 12 #\x31\x31\x39\x39\x30\x36\x30\x30\x30\x32\x30\x30 13 input_a = raw_input("输入1—>:").decode("unicode_escape") 14 if "\\x" in input_a: 15 print("输入的单反斜杠,被系统自动转义双反斜杠\\x") 16 else : 17 print("使用unicode_escape存储内存值方法,输入的8583报文单反斜杠没有被转义") 18 print(type(input_a)) 19 b = str(input_a) 20 print("键盘-->%s"%b) 21 22 #查问题 23 input_a1 = raw_input("输入2—>:") 24 if "\\x" in input_a1: 25 print("输入的单反斜杠,被系统自动转义双反斜杠\\x") 26 else : 27 print(type(input_a)) 28 b = str(input_a) 29 print("键盘-->%s"%b)
百度了一些资料,我们数据字符串通常都是str、unicode类型,基本上都是采用直接存储的的方式,还有一种存储方式是按字符串的内存编码值进行存储,它在读取字符串的时候再反转回来。
1 >>> u‘中文测试‘.encode(‘unicode-escape‘) 2 ‘\\u4e2d\\u6587\\u6d4b\\u8bd5‘ 3 4 >>> ‘\\u4e2d\\u6587\\u6d4b\\u8bd5‘.decode(‘unicode-escape‘) 5 u‘\u4e2d\u6587\u6d4b\u8bd5‘