欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~
基本介绍
在本文中,你会对如何使用JavaScript实现机器学习这个话题有一些基本的了解。我会使用Encon(一个先进的神经网络和机器学习框架)这个框架,并向你们展示如何用这个框架来实现光学字符辨识,模拟退火法,遗传算法和神经网络。Encog同时包括了几个GUI窗体小部件,这些小部件可以更方便地显示出一般机器学习任务的输出。
运行环境
Encog是一个面向Java,C#,JavaScript和C/C++的高级机器学习平台。除此之外,Encog还可以为http://www.heatonresearch.com/wiki/Meta_Trader_4的实际案例生成对应代码,本文将重点介绍如何使用支持JavaScript的Encog框架,该框架允许你创建利用人工智能实现的交互式web应用程序。访问以下网址获取有关Encog的更多信息。
http://www.heatonresearch.com/encog
代码调用
本文介绍的所有示例代码都可以在附带的下载中找到。
这段代码同时被托管在下面的GitHub库中。
https://github.com/encog/encog-javascript
你可以看到本文讨论的所有示例都运行在下面的URL中:
http://www.heatonresearch.com/fun
Encog框架包含在两个JavaScript文件中。第一个JavaScript文件包含了所有核心的机器学习函数。这个JavaScript文件被命名为encog-js-x.js。第二个文件包含了所有的GUI窗体小组件,并被命名为encog-widget.js。你可以在下面的引用路径中阅读这两个文件。
<script src=" encog-js-1.0.js"></script> <script src="encog-widget-1.0.js"></script>
欧氏距离
我们从欧氏距离开始谈起,欧氏距离是一个非常简单的概念,适用于不同的机器学习技术。欧氏距离提供的结果是一个数字,该数字决定了相同长度的两个数组之间的相似性。思考下面三个数组:
Array 1: [ 1, 2, 3] Array 2: [ 1, 3, 2] Array 3: [ 3, 2, 1]
我们可以计算出上面任意两个数组之间的欧氏距离,这对于确定数组之间的相似度是非常有用的。思考一下,假如我们想要确定一下数组2或者数组3哪个距离数组1更近。为了做到这一点,我们需要计算数组1和数组2之间的欧氏距离。然后再计算数组1和数组3之间的欧氏距离。两相比较,最短的就是最相似的。
从数学角度来讲,欧氏距离由以下方程式进行计算。
图 1: 欧氏距离

使用这个公式,我们现在可以计算上文中的欧氏距离
d(a1,a2) = sqrt( (a2[0]-a1[0])^2 + (a2[1]-a1[1])^2 + (a2[1]-a1[1])^2 ) d(a1,a2) = sqrt( (1-1)^2 + (3-2)^2 + (2-3)^2 ) d(a1,a2) = sqrt( 0+1+1 ) d(a1,a2) = sqrt(2) = 1.4 d(a1,a3) = sqrt( (a3[0]-a1[0])^2 + (a3[1]-a1[1])^2 + (a3[1]-a1[1])^2 ) d(a1,a3) = sqrt( (3-1)^2 + (2-2)^2 + (1-3)^2 ) d(a1,a3) = sqrt( 4+0+4 ) d(a1,a3) = sqrt(8) = 2.3
从结果中我们可以看出数组2比数组1更为接近数组3。
下面的JavaScript代码实现了欧氏距离的计算。
ENCOG.MathUtil.euclideanDistance = function (a1, a2, startIndex, len) { ‘use strict‘; var result = 0, i, diff; for (i = startIndex; i < (startIndex + len); i += 1) { diff = a1[i] - a2[i]; result += diff * diff; } return Math.sqrt(result); };
欧氏距离可以被用来创建一个简单的光学字符辨识实例。你可以在下图中看到应用程序运行实例:
图 2: JavaScript光学字符辨识

你可以在下面这个URL中查看程序的运行实例:
http://www.heatonresearch.com/fun/ocr
HTML5(启用触控设备)的JavaScript应用程序可以通过简单的欧氏距离来实现基本的光学字符辨识。为了使用这个示例,需要在下面这个大的矩形中绘制一个数字,然后点击“Recognize”(识别)按钮,程序会尝试猜测你画的这个数字。虽然准确性并不是特别高,但它做的确实已经很不错了。
