1 引言
本次作业完成了基于Lucene的“虎扑篮球”网站搜索引擎,对其主要三个板块---“最新新闻”(主要NBA新闻),“虎扑步行街”(类似贴吧性质),“虎扑湿乎乎”(篮球发帖区)进行页面分析并建立索引完成搜索引擎。
1.1 设计目的
搜索引擎是一个很有用的程序,可以让你更方便,快捷的实现目标信息的查找和检索,本程序就针对虎扑篮球网站的三个子页面的帖子题目建立索引,并可实现显示目标条目的标题、时间、来源、和正文内容、以及原网址URL。
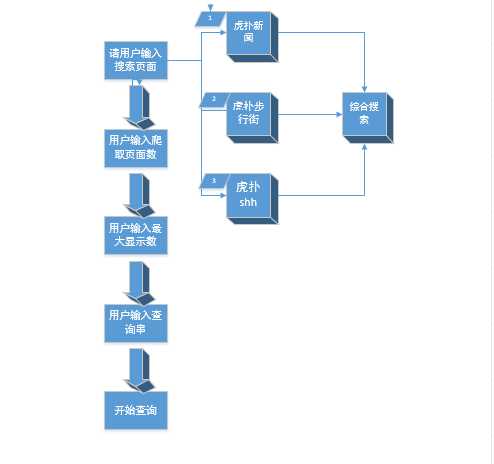
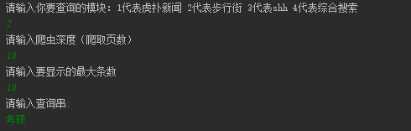
(1) 当程序运行时,在java scanner上会显示提示信息“请输入你要查询的模块:1代表虎扑新闻 2代表步行街 3代表shh 4代表综合搜索”分别代表用户搜索的四种搜索需求
(2) 输入完要求数字后,会显示如下提示信息“请输入爬虫深度(爬取页数)”,这条信息代表用户想要搜索的页数,页数越多,产生的内容越多。(相当于规定搜索页数)
(3) 之后会提示输入最大显示数量,顾名思义,由用户输入显示的最大条目数。
(4) 最后会让用户输入查询串,然后敲入回车就可以根据查询串来找到对应数量的条目。
(5) 如果选择搜索虎扑新闻,则会显示最大条目数的新闻的条目、新闻的来源、新闻发布的时间、原网页的url还有全部的正文内容(正文内容格式按照原网页)。
(6)如果选择shh或虎扑步行街搜索,则会显示最大条目数的 贴子题目,发帖具体年月日、来源、原文url、正文内容 。
(7) 如果用户选择4综合搜索,则会显示出最大条目数的全部页面的搜索结果(新闻、shh、步行街),并且每个条目都会显示出其对应结构和正文内容,方便用户挑选和查看。
1.2 设计说明
本程序采用Java程序设计语言,在IDEA平台下编辑、编译与调试。
Jdk版本1.7,使用外部工具包有:Jsoup、Lucene。
2 总体设计
2.1 功能模块设计
本程序需实现的主要功能有:
(1) 用户可以自定义搜索页面
(2) 用户可以自定义爬虫深度也就是爬取页数
(3) 用户可以选择最大显示数目
(4) 输入搜索串,根据搜索串显示
程序的总体功能如图1所示:
2. 2 流程图设计
程序总体流程如图2所示:
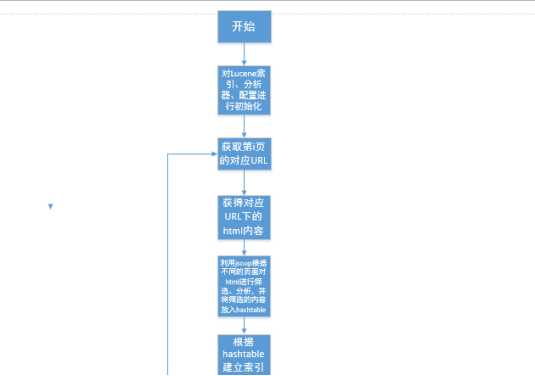
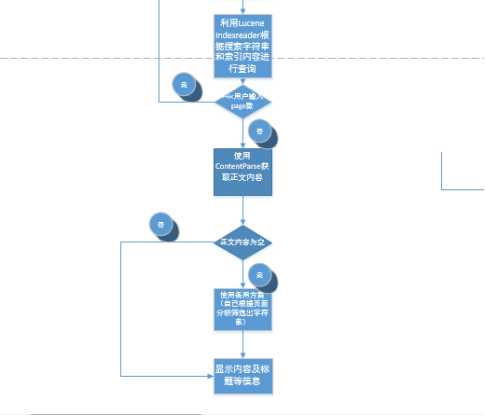
图2 设计总体流程图
3 详细设计
3.1 设计概述
搜索引擎的设计总体分量四大部分:
第一部分是爬虫,主要是对想要搜索的页面进行爬取,获取其html信息;
第二部分是对这些html信息进行筛选、分析并最后转化成需要的字符串;
第三部分是利用Lucene框架对处理好的字符串信息建立索引,并根据搜索串搜索;
第四部分是将需要的信息以字符串的形式显示(正文url,正文内容,来源等)。
3.2 网页爬虫及其内容提取和分析
1、初始化:在做这一步之前,需要对Lucene的内容做初始化。

