前
这篇主要总结一些优化代码的技巧,一些写代码中的小细节,可能就会影响程序的执行效率,比如一个地方只会影响1ms,那么1000个地方就会影响1s,1s到底长不长?要知道Activity出现ANR异常的时间为5s!!!
主要遵循两个原则
1.不要创建一些没必要创建的对象以及重复定义某个变量
对象的创建是一个非常繁琐的步骤,JVM首先会对通过new指令对符号进行解析,以此来判断该类是否被加载,然后在堆中进行内存分配,为对象分配完内存空间后,就会对内存区域进行初始化(该为0的为0,该为null的为null,这也是为什么方法中的变量需要程序员显示初始化),最后JVM会调用对象的构造函数,而且一般都会有一个变量建立该对象的引用。
所以,创建对象是很麻烦的,就不要没事干就创建对象了。
2.用完的对象要及时回收
就是常说的GC,这里要明确的是,什么时候进行GC操作,不是由程序员决定的,JVM会在有必要的时候自行启动GC,程序员只能做到建议JVM尽快对某对象进行GC,它有两个评判标准
(1) 该对象失去引用,那么最好的办法就是将不用的对象赋值为null
(2) 该对象离开作用域,比如说方法执行完毕,局部变量和对象就会被回收,所以尽可能少生命全局变量。
并且GC操作也是要耗内存的@_@!
开始
1.最频繁的 + 和 +“” 操作
Java中的 +号既可以进行数值计算,又可以进行字符串操作,但是在进行字符串操作的时候,它是一种效率很低的方式,虽然用起来非常非常方便!
1.1 不要直接使用 +号 进行字符串拼接
开发中使用“+”号运算符的确非常方便,但是效率也非常低,因为“+”号内部实际上调用的是StringBuffer的append()方法,然后再转换成String,那么它肯定没有直接调用快。
还有一个就是StringBuilder,这个类是Java1.5时出来的,从效率上来说,它和StringBuffer区别在于StringBuilder不是线程安全的,多线程操作会出现问题,那么就比较容易选择了,
在单线程中,使用StringBuilder,在多线程中使用StringBuffer
1.2 不要直接使用 +“” 来进行字符串转化
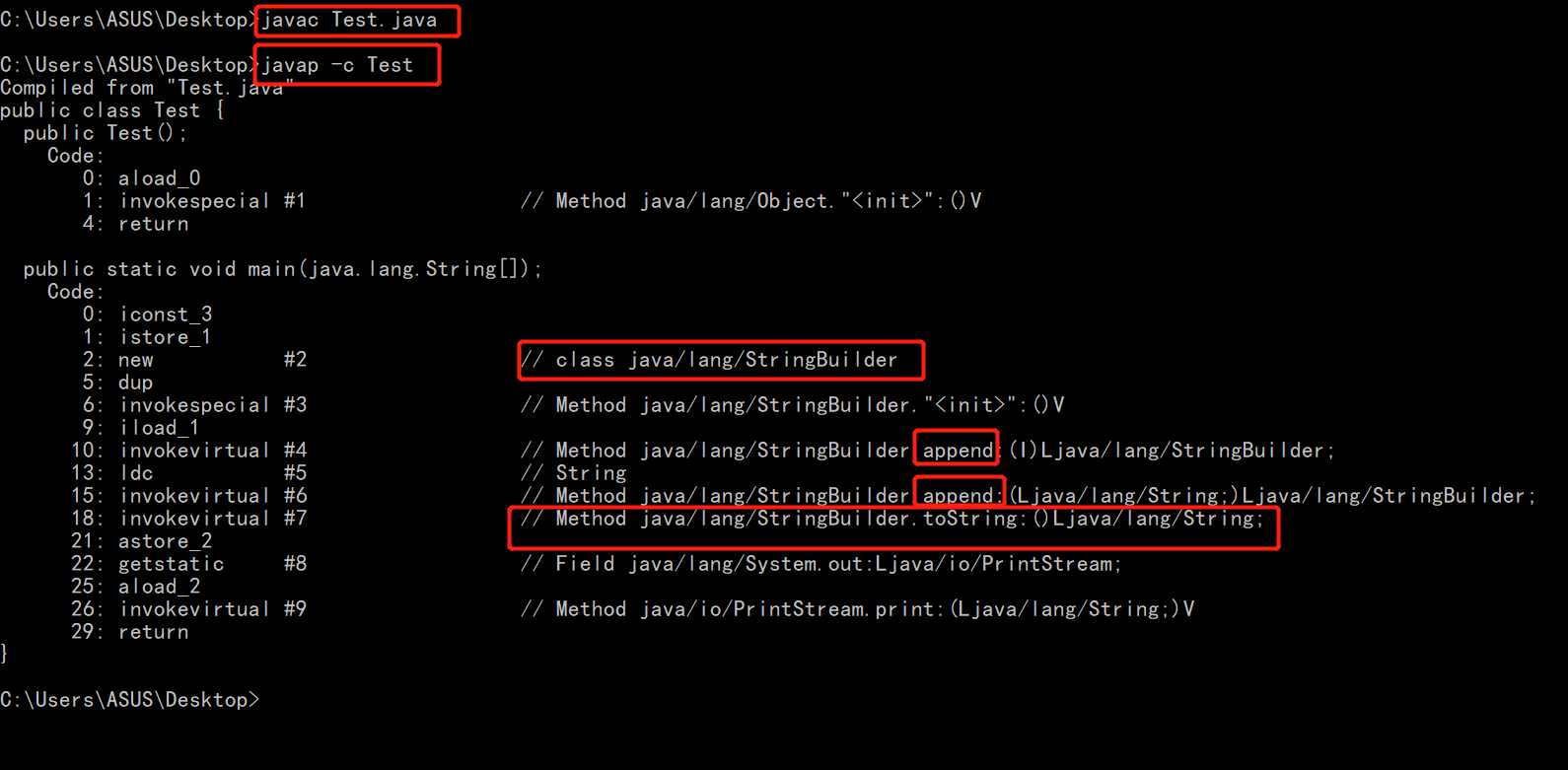
将对象转化成字符串的操作有三种,效率从快到慢依次是,xxx.toString、String.valueOf(xxx)、 xxx +""
xxx.toString是直接转化,而String.valueOf(xxx)底层是调用了toString()方法,至于+"",在1.1时已经说了,它会先转化成SringBuffer,然后再调用toString(),所以结果一目了然
上述两点可以看下面的代码
2.循环的使用细节(以for为例)
循环是开发中频率出现很高的一种操作,它的作用就是简化重复的步骤,比如说添加10000条数据到某个集合中,如果不用循环,即使复制粘贴也要好久,但是通过循环操作就可以几行代码完成。但这里面就会容易出现一些小的细节,有可能就会影响程序的执行效率。以下代码举例:
1 List<String> list = new ArrayList<>(); 2 for (int i = 0; i < 100; i++) { 3 Random random = new Random(); 4 Integer result = random.nextInt(100); 5 String s = result.toString(); 6 list.add(s); 7 }
2.1 尽量不要在循环中创建不必要的对象
示例代码中在for循环中创建了100个Random对象,而实际进行随机数操作的是该对象的nextInt()方法,那么实际上可以写成:
List<String> list = new ArrayList<>(); // 对象创建在for循环外 Random random = new Random(); for (int i = 0; i < 100; i++) { Integer result = random.nextInt(100); String s = result.toString(); list.add(s); }
2.2 不用的对象要及时回收
这里只是举个例子,实际开发中有可能出现的情况是,解析一段Json,然后获取到了Json中的某个对象并添加到了集合中,那么这个被解析过的对象其实就没什么用了,因为数据已经添加到了集合中,比较我们要用的是数据而不是对象,此时就可以置为null,让JVM尽快的回收掉它,这是一个非常好的习惯,
但有些时候例外, 面这种情况, 将对象置为null, 但实际上该对象的引用仍然被list集合所持有, 所以对象不会被回收掉
1 List<String> list = new ArrayList<>(); 2 Random random = new Random(); 3 Integer result; 4 String s; 5 for (int i = 0; i < 100; i++) { 6 result = random.nextInt(100); 7 s = result.toString(); 8 list.add(s); 9 result = null; // 此时虽然将对象置为null, 但是它的引用依然是被list所持有的, 即使result置为null, 仍然不会来回收 10 s = null; 11 }
比较好的做法应该是清空list集合然后将list置为null
1 list.clear(); // 要先将list所持有的对象给清空掉 2 if(list != null) { 3 list = null; 4 }
在实际开发中, 可以写在onDestory()方法中
2.4 适当的建立方法结果的缓存
比如有时候为了简便会这样写
Java在调用某个方法时,其实也不是那么简单,要创建栈帧来存储局部变量表,操作数栈,动态连接,方法返回地址,还要方法调用现场、恢复方法调用现场等一系列操作。所以,如果list的size()非常大时,也会影响效率,所以可以定义一个变量而不是直接使用
3. if和switch的使用
既然有了循环,那么就应当有判断@_@!
