1.limit &skip
(1)Limit
- 方法limit():用于读取指定数量的文档
- 语法:
db.集合名称.find().limit(NUMBER)
- 参数NUMBER表示要获取文档的条数
- 如果没有指定参数则显示集合中的所有文档
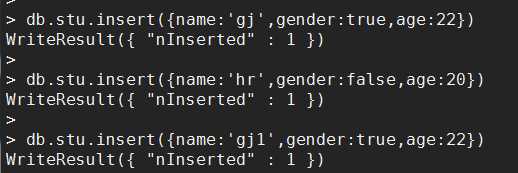
- 例1:查询2条学生信息
db.stu.find().limit(2)
(2)skip
- 方法skip():用于跳过指定数量的文档
- 语法:
db.集合名称.find().skip(NUMBER)
- 参数NUMBER表示跳过的记录条数,默认值为0
- 例2:查询从第3条开始的学生信息
db.stu.find().skip(2)
(3)一起使用
-
方法limit()和skip()可以一起使用,不分先后顺序
-
创建数据集
for(i=0;i<15;i++){db.t1.insert({_id:i})}
- 查询第5至8条数据
db.stu.find().limit(4).skip(5) 或 db.stu.find().skip(5).limit(4)
2.投影
- 在查询到的返回结果中,只选择必要的字段,而不是选择一个文档的整个字段
- 如:一个文档有5个字段,需要显示只有3个,投影其中3个字段即可
- 语法:
- 参数为字段与值,值为1表示显示,值为0不显示
db.集合名称.find({},{字段名称:1,...})
- 对于需要显示的字段,设置为1即可,不设置即为不显示
- 特殊:对于_id列默认是显示的,如果不显示需要明确设置为0
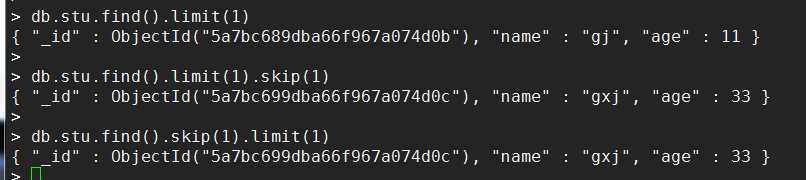
例1
db.stu.find({},{name:1,gender:1})
例2
db.stu.find({},{_id:0,name:1,gender:1})
3.排序
- 方法sort(),用于对结果集进行排序
- 语法
db.集合名称.find().sort({字段:1,...})
- 参数1为升序排列
- 参数-1为降序排列
- 例1:根据性别降序,再根据年龄升序
db.stu.find().sort({gender:-1,age:1})

4.统计个数
- 方法count()用于统计结果集中文档条数
- 语法
db.集合名称.find({条件}).count()
- 也可以与为
db.集合名称.count({条件})
- 例1:统计男生人数
db.stu.find({gender:1}).count()
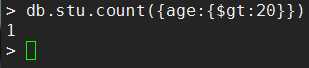
- 例2:统计年龄大于20的男生人数
db.stu.count({age:{$gt:20},gender:1})
5.消除重复
- 方法distinct()对数据进行去重
- 语法
db.集合名称.distinct(‘去重字段‘,{条件})
- 例1:查找年龄大于18的性别(去重)
db.stu.distinct(‘gender‘,{age:{$gt:18}})