这里面使用在RAM里面建立索引,避免了空间的浪费,其余变量通过Lucene手册规范建立。
2、获取:通过jsoup的connect的get方法获取其对应url下的html内容
org.jsoup.nodes.Document doc = Jsoup.connect(url).get();
3、筛选:
主要函数:
public static Elements[] getNews(Document doc)
函数目的:
将步骤一得到的doc对象作为参数,使用getNews函数获取对应筛选标签下的元素集合。
函数核心代码:
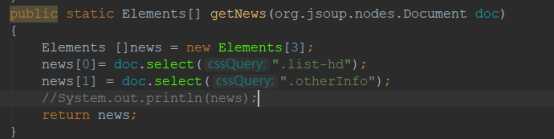
函数详解:我们通过分析三个页面的html代码找到新闻标题和url所在的标签
下面我们以虎扑新闻为例来解读我们是如何筛选标签的:(其他类似,不一一页面分析)

从这个截图中我们可以看出所有的虎扑新闻都放在class=“list-head”标签下,而所有的其他信息都放在class=“other-Info”标签里。,所以我们建立了一个Elements的数组,用来分别存放这两个标签的html代码并返回。
4、解析
主要函数:
public static HashMap<String,String> analyze(Elements[]e)
函数目的:步骤而得到的Elements数组,返回一HashMap类型的值,该值的键为对应新闻内容的url(string),值为对应的新闻标题和新闻事件来源等信息(string)。
实现方法:首先是url的提取,这里使用了正则表达式
String regex = "https://[\\w+\\.?/?]+\\.[A-Za-z]+";
来提取出对应标签的url,(由于第二步做过筛选,所以可以保证当前每一个elements内只有一个url,所以可以用正则表达式)。
之后使用Elements自带的方法eachText()方法获取正文内容。再做一些细节修补工作,将新闻时间等附加内容与标题相连。
核心代码:
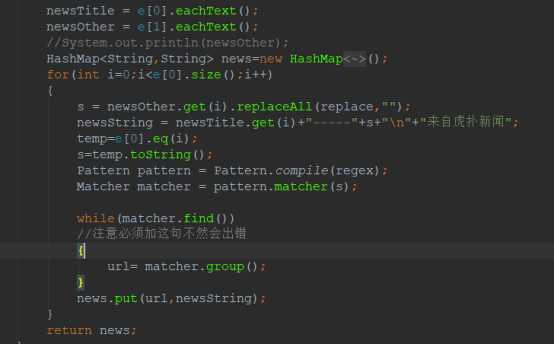
最后返回哈希表news即可。
3.3 Lucene索引的建立和搜索
1、建立索引
1、主要函数:
public static void creatIndex(HashMap news,IndexWriter w)
2、函数作用:对上一步得到的HashMap的内容进行分析,并对他们的不同部分建立索引。
3、函数实现:使用迭代器遍历HashMap的键值对,取出里面的内容并adddoc方法建立索引。
4、addDoc方法:将三个参数根据“url”“newstitle”“newsother”三个字段增添索引