该程序已经通过了数据训练,你可以移除这些数字条目中的任何一个,或者创建你自己的条目。如果需要训练一个新字符的OCR,只要简单绘出那个字符,然后点击“Teach”(教学)按钮。则该字符就会被增加到已知的字符列表中。
你会发现,你所绘制的任何东西都是先剪裁然后向下采样的。程序会对你所绘制的高分辨率字符向下采样并将采样点分配到5×8网格中。然后将这个通过向下采样得到的网格与每个数字的向下采样网格进行比较。如果要查看程序中经训练后得到的网格,需要在字符列表中单击你希望看到的字符。然后程序会将这个网格转换成一个一维数组,而一个5×8的网格会有40个数组元素。
以下JavaScript代码执行了这个搜索,并且实现了一个欧氏距离的计算
var c, data, sum, i, delta; for(c in charData ) { data = charData[c]; // 现在我们将会识别出这个画出来的字母. // 为此,我们需要利用欧氏距离来计算 // http://www.heatonresearch.com/wiki/Euclidean_Distance (这是欧氏距离运行实例的URL) sum = 0; for(var i = 0; i<data.length; i++ ) { delta = data[i] - downSampleData[i]; sum = sum + (delta*delta); } sum = Math.sqrt(sum); // 最基本的,我们需要计算的是欧氏距离 // 我们画上去的字母,我们学习的每一个样本 // 程序将会返回欧氏距离最小的那个字符 if( sum<bestScore || bestChar==‘??‘ ) { bestScore = sum; bestChar = c; } }
蜂拥算法
这个例子展示一个名为flocking(蜂拥)的迷人的简单算法。此处的粒子是成群存在的。起初的时候,它们各自随机出现在某个位置,然而,这些粒子会很快地填充成各种形式的组,并以看似复杂的模式路线飞行。或者你也可以手动点击(或者触摸)一个位置,这些粒子会排斥并远离你的接触点。
图3:flocking(蜂拥算法)

你可以在线运行以下URL的实例程序:
http://www.heatonresearch.com/fun/flock
这个实例可能需要一分钟(大约),才能让成熟的蜂拥集群出现。即使这些集群出现了,它们也经常会再次分裂和重组。重启时点击“Clear”(清除),或者也可以点击“Big Bang”(大爆炸模式),该模式不会使用任何随机的初始化,而是将粒子统一放置在面板中央,并且以粒子设定的“复杂模式”迅速向外移动。
克雷格·雷诺兹在1986年首次用他的模拟程序Boids在计算机上成功模拟出了蜂拥算法。蜂拥集群是一种非常复杂的行为。他在不同种类的动物中有各自表现形式,各自使用了很多不同的名字。比如一群小鸟,一群昆虫,一个学校的鱼群,一群牛等等。其实就是用不同的名字来描述本质相同的行为。
初看上去,蜂拥算法可能看似复杂。因为我们需要创建一个对象来处理集群中的个体、需要定义一个蜂拥对象来容纳集群成员、需要为确定蜂拥集群应该向哪个方向移动而制定常规行为。我们还必须确定如何将蜂拥集群分成两群或者更多的群。那么问题是什么样的标准可以决定某个群体可以得到成员数量?新成员如何被确认是属于哪一个集群?你可以在下面内容中看到一些真实的蜂拥集群例子。
蜂拥算法其实很简单,它只有三条规则:
- 分离 :远离拥挤的邻居(短距离相互排斥)
- 对齐 :趋近于邻居的平均方向
- 内聚 :转向邻居的平均距离位置(长距离相互吸引)
这三个基本规则是必需的。蜂拥算法其实就是“简单的复杂”的典型例子。
我希望这个例子能够尽可能的简单,但是仍然表现出看似复杂的行为方式。其实这些粒子都是以恒定的速度运行的,每个粒子都有一个角度属性来定义粒子运动的方向。所以这些粒子不可以加速或者减速,唯一可以做到是转向。
上述的三种规则其实是分别为粒子的运动设定好了一个“理想的角度”,遵守这三种规则的期望被特定的百分比属性所抑制。这些抑制因子是你在底部看到的三个数字。你可以尝试填入一些数字,看看它们是如何影响集群粒子的运动轨迹的。其实有很多的数字组合不会产生集群的行为,而我在实例中填入的默认值是比较合适的。
如果你想单独查看这三种规则中单独一条生效时的结果,那么可以将该规则设置为1.0,其它的规则设置为0.0。例如当内聚的规则单独生效时,你会所有的粒子会聚集在面板区域中少数的几个位置。
