一、UDP套接字
服务端
from socket import * server = socket(AF_INET,SOCK_DGRAM) server.bind(("127.0.0.1",8080)) while True: data,client_addr = server.recvfrom(1024) server.sendto(data.upper(),client_addr)
客户端
from socket import * client = socket(AF_INET,SOCK_DGRAM) while True: msg = input(">>").strip() client.sendto(msg.encode("utf-8"),("127.0.0.1",8080)) data,server_addr = client.recvfrom(1024) print(data.decode("utf-8"))
二、进程相关定义
进程是指程序的运行过程。每个进程都拥有自己的地址空间、内存、数据栈以及其他用于跟踪执行的辅助数据。
多道技术:内存中同时存入多个程序,cpu从一个进程快速切换到另一个,使得每个进程各自运行几十或几百毫秒,虽然在一个时刻,一个cpu只执行了一个任务,但1秒内,cpu却可以运行多个进程,给人带来并行的错觉,即伪并发,以此来区分多处理器操作系统的真正硬件并行(多cpu共享一个内存)
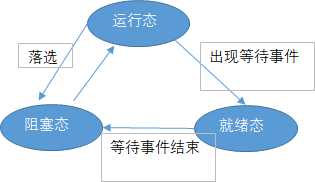
进程三种状态间的转换:
三、python多进程编程
为了利用多核CPU资源,python中使用multiprocessing多线程模块,python多线程无法利用多核优势。进程之间无任何共享数据,进程修改数据仅限进程内。
Process类常用方法:
p.start() 启动进程,调用紫禁城的p.run()方法
p.run() 进程启动时运行的方法,调用target制定的函数,自定义类中必须实现该方法。
p.terminate() 强调终止进程p,不会进行任何清理操作,如果p创建了子进程,该进程就成为了僵尸进程。如果p还保存了一个锁,那么锁也不会释放,导致死锁。
p.is_alive() 如果p仍然运行,返回True
p.join([timeout]) 主线程等待p进程终止。timeout为可选超时时间。
Process类常用属性 p.daemon 默认为False,设置为True后,p代表后台运行的守护进程,当p的父进程终止时,p也随之终止。设定为True后,p不能创建子进程,且必须在p.start()前设置。 p.name 进程名 p.pid 进程pid p.exitcode 进程在运行时为None,如果为-N,表示被信号N结束 p.authkey 进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功
创建子进程的两种方式
from multiprocessing import Process import time def task(name): print("%s is running"%name) time.sleep(3) print("%s is done"%name) if __name__=="__main__": p = Process(target=task,args=("aaa",)) p.start() print("main")
from multiprocessing import Process import time class MyProcess(Process): def __init__(self,name): super(MyProcess,self).__init__() self.name = name def run(self): print("%s is running"%self.name) time.sleep(3) print("%s is done"%self.name) if __name__=="__main__": p=MyProcess("进程1") p.start() print("main")
使用join方法等待子进程结束
from multiprocessing import Process import time def task(name): print("%s is running"%name) time.sleep(3) print("%s is done"%name) if __name__=="__main__": p = Process(target=task,args=("aaa",)) p.start() p.join() print("main")
守护进程
from multiprocessing import Process import time def task(name): # p = Process(target=time.sleep,args=(1,)) #守护进程无法创建子进程,会报错。 # p.start() print("%s is running"%name) time.sleep(3) print("%s is done"%name) if __name__ == "__main__": p = Process(target=task,args=("xxx",)) p.daemon=True p.start() time.sleep(1) print("main") #主进程在此结束,守护进程也会结束。
from multiprocessing import Process import time def foo(): print(123) time.sleep(1) print("end123") def bar(): print(456) time.sleep(3) print("end456") if __name__=="__main__": p1=Process(target=foo) p2=Process(target=bar) p1.daemon=True p1.start() p2.start() print("main") #主进程执行完后,p1守护进程还输入123就已经结束,不过在p2会执行完后,主进程才会结束
互斥锁,针对进程间需要共同操作的资源,需要添加互斥锁
#模拟抢票程序 from multiprocessing import Process,Lock import json import time import random import os def search(): time.sleep(random.randint(1,3)) dic = json.load(open("db.txt",‘r‘,encoding="utf-8")) print("%s查看剩余票数为%s"%(os.getpid(),dic["count"])) def get(): dic=json.load(open("db.txt",‘r‘,encoding="utf-8")) if dic["count"]>0: dic["count"]-=1 time.sleep(random.randint(1,3)) json.dump(dic,open("db.txt",‘w‘,encoding="utf-8")) print("%s购票成功"%os.getpid()) def task(mutex): search() mutex.acquire() get() #对操作余票的函数加锁 mutex.release() if __name__=="__main__": mutex = Lock() for i in range(10): p=Process(target=task,args=(mutex,)) #进程间数据不互通,需用参数传入锁 p.start()