2、搜索
1、主要函数
public static void Search(String querystr,intnum,Directory index)
2、函数作用:通过对传入的索引index进行搜索串querystr的搜索,获取“命中的项”
3、函数实现:根据Lucene使用手册的代码修改得到:

3.3内容的显示
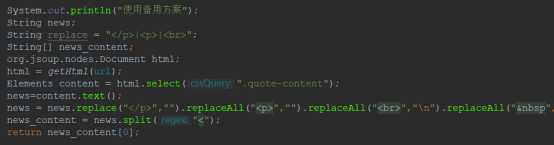
这里我为了正确的显示出内容,使用了两种方法来获取信息,第一种是老师推荐的方法Boilerpipe,但是发现这种训练方法对一些简单页面确实可以实现提取正文,但是对一些复杂页面(特别是带有很多评论的页面)提取出的正文为空,为了解决这个问题,我写了备用方案。当检测到Boilerpipe方法获取正文为空时,就启用备用方案。
备用方案的思路很简单,就是按照页面找出内容所在的标签,获取其正文,再之用字符串replace,等方法对其进行修改即可。
4 测试与运行
4.1 程序测试
在程序代码基本完成后,经过不断的调试与修改,本次爬虫程序终于能正常运行如期运行。调试过程主要包括对显示结果格式的调试(需要去掉对应换行标签等),顺序的调试,显示内容完整性的调试等。
4.2 程序运行
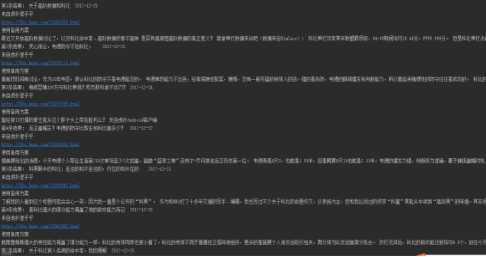
对虎扑shh板块的的搜索

显示的shh内容如下图所示:
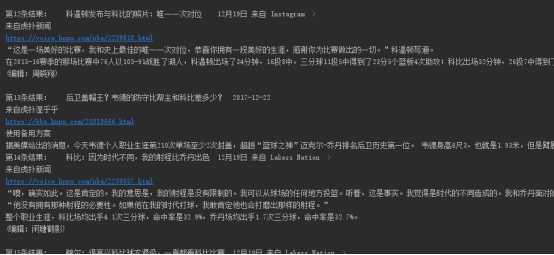
对虎扑新闻的搜索:

显示结果截图:

对虎扑步行街论坛的搜索:
搜索结果截图:
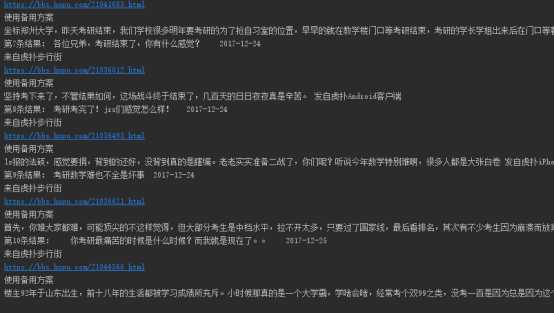
综合搜索:

搜索结果:
5.总结
通过这次实验我收获了很多:
1、首先了解了LUCENE搜索引擎框架,以后些其他搜索引擎可以更加得心应手;
2、通过阅读文档和实际使用,掌握了jsoup的基本用法;
3、增强java的编程能力。
本次实验的不足:
1、代码有冗余,下次可以多多使用封装和继承,使代码可读性更高;
2、没有做高亮显示;
3、只分析了3个页面,以后完善可以多分析几个页面(其实原理相似),增加代码完成度;
4、由于搜索的很多都是球星的名字,名字有些不规则,Lcunene分词器可能没法给出准确区分,所以有时候会出现搜索结果不匹配。
(比如搜索“科比”,可能会出现xxx比xxx高这样的选项)
(很喜欢这次实验,写出这个也算我这么多年的虎扑jrs没白当吧)
(要源码的私戳吧,就不放在这献丑了)