在这个区域中不存在任何随机性。除了粒子最初出现的位置是随机的之外,不会产生更多的随机数。你甚至可以点击“Big Bang”(大爆炸模式)按钮,来消除系统中所有的随机性。如果你点击了“Big Bang”按钮,则所有的粒子都会被放置到区域的中心位置,并以同样的方向运动。如此一来,要形成一幅复杂的运动模式并不会花费很长时间。所以对于用非常简单的规则来实现非常复杂的系统来说,蜂拥算法是一个非常典型的例子。
理解欧氏距离对于例子很重要。因为每个粒子都有两个维度,分别是x坐标和y坐标。利用欧氏距离的计算方法,我们就可以很快找到最近的邻居。由此即引入了另一种重要的机器学习算法,即“K-邻近算法”。这个K就是你希望找到的邻居的数量。
这三种规则可以很容易的用JavaScript实现。首先,我们计算出理想的分离角度。
// 1. 隔离-避免拥挤的邻居 (短距离的排斥力) separation = 0; if (nearest.length > 0) { meanX = ENCOG.ArrayUtil.arrayMean(nearest, 0); meanY = ENCOG.ArrayUtil.arrayMean(nearest, 1); dx = meanX - this.agentsi; dy = meanY - this.agentsi; separation = (Math.atan2(dx, dy) \* 180 / Math.PI) - this.agentsi; separation += 180; }
首先,我们需要计算出所有邻居粒子的x坐标的平均值和y坐标的平均值,这个平均坐标点就是邻近集群的中心点。然后,借用一些三角函数中的知识,计算出我们和邻近集群中心点之间的夹角值。对这个夹角值加上180,因为我们是希望远离这个邻近的邻居的(进而我们就不会撞到它们)。这个才是我们应该努力争取的理想分离角度。
紧接着,我们会计算出理想的对齐角度。如下代码所示。
// 2. 对齐-转向邻居的平均方向 alignment = 0; if (neighbors.length > 0) { alignment = ENCOG.ArrayUtil.arrayMean(neighbors, 2) - this.agents[i][2]; }
对齐非常简单,其实就是所有邻居的平均角度。
接下来我们计算内聚力。为此我们再来看看邻居,不过这回考虑的是一个更大的集合,几乎包括了所有的粒子。
// 3. 内聚-转向邻居的平均位置(长距离的吸引力) cohesion = 0; if (neighbors.length > 0) { meanX = ENCOG.ArrayUtil.arrayMean(this.agents, 0); meanY = ENCOG.ArrayUtil.arrayMean(this.agents, 1); dx = meanX - this.agents[i][0]; dy = meanY - this.agents[i][1]; cohesion = (Math.atan2(dx, dy) * 180 / Math.PI) - this.agents[i][2]; }
现在我们从这个规则中得到了理想的角度,那么必须要开始转动粒子(或者说是代理)了。
// 执行转向操作 // 这三种规则的参数应用值是可以配置的 // 我提供的这三个默认值比例的运行表现很好 turnAmount = (cohesion * this.constCohesion) + (alignment * this.constAlignment) + (separation * this.constSeparation); this.agents[i][2] += turnAmount;
到目前为止,我们研究的技术并不是随机性的,而是可以被认定为决定性的。也就是说得到的结果总是可以预测的。对于本文的内容的排版,我们会做出180度的调整,剩下的技术都是研究随机性的。也就是用随机性来解决问题。
旅行推销员问题(TSP问题)
旅行推销员问题(TSP)意为存在一名“推销员”,他必须经过一定数量的城市,而这条最短的旅行路线就是我们寻找的目标。其中允许推销员从任意一个城市开始或者结束。唯一的要求是“推销员”必须经过每一个城市并且只能经过一次。
如果用一般的迭代程序实现,这似乎是一个简单的任务。思考一下随着城市数量的增加,可能的排列组合数量会增加多少。如果只有一两个城市,那只需要一步迭代就够了。如果是三个城市呢,迭代步骤就变成了6步。表格8-1列举出了迭代步骤的增长速度。
表1:用常规程序解决TSP问题的步骤数目
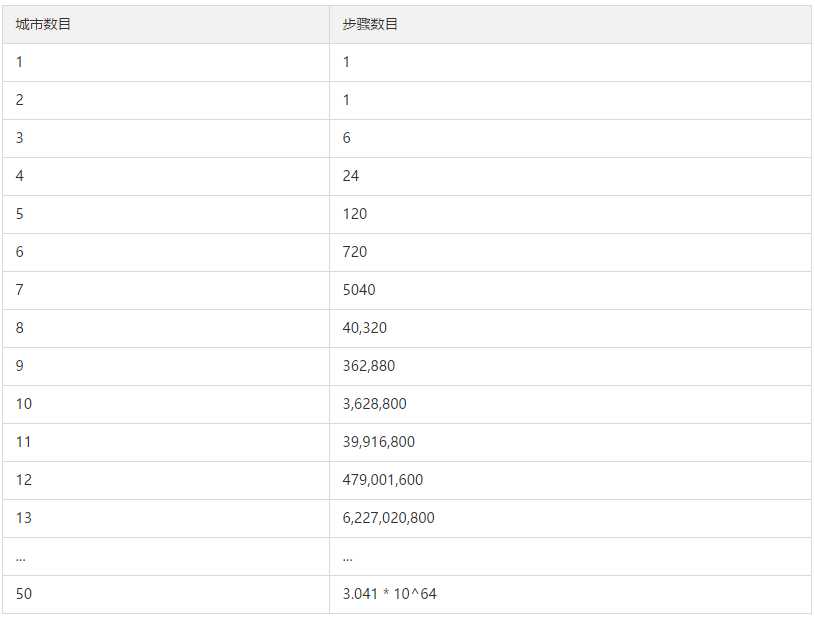
表格中的计算公式就是阶乘。步骤数目n的数量就是用阶乘符号!计算的。任意n值的阶乘计算方式是n×(n?1) ×(n?2).......3×2×1
由这个公式不难看出当一个程序必须使用“暴力”方式进行搜索时,这些数值会变得非常大。在下一节的讨论中,我们使用的示例程序会在几分钟内找到一个能解决50个城市问题的解决方案,这个程序用到是模拟退火法的思路,而不是使用普通的暴力搜索。