3.1 通过if来在合适的时候创建对象或调用方法
这个也算一个小细节
这个循环里面可以看出,只有在随机数为20的时候集合才会添加该数据,所以在此之前,将随机数调用toString()方法毫无意义。所以可以写为
4 使用位运算来代替乘除运算
计算机只懂二进制,而位运算就是直接的二进制运算,所以当然效率比较高,
当然也有缺点
(1) 对于数字过大,还是直接乘除比较方便
(2) 代码的可读性不高
5 合理利用Activity的生命周期
Activity的生命周期最常用的莫过于onCreate(),但是其它的生命周期我想也很有必要恰当的利用。
这个仅仅是个人书写习惯,不知道会不会影响到性能,但是最起码这样写代码结构比较清晰 :)
6 使用Zipalign来进行代码对齐
Zipalign是一个SDK下的工具,能够对apk文件中未压缩的数据在4个字节边界上对齐,当资源文件通过内存映射对齐到4字节边界时,android系统就可以通过调用mmap函数读取文件,
mmap函数是Linux系统的调用函数,提供了不同于一般对普通文件的访问方式,进程可以像读写内存一样对普通文件的操作,进程可以像读写内存一样对普通文件的操作,不必再read()和write(),在读取资源上获得较高的性能。如果资源本身没有进行对齐处理,它就必须显式地读取它们——这个过程将会比较缓慢且会花费额外的内存。
具体用法我会在工具篇中总结
7 使用SparseArray代替HashMap 使用SparseArray来代替HashMap,原因是一次Android Studio的提示,
使用SparseArray比HashMap好,所以就网上查找了些SparseArray的一些相关资料
简单的来讲,SparseArray适用于HashMap<Integer, Object>这样的结构,因为SparseArray内部是用的int型数组存储key和Object型的数组存储value的值,省去了int包装成Integer的过程.
根据这篇文章,可以看出来,在数据过多时,效率上SparseArray并没有比HashMap更快,但是该文章作者结尾处说内存的使用状况上,能够节约27%
而这篇文章的作者专门对内存的使用状况做了测试,说是内存上优化了35%
我通过Android Studio自带的工具观察内存消耗,使用HashMap大约在3.24~3.31
而SparseArray大约在3.0~3.1之间
不过具体优化了多少不是重点,反正是对内存开销上SparseArray开销更低更具有优势~!
另外除了SparseArray,ArrayMap,SparseBoolMap,SparseIntMap,SparseLongMap,LongSparseMap等等一些列API,在内存使用方面都相对于HashMap要好的多
8 I/O流尽量使用带Buffer的
带Buffer缓冲区的I/O对象效率要比不带的高一些,
9. 能不static就不static,能final就final
static虽然让成员用起来很爽,但是会延长它们的生命周期
final会使对象无法被继承,变量无法被修改,方法无法被重写,并且会进行内联
结束
暂时想到的就这么多了,仅仅是一些开发中的细节部分,有些众所周知的就没写,比如复用ListView的ConvertView,压缩图片、异步加载等等,