使用Queue实现生产者消费者模型,Queue自带锁。
from multiprocessing import Process,Queue import time import random def producer(name,food,q): for i in range(10): res="%s%s"%(food,i) time.sleep(random.randint(1,3)) q.put(res) print("厨师[%s]生产了[%s]"%(name,res)) def consumer(name,q): while True: res = q.get() time.sleep(random.randint(1,3)) print("吃货[%s]吃了[%s]"%(name,res)) if __name__=="__main__": q=Queue() p1 = Process(target=producer,args=("厨师1","包子",q)) c1 = Process(target=consumer,args=("猪1",q)) p1.start() c1.start() print("main")
上面的程序中生产者做完产品后,消费者并不知道已经生产完了,仍在在等着消费,主进程阻塞无法结束。
通过使用JoinableQueue队列可解决以上问题。
from multiprocessing import Process,JoinableQueue import time import random def producer(name,food,q): for i in range(10): res="%s%s"%(food,i) time.sleep(random.randint(1,3)) q.put(res) print("厨师[%s]生产了[%s]"%(name,res)) def consumer(name,q): while True: res = q.get() time.sleep(random.randint(1,3)) print("吃货[%s]吃了[%s]"%(name,res)) q.task_done() if __name__=="__main__": q=JoinableQueue() p1 = Process(target=producer,args=("厨师1","包子",q)) c1 = Process(target=consumer,args=("猪1",q)) c1.daemon=True #c1中有死循环,需要设置为守护进程,主进程结束自动结束消费者。 p1.start() c1.start() p1.join() q.join() print("main")
四.线程介绍
1.线程相关定义
线程与进程类似,不过是在同一进程下执行的,并且共享一片数据空间。进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位。
使用多线程的原因:
a)多线程共享一个进程的地址空间
b)线程比进程更轻量级,线程比进程更容易创建可撤销,在许多操作系统中,创建一个线程比创建一个进程快10-100倍,再有大量线程需要动态和快速修改时,较有用。
c)若多线程是cpu密集型,那么并不能获得性能上的增强,但如果存在大量的计算和大量的I/O处理,拥有多个线程允许这些活动彼此重叠运行,从而加快程序执行的速度。
2.创建线程
python中使用threading模块创建线程,和multiprocess模块类似。
#第一种方式 from threading import Thread import time import random def task(name): print("%s is running"%name) time.sleep(random.randint(1,3)) print("%s is done"%name) if __name__=="__main__": t1 = Thread(target=task,args=("xxx",)) t1.start() print("main") #先输出线程中的内容
#第二种方式 from threading import Thread import time import random class MyThread(Thread): def __init__(self,name): super(MyThread,self).__init__() self.name = name def run(self): print("%s is running"%self.name) time.sleep(random.randint(1,3)) print("%s is done"%self.name) if __name__=="__main__": t1 = MyThread("xxx") t1.start() print("main") #先输出线程中的内容
3.GIL
尽管python解释器中可以运行多个线程,但在任意给定时刻只有一个线程会被解释器执行。GIL本质为一个互斥锁,将并发运行变成串行。
对于任意面向I/O的Python功能,GIL会在I/O调用前被释放,以允许其他线程在I/O执行的时候运行。而对于没有太多I/O操作的代码,更倾向于在该线程整个时间片内始终占用处理器和GIL。
I/O密集型Python程序比计算密集型代码能够更好地利用多线程环境。
计算密集型程序,多进程效率高,主要用于金融分析。
from multiprocessing import Process from threading import Thread import os,time def work(): res=0 for i in range(100000000): res*=i if __name__=="__main__": l=[] print(os.cpu_count()) #8核 start=time.time() for i in range(4): # p = Process(target=work) #多进程为6.448570728302002秒 p = Thread(target=work) #多线程为21.265116930007935秒 l.append(p) p.start() for p in l: p.join() stop = time.time() print("run time is %s"%(stop-start))
I/O密集型程序,多线程效率高,主要用于socket、爬虫、web等。
from multiprocessing import Process from threading import Thread import threading import os,time def work(): time.sleep(2) print("==>") if __name__=="__main__": l=[] print(os.cpu_count()) start=time.time() for i in range(400): # p = Process(target=work) #多进程9.083257913589478秒 p = Thread(target=work) #多线程2.039461612701416秒 l.append(p) p.start() for p in l: p.join() stop = time.time() print("run time is %s"%(stop-start))