模拟退火法
模拟退火法是一种模拟退火的物理过程的编程方法,退火是指将某种材料(比如钢铁或者玻璃)加热后再冷却的方法,通常用来软化材料以及降低材料硬度。由此可知,模拟退火法就是将一个“解决方案”暴露在“热处理”的环境中,然后进行冷却处理进而产生一个更好的解决方案。你可以在下面的URL中运行模拟退火法的示例程序。
http://www.heatonresearch.com/fun/tsp/anneal
模拟退火法是通过从起始温度到结束温度的多次迭代进行实现的。循环计数允许你指定温度下降的粒度。温度越高,系统引入的随机性就越高。你可以配置这三个参数的值。
下面的JavaScript代码实现了模拟退火法
anneal.randomize = function(path, temperature) { var length = path.length - 1; // 调整路径上城市的次序(即模拟退火) for (var i = 0; i < temperature; i++) { var index1 = Math.floor(length * Math.random()); var index2 = Math.floor(length * Math.random()); var d = universe.pathDistance(path, index1, index1 + 1) + universe.pathDistance(path, index2, index2 + 1) - universe.pathDistance(path, index1, index2) - universe.pathDistance(path, index1 + 1, index2 + 1); if (d > 0) { // 如果需要的话对index1 和 index2进行排序 if (index2 < index1) { var temp = index1; index1 = index2; index2 = temp; } for (; index2 > index1; index2--) { var temp = path[index1 + 1]; path[index1 + 1] = path[index2]; path[index2] = temp; index1++; } } } }
上面的随机化函数是专门为TSP问题定义的。在Encog框架中模拟退火法是通用的,相对于TSP独立。所以你必须为你希望解决的问题提供一个随机函数。
基本来说,随机化函数会根据温度对城市的旅行路线进行修正。上面的函数只是简单地根据温度将旅行路线中的路线上经过城市次序进行对换。温度越高,对换的次数越多。
随机城市
这个程序的常见用法是将随机几个城市放置地图上,这些城市出现在地图上的随机的几个位置。随机城市问题的排列组合相比于其他的固定城市组合要更困难一些。在下图中你可以看到包含了50个随机的城市的地图。
图 4:随机城市

一旦解决了这组随机城市TSP问题,结果就如下图所示。
图 5:可能的解决方案

你可能想要通过改变参数来评估模拟退火法的实际效果,为此需要重新运行该程序,并且你应该随机化旅行路线。这样你就可以用相同的城市配置重新开始。
城市圈
你可以将城市位置以椭圆的形状进行排列,这样就更容易理解模拟退火法是如何演化出最佳解决方案的。围绕一个椭圆的最优路径与它的周长形状类似。在这里你可以利用模拟退火法,找到一条几乎就是最优的路径。
图 6:城市圈

遗传算法
利用遗传算法(GA)可以得到TSP问题的潜在解决方案。GA是通过简单的进化操作来创建一个能够不断改进的解决方案。这整个过程就相当于生物遗传进化的精简版。进化其实就是通过交叉和突变实现的,所以当两个解决方案“交配”并产生后代时,就相当于发生了交叉。而当单一的解决方案稍微有所改变时就相当于引发了突变。
类似于模拟退火法,GA(遗传算法)也是随机的。在交叉过程中会由随机性来决定父本和母本会遗产什么样的特征给子代。
你可以在下面的URL中在线查看TSP(旅行推销员问题)的遗传算法应用程序:
http://www.heatonresearch.com/fun/tsp/genetic
为了使用Encog框架中自带的遗传算法,你必须定义变异和交叉这两个操作,它们的实现取决于你正在寻找的解决方案的类型。
下面的代码定义了TSP问题的突变操作。
genetic.mutate = function performMutation(data) { var iswap1 = Math.floor(Math.random() * data.length); var iswap2 = Math.floor(Math.random() * data.length); // 不相等时 if (iswap1 == iswap2) { // 继续下一步 // 但是,不要出界 if (iswap1 > 0) { iswap1--; } else { iswap1++; } } var t = data[iswap1]; data[iswap1] = data[iswap2]; data[iswap2] = t; }
这段代码与模拟退火法的随机化操作非常类似。本质上,程序对列表中的两个城市进行了交换操作。所以我们必须保证这两个随机城市是不相同的,因为一旦相同,这两个城市就不会发生交换。
交叉操作比较复杂。下面的代码实现了交叉函数。
genetic.crossover = function performCrossover(motherArray, fatherArray, child1Array, child2Array) { // 染色体(此处泛指遗传特性)必须在两个位置被切割,并确定他们。 var cutLength = motherArray.length / 5; var cutpoint1 = Math.floor(Math.random() * (motherArray.length - cutLength)); var cutpoint2 = cutpoint1 + cutLength; // 记录这两个子代中每一个染色体中所带的基因,默认为false var taken1 = {}; var taken2 = {}; // 处理削减的染色体部分 for (var i = 0; i < motherArray.length; i++) { if (!((i < cutpoint1) || (i > cutpoint2))) { child1Array[i] = fatherArray[i]; child2Array[i] = motherArray[i]; taken1[fatherArray[i]] = true; taken2[motherArray[i]] = true; } } // 处理外部的染色体部分 for (var i = 0; i < motherArray.length; i++) { if ((i < cutpoint1) || (i > cutpoint2)) { child1Array[i] = getNotTaken(motherArray,taken1); child2Array[i] = getNotTaken(fatherArray,taken2); } } };
上面代码的原理如下:在城市的道路上取两个“切点”,这就意味着把父本和母本的特性都各自分割成了三份,父本和母本有着相同的切点。这些切割的规模是随机的,然后通过交换父辈的三份来创建两个子代。例如,观察下面的父本和母本。
[m1, m2, m3 ,m4, m5, m6, m7, m8, m9, m10]
[f1, f2, f3 ,f4, f5, f6, f7, f8, f9, f10]
现在我们将这些切点加进去。
[m1, m2] [m3 ,m4, m5, m6] [m7, m8, m9, m10]
[f1, f2] [f3 ,f4, f5, f6] [f7, f8, f9, f10]
如此会产生下面两个子代。
[m1, m2] [f3 ,f4, f5, f6] [m7, m8, m9, m10]
[f1, f2] [m3 ,m4, m5, m6] [f7, f8, f9, f10]
根据另一个随机事件,每个解决方案都可能会发生突变。突变就是将“新产生的信息”添加到种群遗传的过程。否则就是简单的传递已经存在的遗传特征。
XOR神经网络
神经网络是另外一种基于生物学的机器学习方法,它非常松散地建立在人脑的基础上。神经网络是由神经突触连接的神经元组成的,每一个突触本身都具有权重,众多突触的权重构成了神经网络的记忆。如下所示的神经网络示意图。
图 7:一个神经网络

如图所示的结构,其实就是我们下一节要创建的神经网络,你可以在上面的神经网络中看到有一个输入层和一个输出层。神经网络接收来自输入层的刺激,并交由输出层进行相应输出。神经网络内部也可能存在隐藏层,该层中同样包含有神经元。隐藏层也有助于信息的处理。XOR神经网络(异或神经网络),有两个输入和一个输出。两个输入端接收布尔值(0或者1),输出神经元也输出布尔值。其目的就是让神经网络实现和XOR(异或运算)操作符相同的功能。
0 XOR 0 = 0 1 XOR 0 = 1 0 XOR 1 = 1 1 XOR 1 = 0
当两个输入不一致时,异或XOR操作符的输出必为1。
你可以在下面看到异或XOR的示例输出。
Training XOR with Resilient Propagation (RPROP) Training Iteration #1, Error: 0.266564333804989 Training Iteration #2, Error: 0.2525674154011323 Training Iteration #3, Error: 0.2510141208338126 Training Iteration #4, Error: 0.2501895607116004 Training Iteration #5, Error: 0.24604660296617512 Training Iteration #6, Error: 0.24363697465430123 Training Iteration #7, Error: 0.24007542622000883 Training Iteration #8, Error: 0.23594361591893737 Training Iteration #9, Error: 0.23110199069041137 Training Iteration #10, Error: 0.22402031408256806 ... Training Iteration #41, Error: 0.0169149539750981 Training Iteration #42, Error: 0.012983289628979862 Training Iteration #43, Error: 0.010217909135985562 Training Iteration #44, Error: 0.007442433731742264 Testing neural network Input: 0 ; 0 Output: 0.000005296759326400659 Ideal: 0 Input: 1 ; 0 Output: 0.9176637562838892 Ideal: 1 Input: 0 ; 1 Output: 0.9249242746585553 Ideal: 1 Input: 1 ; 1 Output: 0.036556423402042126 Ideal: 0
正如上文所示,它用了44个迭代训练来教神经网络执行XOR操作,神经网络的初始化权重是从随机数字开始的。数据训练的过程中会逐渐调整权重,以产生期望的输出。神经网络的随机部分是权重的初始化量值。除了这些,神经网络是决定性的。给定相同的权重和输入,神经网络始终会产生相同的输出。
在上面的输出中,你可能会注意到输出的结果并不是非常精确的。因为神经网络永远不会为1的输出精确到1.0。由于开始的权重是随机的,所以你不可能从这个神经网络中得到两个相同的结果。另外,由于一些随机的初始化权重量值是完全不可训练的,正因如此,有时你会看到XOR神经网络达到了5000的最大训练值,然而就还是放弃了。
你可以在下面URL中看到这个案例的运行实例。
http://www.heatonresearch.com/fun/ann/xor
我们现在来观察这个程序是如何构建的。首先,我们创建输入和理想输出。
var XOR_INPUT = [ [0,0], [1,0], [0,1], [1,1] ]; var XOR_IDEAL = [ [0], [1], [1], [0] ];
上面的两个数组分别包含了输入和理想输出。这个“真相表”将被用来训练神经网络。
接着我们来创建一个三层神经网络。输入层有两个神经元,隐藏的神经元有三个,输出层有一个神经元。
var network = ENCOG.BasicNetwork.create( [ ENCOG.BasicLayer.create(ENCOG.ActivationSigmoid.create(),2,1), ENCOG.BasicLayer.create(ENCOG.ActivationSigmoid.create(),3,1), ENCOG.BasicLayer.create(ENCOG.ActivationSigmoid.create(),1,0)] ); network.randomize();
创建和随机化神经网络的时候,将会调用随机化函数将权重填充为随机值。
训练神经网络有很多不同方法,对于本例,我们会采用RPROP(一种基于弹性反向传播的神经网络算法原理)来实现。
var train = ENCOG.PropagationTrainer.create(network,XOR_INPUT,XOR_IDEAL,"RPROP",0,0);
现在,我们将通过迭代训练进行循环处理,直到出错率降到可以接受的水平线以下为止。
var iteration = 1; do { train.iteration(); var str = "Training Iteration #" + iteration + ", Error: " + train.error; con.writeLine(str); iteration++; } while( iteration<1000 && train.error>0.01);
现在神经网络的训练已完成,我们将对输入数组进行循环处理,并将其提交给神经网络。神经网络会显示出对应输出。
var input = [0,0]; var output = []; con.writeLine("Testing neural network"); for(var i=0;i<XOR_INPUT.length;i++) { network.compute(XOR_INPUT[i],output); var str = "Input: " + String(XOR_INPUT[i][0]) + " ; " + String(XOR_INPUT[i][1]) + " Output: " + String(output[0]) + " Ideal: " + String(XOR_IDEAL[i][0]); con.writeLine(str); }
这是对神经网络的一个非常简单的介绍,我还做了一个关于Java和C#神经网络内容,你如果只对神经网络感兴趣,下面的内容应该会有所帮助。
- <ahref="http:>Introduction to Neural Networks for Java
- <ahref="http:>Introduction to Neural Networks for C# </ahref="http:>
此外,如果你想了解神经网络的基本介绍,下面的文章可能会对你有用。
http://www.heatonresearch.com/content/non-mathematical-introduction-using-neural-networks
神经网络分类
现在我们来看一个稍微复杂些的神经网络分类,这个神经网络将会学习如何进行分类。我们会学到神经网络是如何通过训练数据集来学习对数据点进行分类,并且能够对训练数据集中不存在的数据点进行分类。
你可以在下面的URL中在线运行这个示例代码:
http://www.heatonresearch.com/ann/classification
本案例将利用前馈神经网络原理进行分类。为了充分利用这个程序,我们在画图区域绘制了几个彩色点。必须保证你至少有两个彩色点,否则程序就无法进行分类。一旦你开始画点并且点击begin(开始),则神经网络也就开始训练了。你将看到你提供的数据点附近的其他区域是如何进行分类的。
上一个神经网络案例有是两个输入神经元和三个输出神经元的。隐藏层的结构是由drop列表决定的。举例来说,如果你选择了2:10:10:3,你将会得到一个与以下图像相似的网络,这个网络有两个隐藏层,每层有10个神经元。
输入神经元代表一个点的x坐标和y坐标。为了绘出上面的图像,该程序在x坐标和y坐标的网格上进行循环处理。每个网格组件都会对神经网络进行查询。左上角的细胞是[0,0],右下角的细胞坐标是[1,1]。对于具有sigmoid(常用的非线性激活函数)激活函数的神经网络数据,通常可以在0到1之间的范围内接受输入,因此这个范围的表现良好。中心点是[0.5,0.5]。
神经网络的输出即正方形中像素点的RGB颜色值。[0,0,0]表示黑色,[1,1,1]表示白色。当你在绘图区域画点时,就等同于在提供训练数据。输入神经元将会根据你输入的数据训练出放置x坐标和y坐标的方式。期望或者理想中的输出应该是与你在该位置选择的颜色近似一致。
让我们来看一个简单的案例。如果你只画出两个数据点,那么这个区域就会被分割成两部分。如下图所示,你可以看到一个红色的数据点和一个蓝色的数据点。
图 8:两个数据点的分类

该算法为了让应用程序得到的错误评级比较低,它仅需要保证蓝色数据点位于蓝色区域,而红色数据点位于红色区域。其他所有像素点都是基于已知像素点的“猜测”。但由于这样已知的数据非常少,所以神经网络很难真正猜到这两个区域之间的边界到底在哪里。
如果你提供了更多的训练数据,那你会得到一个更加复杂的形状。如果你选择创建一个双色的随机图像,那你会得到与下图类似的数据点。
图 9:多个数据点的分类

在此图中,神经网络创建了一种更加复杂的模式试图来适应所有的数据点。
你还可以选择创建一个复杂的多颜色模式。下面的案例中为数据点随机生成了颜色值。神经网络甚至会将颜色进行混合,试图做出妥协,以此来尽可能地降低误差。
图 10:多颜色数据点分类

此算法甚至有可能学习复杂的相互螺旋的形状,如下图所示。
图 11:螺旋数据点的分类

延伸阅读
本文介绍了JavaScript中的机器学习,如果想了解更多关于机器学习的知识,那么你可能会对下面的链接感兴趣。
历史
2012年10月16日的第一个版本,引用文件版本 Encog JS v1.0